Alex Lawsen on Forecasting AI Progress
Alex Lawsen is an advisor at 80,000hours, released an Introduction to Forecasting Youtube Series and has recently been thinking about forecasting AI progress, why you cannot just update all the way bro (discussed in my latest episode with Connor Leahy) and how to develop inside views about AI Alignment in general.
(Feel free to click on any sub-topic of your liking in the outline below and then come back to the outline by clicking on the green arrow ⬆)
Contents
- Introduction
- How To Actually Forecast AI Progress
- How Alex Developed Inside Views About AI Alignment
- Additional Resources
Introduction
Michaël: Who are you? Why are you are?
Alex: What am I doing in your podcast space?
Michaël: What are you doing here? Where are we?
Alex: [laughs]
Michaël: We’re in California. You’re an advisor at 80k. You talk to people about their careers. You also made some cool videos about forecasting.
Alex: Yeah, thanks. I’m glad you thought they were cool.
Michaël: Yeah. I think that’s how I got into forecasting, I just watched your videos.
Alex: I actually didn’t know that. Thanks, that’s really nice to hear. ⬆
How Alex Ended Up Making Forecasting Videos
Alex: I was a teacher at the time, I was teaching math and physics in a high school in the UK. And COVID happened, and so I was teaching remotely for it, which sucked. And some things I did for some lessons was make little videos of the thing I would explain anyway. So, I had a webcam set up and was thinking about it a bit. There didn’t seem to be any videos on forecasting, so I made some. And I think they’re kind of terrible, but… Well, I don’t know, I’m happy with the content, I think the content’s good. And then I think everything else about them is bad, but no one’s made any others.
Michaël: Would you want other videos about forecasting to be made on YouTube?
Alex: Yeah, I think it’s actually a real shame that it seems my stuff is the best. And I’m saying that because it basically seems my stuff is the only stuff. So, I’d be really psyched for someone to take the content that I produced or improve on the content I produced, and then really improve on all of the other stuff.
Michaël: What kind of thing we can do to improve?
Alex: I don’t know, man. You’ve got a better YouTube channel than I have. I think I did everything wrong, I had a fairly cheap webcam, I had pretty bad lighting, the audio quality was terrible. And given that I love podcasts and listen to a whole bunch, including yours-
Michaël: Thanks.
Alex: I know how much audio quality matters. And the fact I just didn’t sort it out at that time, seems probably a pretty big mistake in retrospect.
Michaël: To be frank, when I watched the videos, I didn’t really care about audio or video quality. I was just interested in your takes, so I think the content is maybe most important part.
Alex: It’s probably true, but I think most important conditional on someone deciding to watch it. And then, I think it’s one of the things that’s cool about forecasting, is you can practice it a bit and you can just get a decent bit of low-hanging fruit straight away. It’s just about making better judgements in general. And so, sure, the people who have decided to practice might watch the videos, but there’s been 5000 views on the first one or something. And I think there are tons of people who could benefit from doing a few hours forecasting practice, loads more than that. ⬆
Why You Should Try Calibration Training
Michaël: Yeah. So, I think one of the first things in the video is trying out The Good Judgment Project forecasting calibration.
Alex: Yeah, I think it’s not Good Judgment. I think it’s Open Phil that made it.
Michaël: Yeah.
Alex: But yeah, I liked that tool when I found out about it. And then one of the videos is Semi-Life and I was pretty happy to put up something where I really embarrassed myself by not knowing anything about geography. But I hoped by saying, “Look, it’s a painful process to go through, but you come out the other end of it better at predicting.”
Michaël: Can you explain what’s Semi-Life for people are not familiar?
Alex: Yeah. So, the idea is you… It’s a game where you just have to answer a bunch of trivia questions, some of them are about geography. There’s one that’s like, “Here’s some data, how strong is the correlation?” There’s other ones. And you also have to say how confident you are in your answer. And this happens in different formats, but basically, you can then see when you were really confident like, “Were you right a lot of the time?” and when you are not so confident, “Should you have been more confident?” And this is just a pretty useful exercise to have hit you in the face really hard, that maybe when you are really sure something’s going to happen, you shouldn’t be. And obviously, for some people vice versa, which is also nice for them to know.
Michaël: Yeah. I think one thing you say is that when you’re 99% confident or 90% confident… It is very hard to be 99% confident. So, even if you think you’re probably sure that something happened, I don’t know, in 1945, you are sometimes wrong. And so, people end up saying that there’s something that happens with 99% confidence too often.
Alex: Yeah. I think I didn’t want to make a claim about other people. But yeah, one of the biggest mistakes I noticed when I first did it was… “As sure as I can possibly be,” was about 95%, or empirically, it was about 95%. And most of that other 5%, was I’d misunderstood the question or misread the question or predicted one minus the actual probability or something like that. For what it’s worth, I think I’m slightly better than that now. I think, my “I’m 100% sure about something,” like a trivia question now, probably translates to closer to 97, 98. But at the time, I just empirically was getting just sort of colossal mistakes about 5% of the time where I just didn’t really understand what I was talking about.
Michaël: Yeah. I think the problem comes from unknown-unknowns or not knowing some words in English or…
Alex: Yeah, I think… So, not knowing a word… If I didn’t recognize a word, this would be enough for me to be less confident than 99%. I think it’s just… I actually can’t think of an example now, but yeah, I don’t know. Everyone’s had the experience of reading a sentence and just interpreting it, and it’s not actually the sentence that got written.
Michaël: Right. And the thing about being under or over confident is kind of visual when you have the… Is it the Brier Score curve or just the accuracy curve for different bins?
Alex: Yeah. I think this is a… I don’t know, I think I would call it a calibration plot or calibration graph.
Michaël: Right.
Alex: Yeah, it doesn’t have anything to do with Brier Score. But yeah, the idea is you’ve made a bunch of forecasts between 50 and 60%. Hopefully, the number of times they came true was somewhere between 50 and 60%. And certainly, when these things are miles away from each other, noticing it visually is just way easier than trying to keep track in your head of all of the things you’ve said you’re confident in.
Michaël: And then you can adjust and you think, “Oh, whenever I say 60%, actually, I mean 70%.”
Alex: Yeah. I think I never actually did adjustment that specific apart from in the 100% percent confident case where it’s like, “Okay, I just need to have an insanely high bar to ever go higher than 95 or below five.” I know some people do that, and I think there are some aggregation algorithms. At least one version of the Metaculus algorithm, I think, explicitly tried to adjust for this with different forecasters.
Alex: So, if some forecaster had empirically been under confident at 50%, it would take their forecast and shift it up a bit before it put it into the average. I didn’t do that myself. Actually, I was relatively well calibrated by the time I finished the thing. But I think the reason I got better calibrated was doing something like that but more subjective, it’s more just like, “Oh, I feel about this sure.” I actually just… Empirically now, I’m pretty good at going, “I feel about this sure. Oh, that’s 70%,” or, “I feel about this sure, that’s one in three.” ⬆
How Alex Upskilled In Forecasting
Michaël: It seems you were actually already pretty good when you started doing the video. How did you get good to begin with?
Alex: Yeah, this is an awkward question or something, because I still don’t really think I’m very good at forecasting, but there’s enough data to say that I’m at least not terrible. I think there are a couple of things. So, I was a math and physics teacher at the time. I’m pretty well versed in, at least, the level of statistics you need to be good at forecasting.
Alex: I also played poker for nearly a decade, not ever full-time professionally, but very seriously while I was at last couple of years of school and then at university and then at my first few years in a job. And so, yeah, I think there’s an effect of just seeing luck again and again, just seeing hands play out, seeing situations go the 5% of the way or the 10% of the way. And in that case, I can explicitly calculate all probability, so I pre-calculated most of them. When you just see 20,000 rolls of dice of different sizes, you just do get an intuitive sense. So, I think was partly that. What I actually did was read Superforecasting and then think a bit, and then just do a bunch of practice. There wasn’t a formal training program I used or anything.
Michaël: How do you practice?
Alex: I made a bunch of forecasts, and this is the main thing my video series says again and again. If you want to get good at doing a thing, you’ve just got to actually do it a bunch and you’ll suck to start with and then you’ll get better.
Michaël: I know right now we have Metaculus to predict things. But before Metaculus, because it’s quite recent, right, did you do forecast things about some events or stuff online?
Alex: Oh, I started forecasting only a few months before I made those videos. Maybe it was overconfident of me to say, “Right now, I can teach this,” but I don’t know. I, at that point, had been teaching for seven and a half years or something and I knew I was pretty good at helping people get to a level that’s pretty close to me. Most people are able to teach something up to some level that’s less than their ability. And I think the difference between the ability I can get to and the ability I can teach to, is probably unusually small. So, I started forecasting on Metaculus around about the start of the pandemic and I think I made the videos in September or October of 2020.
Michaël: How did you find predicting in Metaculus? Was it mostly COVID stuff at the beginning or did you predict AI things or other events?
Alex: I think it was a lot of COVID, and I think I got somewhat lucky. The world, including me, got unlucky with COVID existing, but I think that there was just a bunch of data and there was a bunch of interest and there were lots of smart people commenting. And so, you get up in a bit of a hype cycle and there was a lot of motivation there. And then other than COVID, there was a time when I was just making a lot of predictions. I never really tried the Jgalt or SimonM strategy of literally “predict on every question”, but I was like, “Predict.” I was into it, it was exciting, it was fun, so I predicted on a lot. And then I wrote a video, I wrote an introductory series for other people to get into it and I predicted all of the questions in the series, obviously.
Michaël: Yeah. That’s one thing you do in the series is you take some specific questions. I remember one about Tokyo Olympics, “Will they be held in 2024 or not?” or something like this. And then maybe, can you explain the different methods for this kind of forecasting? I think I remember one about having a Guesstimate model where you have different parameters.
Alex: Yeah. I think I’ll, I don’t know, flag very high level ideas, but then… I’ve got a video series than this, so you can just go and watch that. Maybe I’m going to point to a random thing because I know that’s what YouTubers do, and then maybe there’ll be a box that appears.
Michaël: Yeah, just… Sure.
Alex: Yeah. So, that thing is… You can do Fermi estimation. This is a thing you can look up, lots of people have written about it, lots of physicists like it. And Guesstimate is a really cool piece of software built by Ozzie Gooen, which lets you do Fermi estimation and a bunch of other stuff. Other things I used were… I explained what reference class forecasting is and I think if you are going to learn to forecast, you should understand reference class forecasting, and then you should deviate from it once you know how to use it. But that’s a decent starting point.
Alex: And there’s a couple other things. I think I did some… I’m mixing it up in my head, actually. I did the video series and I also taught a bunch of workshops and taught a bunch of classes for some of my students. But there are some other things I do, which are more intuition-based ways of thinking about things and ways of framing things which helped me. But the basics is reference class forecasting and Fermi estimation.
Michaël: Hopefully, there will be a nice way to look at your videos with a video here or there.
Alex: We’ll try, or we can just cut the pointing. ⬆
Why A Spider Monkey Profile Picture
Michaël: And I remember your profile picture on YouTube, or at least on Twitter, is a spider monkey.
Alex: Yeah.
Michaël: Why is that?
Alex: Oh, yeah. So, the channel’s called Dart Throwing Spider Monkey, and my profile picture on Twitter for ages was this same photograph of a spider monkey, though now it’s a DALL-E generated version. This is because when I was 16 or 17, and first started playing poker, I somewhat randomly picked a photograph of a monkey that I liked. I like monkeys, I like climbing. Monkeys are cool. And it’s screaming, it looks like it’s freaking out or something. And I had some hypothesis that this gave me a tiny bit of additional edge when I was playing because when I was winning a lot, the idea that people were being beaten by a crazy monkey would wind them up. I just got attached to it.
Michaël: When you were winning at poker, you had this monkey as your avatar?
Alex: Yeah. Well, also when I was losing, I still… ⬆
How To Actually Forecast AI Progress
Michaël: Yeah. I think now COVID is mostly over, so there’s other things to predict. One thing that people like to predict is artificial general intelligence and this-
Alex: I love that transition. So smooth.
Michaël: So smooth.
Alex: What’s the name of this podcast?
Michaël: The Inside View, on people’s inside views about Artificial Intelligence.⬆
Why You Cannot Just “Update All The Way Bro”
Michaël: The last episode, maybe it will be two episodes before, I don’t know, depending on when I publish this, was with Connor Leahy, on how he updated on recent progress. That was one of the things. And I guess one claim was that if there were some events that always went into the same direction… For instance, scaling transformers led to increased performance and decreasing loss with no diminishing returns, the same rate of the loss diminishing.
Michaël: Then when you see the first evidence or at least the three or four first evidence, you can just consider the trend will continue the same direction. If you’re always surprised a little bit, then you can just decide to be a little bit more surprised and update more, doing Bayesian updates more strongly in some direction. And he said, “Just update all the way, bro.” So, yeah, what do you think about that? Have you seen this video?
Alex: Yeah. So annoyingly, I haven’t finished listening to your interview with Connor yet, so I didn’t actually get to this bit. But yeah, I think there are a few ideas that… These ideas are not just Connor’s, right, people have been talking about this sort of thing in a bunch of contexts, especially on Twitter. And I think maybe it’s worth pulling apart a few things here. So, one thing is if you notice that you are always surprised in the same direction, you should at least check why that is. It’s possible you’re miscalibrated. There are other explanations.
Alex: I think in particular, there are some situations where all of the positive evidence you get is going to be in the same direction, and then the negative evidence you get is nothing happens. And so, ideally, what you do in this case is every day that nothing happens, you make a tiny update in one direction. And then every few weeks or every few months, something big happens and you make an update in the other direction and then you get this kind of [saucy 00:16:23] thing going.
Alex: And if that is the case, maybe what you’ll see is people just… they forget to do the small downwards updates and then they do the big updates every time something happens. And I think if you do the Connor thing of seeing… Well, I’m not too sure this is the Connor thing. But if you see four updates and they’re all in the same direction and then you go like, “Oh, man, everything’s going the same direction. I need to be really confident stuff going that direction.” Then every day something doesn’t happen, your downwards update needs to be pretty big. If you’re expecting massive progress, then a week going by and nothing happening, is actually big evidence for you. So, yeah, there’s something there. Do you want to say about a different part of that? Because I think there’s five different ideas here.
Michaël: Oh, what kind of different idea?
Alex: Yeah. So, there’s another thing which is… maybe if you see a forecast plot… So, if you look at Metaculus and you notice that there is a sort of line going in one direction… I think there have been people who’ve looked at this and gone, “Okay, well, the line’s going in one direction, so I’ll just look where the line’s going and I’ll get ahead of the crowd by predicting that,” and sometimes this is actually correct. Sometimes, the community is just slow to update or whatever, but there are other times where every day you wait is some negative evidence.
Alex: And so, that means you should actually just be making a smooth update down and at some point, the forecast ends. But yeah, let’s just say if you’ve got, “Is…” like, “Are you going to release your 100 episodes in the next 100 days?” Every day that goes past, you’re less likely to make the goal by the end of the 100 days. If there’s one day left, you’re almost zero, likely. If there’s zero days left, you are zero, likely. So, you should expect this smooth thing down and you can’t go, “Oh, wow, the first 10 days, we’ve had to update down every day. I’d better update all the way, bro, and go to zero straight away,” there’s no way he can do it.
Michaël: Well, if I published one video every day or twice a day for a week, then you might want to update to the thing happening.
Alex: Yeah. That’s just good forecasting, right? Yeah, so if you’re in this… yeah, maybe this is a nice example. If you sit down and you’re like… Maybe on the first day, you post two videos and you’re like, “Wow, I’m surprised. It’s going really fast.” And then the second day, you post another two videos and you’re like, “Wow, I’m surprised it’s going really fast.” On the third day, you should not be surprised if you post two videos. But that’s not forecasted particularly updating in the same direction, that’s just… now your reference class is, “Michael produces two videos a day.”
Michaël: Yeah. And the estimate is probably 50 days to get to 100, right?
Alex: Yeah.
Michaël: Yeah. I think on Metaculus, what happened was the median for the day, for weak AGI… So, it’s like a-
Alex: Yeah. ⬆
Why The Metaculus AGI Forecasts Dropped Twice
Michaël: Less restrictive definition. And then another question about just AGI, not the weak AGI… I think the median was something around the lines of 2040-ish [Note: it was actually October 2042 in April 2022] or maybe 20… I don’t actually remember. And after some breakthrough, I think it was PaLM, DALL-E, Chinchilla. I don’t remember those ones-
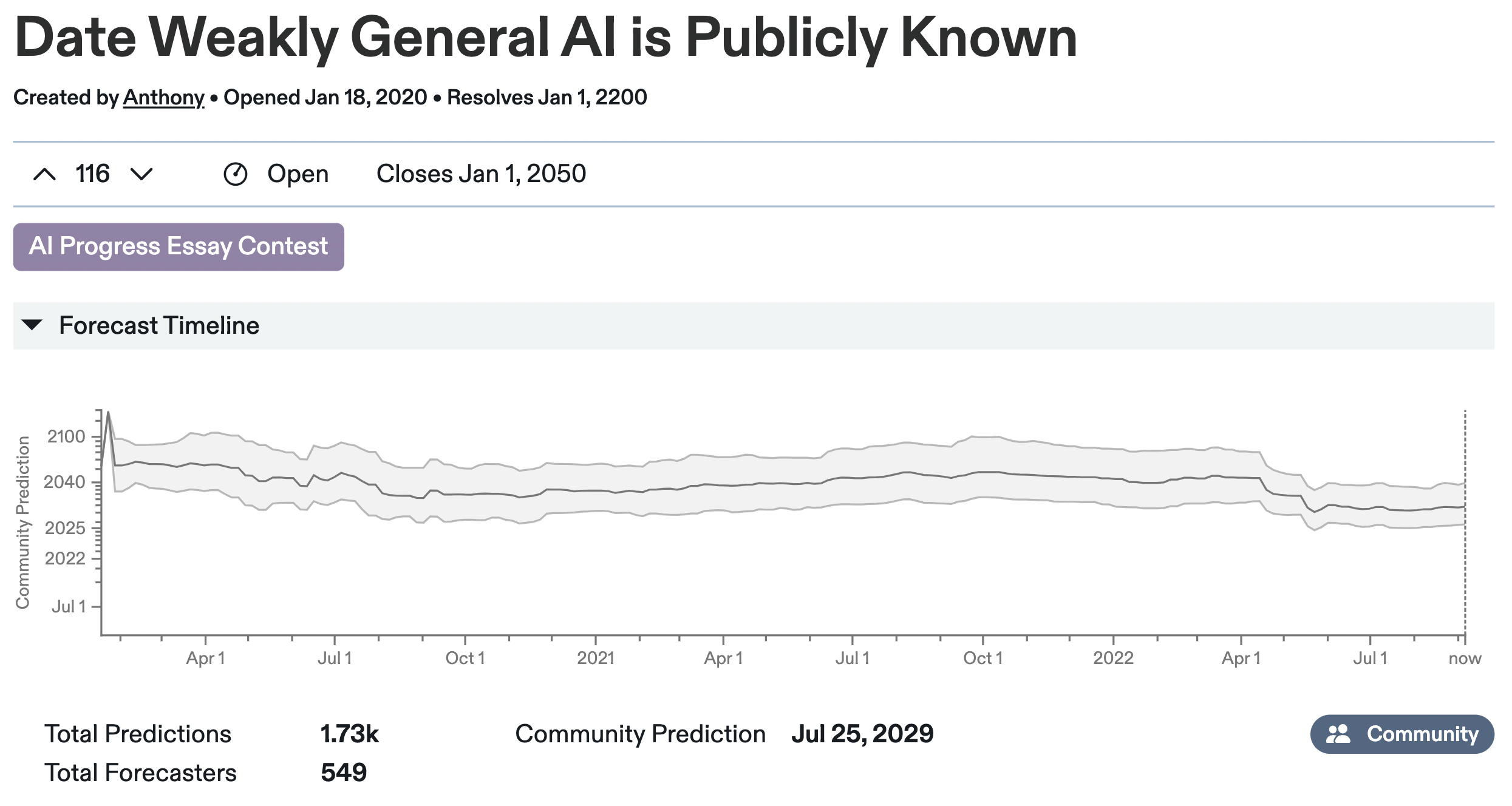
Alex: I think the first one was PaLM and Chinchilla and Socratic models and maybe something else, all happened within maybe a week of each other or two weeks of each other.
Michaël: And I guess, Metaculus, the median dropped by five to 10 years in this two or three weeks [Note: It was actually 5 years for the first drop, 15 years total since April 2022]. And maybe there was another breakthrough and it also went down five years, I don’t… Maybe in a month, there were two busy weeks. And for those two busy weeks, there was a drop.
Alex: Yeah, I think Gato was the second one. I think Gato was a big update on Metaculus as well.
Michaël: And so, if I remember correctly, the Metaculus prediction had those two drops. And right now, it went a little bit more up maybe because there’s not much of evidence or people are updating up… I don’t know, they’re just thinking, “Oh, maybe we went too hard on those kind of things.”
Alex: Yeah, I suspect it’s closer to the second thing. So, I think there’s a couple of things here. One hypothesis you might have which I think a friend of mine falsified, is a whole bunch of people saw these results. These results were all over Twitter, it was impressive. Chinchilla was impressive, PaLM was impressive. So, you might think, “Oh, well, a bunch of new people who haven’t made timelines forecasts before are going to jump on this Metaculus question and they’re going to make predictions.” And so, you can test this, right, you can look at how the median changed among predictors who had already predicted on the question and that median dropped too. I can’t exactly… My guess is it was Simon M who… Oh, are you looking at the question now?
Michaël: Yeah. So, I think it was at 2042 median, Metaculus prediction in February. Then there was a first drop and it went to something like 2034, 2026. And the second drop, when it was like, “2029 or 2030.”
Alex: Has it come back up?
Michaël: So, I don’t think so.
Alex: Yeah, it hasn’t, really.
Michaël: I think it was for, maybe, the other one.
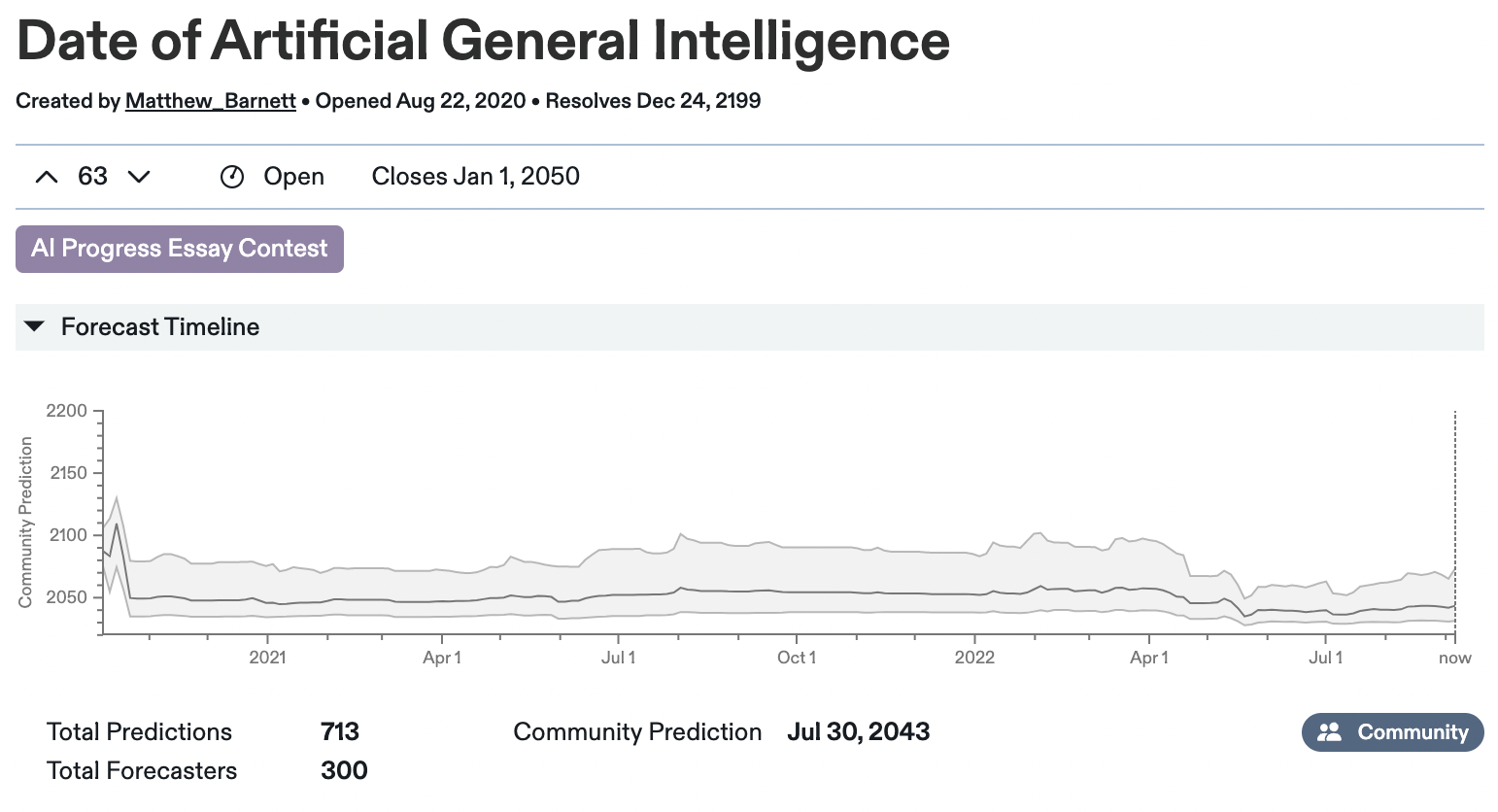
Alex: Yeah, maybe the stronger general AGI one went back up. So, yeah, we’ve got these two drops and I’m pretty sure someone… and my guess is Simon M, because he’s done stuff like this before, checked, “Was it original predictors also updating?” And the answer that is yes. So, what’s going on here? I think a lot of forecasters are bad and you see a bunch of Twitter hype about timelines suddenly being short and you go, “Oh, crap, I haven’t updated my Metaculus prediction in five months. Maybe I should just shade it down a bit because everyone else is.” Yeah, I think Metaculus is like-
Michaël: “Oh, no Metaculus points.”
Alex: Or I think it’s just… I don’t know, it’s a better source of truth than most other sources of truth. That doesn’t mean I think it’s good. It’s just… forecasting’s hard, especially forecasting stuff like this. So, yeah, I think that’s one thing that happened or that’s one thing that didn’t happen. It was actually the case that people who were there before predicted down, but I’m not sure they were making a sensible update or something. Yeah.
Michaël: Yeah, and maybe one part of it is that we’re talking about mostly the median prediction and people talk about it a lot, but there are other kind of characteristics of distribution in forecasting that are important. I think one other thing is the peak of your distribution.
Alex: Yeah.
Michaël: And yeah, if you have short timelines and you put a lot of mass on 2025 or 2030, then maybe the median is not the most important part. It’s more like, “Where is your mass mostly distributed?”
Alex: Yeah, we were talking about this the other day. So, I think there is a thing where when people try to make a forecast, often they’ll do something where they kind of think about what’s most likely or whatever. They just kind of try and imagine a picture in their head and they go like, “Oh, yeah, this are happening then. I’m kind of least surprised if it happens then.” And often this is fine, lots of things look kind of like a normal distribution, even things that don’t necessarily obey the theorems which show in the limit you’ll get a normal… Lots of things are just kind smooth and kind symmetric. Timelines aren’t, right, because you can’t have some probability on… we’ve already got AGI.
Alex: And so, when you have really short timelines and you think that you still have some weight on 2100 or whatever, then you get this really skewed graph where the peak is quite a lot before your median. And at least I claim people are often thinking, “Oh, when’s ‘most likely’?” And they think, “Oh, 2028 seems like most likely,” or whatever. I don’t, I have got longer time in that, slightly.
Alex: But I think if people go, “I think the most likely time is this. So, that’s my median,” they’re kind of forced into this situation where they then have to have a peak a few years earlier. And if they’re potentially halfway between now and when their actual most likely thing is… So, I think there’s… it’s important to know that you’ve got a median and you’ve got the thing you think is most likely, but the more skewed your graph is, the further apart these are.
Michaël: Why should the peak be before median? Because if you have some weight for 8 decades after your median, then you need to have your peak before. Because if the peak was after, then you will have nothing on the left or something.
Alex: Yeah. If you think about drawing a probability distribution, the median is the point where there’s equal area on each side. And so, “How do you get equal area on each side?” If one of them can just be way further out than the other, you just need to have… it needs to be higher up on the left. ⬆
How Alex’s AI Timelines Differ From Metaculus
Michaël: Yeah, it makes a lot of sense. Would you be open to discussing your distribution? Or at least, how do you think about those things? How do you go and draw a distribution for those kind of things?
Alex: Yeah, I can discuss it a little bit and I think you probably won’t be that interested. I actually haven’t in the last few months, formally sat down and come up with the distribution. I haven’t predicted on either of the Metaculus weakly general and strongly general AI questions. When I… There’s videos I have on how I made probability distributions in general. I think when I’ve been thinking about AI timelines, I think it has mostly been in the context of a sort more general exercise I’ve been doing of trying to get an understanding of what different people think in the space and then from that, getting my own picture. So, I can talk about that a bit, but I think that’s it. I actually just… I will admit, and as a forecaster, this is a shameful thing to admit, but I actually haven’t sat down and put a bunch of numbers on things for quite a while.
Michaël: You said before that your timelines were longer than the people on Metaculus going down. Do you mostly agree with the Metaculus prediction or are you more bullish or more bearish on AI?
Alex: The weekly general one was 2028.
Michaël: Yeah. 2029, 2028.
Alex: 2029, 2028. I don’t have loaded up in my head exact resolution, but my guess is I’ve got slightly longer timelines than the weekly general one. And yeah, I think it depends exactly how you define it, but most definitions of AGI that are at all plausible… Most definitions are transformative AI that are all plausible happen. My median’s after 2035, and most of them are close to early 2040s, but this is with very high variance or something. It’s totally plausible for me to sit down for five hours and think about this and go a decade in either direction.
Michaël: Do you think scale is all you need?
Alex: I suspect scale is not all you need, but I have some thoughts on very small adjustments to scale, which then might be… I have one specific… There is a minimal adjustment to scale, which I then think might be all you need.
Michaël: So, would it be something like a new model and new architecture?
Alex: It is a very slight adjustment to the transformer architecture. ⬆
Maximizing Your Own Impact Using Forecasting
Michaël: Interesting. Maybe we can move on to forecasting other things. I think you mentioned that you could apply those forecasting techniques for thinking about jobs or career.
Alex: Yeah. So, yeah, I think maybe there’s a median or there’s, “What’s the mode? And what’s the thing you should care about?” thing in jobs as well, which I end up talking to people about quite a lot. So, for a lot of the careers I talk to people about… Maybe this is a sensible time to point at the thing again and go, “Hopefully, we’ll be able to put in something that says, ‘You can ask to come and speak with me and we can talk about jobs.’”
Michaël: Okay.
Alex: Yeah. So, for a lot of the jobs I talk about, I expect the distribution of impact to be pretty heavy tailed. So, I expect that a lot of the reason to be excited about those jobs is contained in the set of cases where things go really well. And that leads you to be making a fairly big mistake if you do the thing before, where you go, “I want to find the mode,” or, “Oh, I’m going to think about what seems most likely, what seems pretty likely.” And I don’t know if you’ve thought about jobs or maybe… Yeah, how do you think about how well this podcast would go? Did you think about what seems the most likely outcome here?
Michaël: I feel it’s a therapy session or a… Yeah, I think I saw the video with Ethan Caballero and I saw the ratio between people liking the video and disliking the video and the watch time. And I thought, “Oh, yeah, people really seem to care about scaling or AI in general,” and I thought that there was a big audience for this. I thought that the distribution for when such topic might be interesting for people on YouTube, might be skewed towards 2025, 2030. And if I start doing it now, it might be relevant when we actually have something closer to AGI.
Michaël: So, if you have short timelines and you think people will start to care about AI in around those years, 2025, 2030, you might want to have most of your impact between 2025 and 2030, when people might change their careers and have more thoughts on what is the most useful way to work on AI alignment or AGI in general. So, I guess that’s kind of the thought here, is maybe you do something for a few years where you’re just growing and then when you’re at Lex Fridman level, then you can just have an impact.
Alex: Yeah. I actually kind of like this, I have an article called Know What You’re Optimizing For, which gives some advice on some other areas which is not miles off this. I actually think it’s somewhat unusual. The thing you’re doing here, which I think is good, is you’re kind of going, “What impact do I have when this goes really well?” And probably, you don’t put that higher probability on actually going really well, you should be at least somewhat humble. But you know it could, you’ve got some chance of it going well.
Alex: And I think that’s often a really good model to have, but it’s not a particularly normal one. Most people go, “What should I expect this to look like?” And the problem is if most of the impact is contained in the tail, it’s contained in the cases where it does go really well, comparing options based on what they probably look like… so, what the mode outcome is, might just give you a very different ranking.
Michaël: So, I think for those kind of things, it’s good to try different things before. I’ve tried stuff for engineering, I’ve tried AI research, I’ve tried ops for a CEO, and I realize that it’s just very fun to do stuff on your own schedule and talk to very smart people like you. And I guess for me, it’s also low effort. So, I just sit in front of you, have you talk for an hour and I don’t really have to do research to write a paper for NeurIPS. I just need to talk to people, right? So, I guess most of the effort is just putting those cameras together, sitting in front of smart people and have them talk. So, I guess it’s just a low hanging fruit in some way that there’s not enough people doing this, I guess, in this AGI space.
Alex: Yeah. I guess I should shout out Daniel Filan right now because I think he’s doing a really good job of this.
Michaël: Sorry, yeah, Daniel Filan is great. Rob Wiblin is great. Lex Fridman does some AGI videos, but he doesn’t talk about alignment enough. There is… Here’s an idea that you people should watch and…
Alex: Yeah. To be clear, I agree with the claim that more people should be doing stuff like this. Yeah, there are some other people in the space. I think noticing that you have a comparative advantage somewhere seems pretty good. So, I think there are a bunch of people who would hate being on camera, and there are a bunch of people who would get to sit in front of a person who seems really smart. And I’m happy to imagine I’m talking about your other guests here, not me, and feel really intimidated by that or something.
Alex: So, I think noticing a place where you could be way better than other people seems pretty good. I think you should be careful not to only optimize for fun or something, you should ideally find something that’s really fun for you or really easy for you and kind of hard or kind of difficult for at least some other people. Otherwise, you end up optimizing for jobs which are… Yeah, everyone wants to do those and you’re not going to have a ton of… Maybe sitting on your couch, watching Netflix is super duper fun, but doesn’t necessarily mean it’s your comparative advantage.
Michaël: Yeah. I think the hard things about recording a video or a podcast is it depends on a lot of the guests. So, basically, you need to reach out to people and record stuff and there’s a lot of alternatives. So, it’s not like you have a boss that tells you like, “Oh, yeah, right now, send an email to Alex and put these cameras in.” You just need to do the stuff on your own and you need to deal with a lot of alternatives. So, if you’re not able to deal with that, then maybe it’s not for you.
Alex: Yeah. I think there’s a couple of things there that seem important. So, yeah, certainly knowing whether you need external structure is pretty important. I actually need a bunch of external structure and I have a really good manager and I think I’m way more productive because of this. And then there is a separate thing which is reaching out to people who you think are cool, it feels pretty intimidating. So, the fact you’re able to do it at all seems pretty good. And yeah, I’ve been impressed with the guest selection, it’s one of the reasons I’m a fan of the podcast. ⬆
What Makes A Good Forecasting Question
Michaël: If you were to do any new videos for your channel, what would you want to do?
Alex: Yeah, I think that… I had a whole bunch of ideas and I think the one that’s most obviously missing if I had to do one more, is how to write good questions. Yeah, I did end up writing a bunch of questions when I was making the series and when I was practicing anyway, so… Then I was moderating Metaculus one time as well, so I did a bunch. So, I guess I’ve seen a bunch of bad examples and couldn’t say something about that. Okay, so I think there’s two things that are difficult with writing good forecasting questions. So, there’s something about… Yeah, maybe it’s like, “Do an example,” or whatever. Like, “Can you think about something you care about in the future?” Not AI.
Michaël: Oh, no. How many views will I get on this video?
Alex: So, I think interestingly, this is not terrible as a forecasting question. I want to go one step higher up just so I can use this as an example. So, I think maybe the thing you care about is, “How well does my YouTube channel go?” And so, actually, I think the first step, which in this case is pretty easy, but in other cases can be pretty difficult is going from, “Okay, I want to know how will my YouTube channel go,” and then, “How can I turn that into something that people can actually forecast on?” And in this case, “How many views will this video get?” is a reasonable way of doing it. Sometimes, this can be way harder.
Alex: So, I think maybe a good example of a Metaculus question where there was a bit of a mismatch between the thing people cared about and the thing that happened, was there was one whether… There was a website set up called IsThisACoup.com. And this was while Trump was president, I think it might have been after Trump lost the election, but before Biden was sworn in. And there was a question that was like, “Will IsThisACoup.com say there’s a coup going on?” And this is just not the same question as, “Will the Republican party attempt to coup?”
Michaël: Right.
Alex: The website was obviously partisan and it… So, you’re basically saying, “Is someone going to claim that there’s a coup happening?” And it turns out the website did change to, “Yes.” And it changed to, “Yes,” on January sixth or just after that because the January sixth stuff… But this doesn’t mean objectively that January the sixth was a coup attempt, it just means some website said so. And so, I think this is a pretty clear example and I was actually… I had a much higher prediction in the community on this question and did pretty well because of it. And one of the reasons for my prediction, I was like, “It is much easier for this question to answer yes than for the reality of the world to be, ‘There is a coup attempt in the US.’”
Michaël: This is mostly a problem of the resolution in Metaculus being wrong, having a bad criteria from it for resolution.
Alex: So, I think there’s two separate things here. So, one is actually just going… What people cared about was, “Is there going to be a coup attempt?” and you can’t just write, “Is there going to be a coup attempt?” So, you have to write some metric that people can predict. It’s the same way… that thing lots of people care about is, “Will we get AGI?” And then if you look at the Metaculus questions, you just have to pick a bunch of things that count. And then there is a separate difficulty, sometimes these are related, sometimes they’re actually a bit different, which is, “How will you actually know?” So, with your YouTube views, how will you know? And maybe the answer is like, “Oh, I’ll look at the view counter on YouTube,” but there’s going to be a precise time that the question stops. “What if someone’s not there to check at that time? What if that time shows different readings at different times of day or in different locations? What if YouTube goes down over the course of the time that happens?”
Alex: And the thing about Metaculus users is, like me, they’re massive pedants. And they really really don’t like when there’s something like… Everyone was predicting the YouTube view count and then the view count went down for a day over the course of when the question closed, “Do we use the thing at the start of the day or the end? Do we do a linear interpolation? Do we do a best curve interpolation?” And so, heading off as many of these as possible ahead of time makes the user experience way better. And it’s hard to do in a different way to just the first thing where you notice the thing you care about is not quite what you’re forecasting on.
Michaël: Yeah, I tried to forecast one thing. Sorry, I tried to write up forecasting questions, I think, a year ago after watching your series. And it was, “When will we have something like an open… a free access GPT-4?” Because at that time, to access GPT-3, you had to be in the special BETA. And I was like, “Oh, when will we have GPT-4? And will it be public?” And I had to figure out what I meant by public, right?
Alex: Yeah.
Michaël: “If a private BETA good or not, how many people need to be in the BETA?” If I can have access to the model by going to a different website that charges money to use the API just come… And there’s so many edge cases, it was crazy.
Alex: Yeah, it’s just objectively really hard to do.
Michaël: Even for GPT-4, if they changed their name to something else or another company creates something that is… people agree that it’s like GPT-4, but it’s not GPT-4. What do you think?
Alex: Yeah. I mean, so there’s WebGPT, which came after GPT-3 and isn’t called GPT-4. It seems plausible for many kinds of questions you would’ve written, WebGPT would’ve counted. And yeah, maybe you try to avoid that by saying, “Oh, the training run has to start from scratch,” but what if there’s some slight change where you don’t start the training run from scratch? You start it from some set of weights, which is… I don’t know, the weight of GPT-3, plus a bunch that are randomly initialized. And does that count? Because you did actually do a full 700 billion token training run or whatever. And yeah, it’s really hard.
Michaël: One of the things people care about is the number of parameters of a model. So, between two and three, maybe there was 10-X or 100-X scale up in parameters. So, I thought, “Okay, maybe we should ask… Okay, maybe we need at least 10 times more parameters,” but then there was those different scaling laws when parameters were not as important. So, maybe you need to think about Compute and not parameters. But then other companies like Facebook or something, they use maybe more Compute. But I don’t know, at some point, there was this mixture of experts models where there was sparse parameters. So, in total they had more parameters, but it was not the same way as GPT-3. So, it was a giant mess. But hopefully, OpenAI will release something in the coming weeks or month and we’ll have an answer to this.
Alex: Hopefully, in the sense that then we’ll answer the question rather than a more general thing.
Michaël: Yes.
Alex: Yeah. I think this is a pretty nice example. I think it would’ve been totally reasonable for you to require… parameter counts have increased in some way. And then I’m not sure whether it will for the next big GPT update or not, but you can imagine a world where Chinchilla comes out. Everyone realizes that data is the most important thing and you have something that’s got 90% of the parameters of GPT-3 and it’s miles better because it has two orders of magnitude more data that’s trained on. And yeah, if that happens, your question doesn’t resolve and everyone’s really annoyed that… “What can you do about that?”
Michaël: I think Compute is maybe more important now. I think people care more about, “How much Compute do you use to train your model?” I think,-
Alex: Oh, yeah, you can look back and say, “Oh, Compute would’ve been the best thing to pick, but it’s not necessarily…” Yeah, maybe one thing here is… just an aspect of being a good question writer is being a very good forecaster, because you basically need to just make a bunch of forecasts of the ways your question could resolve ambiguously and then add in edge cases so that it doesn’t… ⬆
How Alex Developed Inside Views About AI Alignment
What Motivated Alex To Learn More About AI
Michaël: Yeah. And I think your background, you said, was mostly math. You taught and now you work at 80K as an Advisor.
Alex: Mm-hmm [affirmatively].
Michaël: And so, you don’t really have any background knowledge on doing AI research. So, I’m kind of curious how you go about forecasting these questions and form your kind of inside views about those kind of things.
Alex: Got to get the name of the podcast in there. Yeah, you’re right. So, I have a very quanty background, but not much AI specifically. I left, I think… I can’t actually remember the date of AlexNet, but I’m pretty sure I graduated one year before AlexNet or something. So, really missed out on the whole deep learning hype while I was at university, at least. I was doing physics, but I don’t know, it feels like physics now jumps on ML stuff all the time. So, yeah, what have I done? I’m in a pretty lucky position at 80K.
Alex: So, it’s important for me to have a sensible understanding of AI, given that I talk to lots of people about it, and given that people ask me questions about it. But I’m lucky because I get to speak to researchers at the top of the game. So, I think roughly what I’ve done, and I think it’s reasonable to say I’ve got a decent understanding of the space now, is I’ve just gone and spoken to a bunch of people and I’ve had kind of a specific goal in mind. I’ve tried to… if I want to be like, “Yeah, let’s go for some meme words or something”. ⬆
Trying To Pass AI Alignment Ideological Turing Tests
Alex: I try to build pretty detailed simulations as AI researchers, internal ones. And I kind of think I’m doing a good job if I could speak to Evan and say, “I think Buck would respond like this here.”
Michaël: Evan Hubinger and Buck Shlegeris-
Alex: Yeah.
Michaël: Researcher at MIRI and CTO of Redwood Research?
Alex: Yes. I have actually done this with Evan and Buck Shlegeris, that specific example. I spoke to Buck just before EAG London and Evan during EAG London. And I was still trying to work out what I thought of the stuff Buck had said. And so, I decided to try to model him and throw objections I thought he’d have, at Evan… Which was pretty useful for me, and Evan didn’t tell me it was a complete waste of his time. So, probably, my model wasn’t totally wrong. But yeah, so I think… What I’ve basically done is tried to… Maybe a good way of a really vocab-heavy way of saying this, is I tried to pass an ideological Turing Test for views from everyone I can get my hands on in the space, who I think is worth listening to.
Alex: And then I’ve actually just noticed as I’ve done that, I’ve always had this thing where when I understand something, I have some intuitive sense of how plausible I find it. And so, as I’m trying to understand what these researchers think without any additional effort, I just tend to also work out how plausible I find the views that they have. And I think overall, I’ve got this large collection of different models, but I’m not really now running an ensemble. I’ve just heard some things and gone, “Yeah, I’m just pretty confident in these things. And then this thing seems a lot more shaky and I’ve got…” Yeah, I don’t know if this counts as an inside view, but I have something which now seems to be distinct from a weighted average of all people I’ve spoken to.
Michaël: So, in some sense, you kind of… You’re able to pass the inside view test or… Yeah, you said the ideological Turing Test. So, can you may maybe explain what’s an ideological Turing Test for the most part of the audience that doesn’t know about those kind of things?
Alex: Yeah, that seems like a good idea. So, the idea of an ideological Turing Test is… Let’s say there’s some disagreement about some position that’s picked, like a political thing. I don’t know, whether you should make immigration legal, and let’s say you think borders should be open. To pass an ideological Turing Test, you would need to be able to make arguments that borders should not be open, that people who think borders should not be open, would endorse as arguments from their side.
Alex: So, the idea is it’s not just, “Can you make arguments for the side that you don’t think is true?” It’s, “Can you make arguments for the side that you don’t think is true that side would actually agree with?” And so the AI case, I’m doing a slightly weaker version of this, and I’m just trying to say, “Can I say things that this researcher would probably say in this situation?” Or yeah, “Do I know what this researcher would probably say in this situation?”
Michaël: And imagine you’re at a party and you want to pretend you’re a Republican or a Democrat at some point, you want to be able to fake being the other party and nobody being able to distinguish between you and the other person.
Alex: Yeah. I mean, I think that’s a really strong version of it and I’m not sure the strong version is that useful. I think that the version of, “I know what the arguments are and can articulate them,” seems pretty useful to be able to do in a wide range of situations where there’s uncertainty. My guess is to actually pass as someone from the other side of the party, you need to know a bunch about social context and be able to pick up on the mannerisms and imitate them. And I know that seems like a hard thing to do and not obviously useful.
Michaël: I was just trying to make a comparison with the actual Turing Test where-
Alex: Oh, yeah. The actual Turing Test is kind machine pass as a human. And so, yeah, maybe the archetypal strong ideological Turing Test is, “You’re a strong Democrat. Can you show up at a Trump rally and talk to a bunch of people about politics and no one notices that aren’t one of them?”
Michaël: Now we need to go to an AI safety conference and pass for an AI safety researcher.
Alex: I think that would be problematic in my case, because I speak to people about decisions they should make and also how likely they are to succeed. It seems useful for me to hold myself to really unusually high standards of honesty. So, I would in fact not do that. Though, if I were… But me trying to do that would be me trying to pass ideological Turing Test.
Michaël: Right. And is there a sense where when you try to imitate Evan Hubinger’s reasoning or Buck Shlegeris’, reasoning that you’re… If it’s easy for you to understand the arguments and it’s easy for you to think about what they would say in a particular situation, that kind of means that you kind of agree with them because you see their arguments as something normal or the reasoning kind of flows right.
Alex: I think it seems plausible that this could happen to some people, but there’s a bunch of disagreement in the AI space, right? So, if I’m trying to do this for a couple of people who really disagree with each other, I can’t just start believing both of them at once. And I think this is roughly how I ended up with my distinct take, that my take is not in the middle. It’s not a single spectrum, but in the hyperspace of views on different things, I’m both not… Yeah, I’ve picked the most plausible person and just copied them on everything.
Alex: And it’s also not the case that it’s the most recent person, and it’s also not the case that I’m exactly in the middle. So, yeah, I guess if you just did this with one person, probably you do end up moving in that direction, but this could go either way, right? At least if you can’t understand their arguments at all, if you can’t work out how those arguments fit together, then you either go, “Wow, this person is just so smart, I have to just totally listen to them,” or you go, “These arguments don’t fit together, I think I don’t believe you,” and generally, too much close to the second thing. Or much more frequently, I do the second thing.
Michaël: Yeah. I didn’t mean that you would update towards the person you’re talking to. It’s more if you cannot really understand what they’re saying and then you usually update towards, “Maybe I don’t intuitively believe what the person is saying. Maybe I don’t share the same crux as the same base arguments.” And so, imagine I’m trying to figure out what Eliezer Yudkowsky is saying. And I think they were talking, there was a discussion on LessWrong between Yudkowsky and a bunch of other researchers.
Michaël: And some people were like, “Oh, what would that even happen in the Eliezer-verse? Would that even happen in the Paul-verse for Paul Christiano?” And that they were trying to figure out in their universe, in their mode of thinking, “would this kind of thing happen or not?” They’re making predictions of things. And for some people, it was very hard to imagine what kind of things would happen in Eliezer-verse or Paul-verse.
Alex: Yeah.
Michaël: So, I guess if you’re very confused about what would happen in Eliezer-verse, maybe you don’t share the same assumptions or because you maybe end up in some weird conclusions that you don’t really share the arguments or conclusions.
Alex: Yeah. I mean, think there’s a couple of things to say here. So one, is I’m pretty sure Paul mentions a couple of times in the debate he has with Eliezer that he’s unable to do this. He’s just like, “I actually don’t understand what Eliezer’s model predict here. And I think that’s a good example of it not being the case that not understanding something means you just instantly have to defer, or at least Paul doesn’t seem to think so, because he doesn’t seem to be deferring on those things to me. Yeah, I think this strategy is not one I necessarily recommend, partly because I’m just in an unusually privileged position of actually being able to talk to lots of people.
Alex: I haven’t really come across that many situations where I’ve just found it really difficult to predict. There are things… So, I spoke to a bunch of people at this conference. There were a couple of small things where people had views that I was not expecting them to. Mostly, I mean, it seems I’m pretty well calibrated on this when I was expecting people to have a range of views with some confidence, they basically thought that. And when I didn’t really know what the person thought, often I was surprised. I think there’s another thing where… I don’t know, I’ve got no idea what Scott Garrabrant thinks about AI. I-
Michaël: Scott Garrabrant, researcher at MIRI?
Alex: Yeah. I started listening to the interview he did with Daniel Filan and then one of them said at the start, “Oh, you should listen to this talk that Scott gave first.” And I was on a bus and I didn’t want to look at my phone and the talk had slides, so I didn’t want to listen to the talk. And so, I listened to a bit more of the podcast and went, “Oh, man, I really should watch this talk first.” And so, I’ve not got around to getting back to the episode. And then I listened to both of Daniel’s interviews with Vanessa Kosoy. And I don’t know, man, I could follow each sentence and just about understand what the sentence meant.
Alex: But this was one of the cases where I didn’t really feel I was then having this intuitive reaction where I also was… My brain was also doing this thing where it decided how plausible the things were. I was just about able to follow the reasoning, but I was not confidently able to predict the next step of the reasoning. I haven’t spoken to Vanessa, I’d like to read some more of her work though. I know that she’s looking for distillers because I think it’s pretty hard for lot people to understand. So, I haven’t really incorporated her thoughts into my model at all yet. So, roughly what happens in those cases is I just have not yet updated, because I don’t feel I’ve processed enough information to really update.
Michaël: And when you encounter a new question, I don’t know, “When will GPT-4 arrive?” How many parameters it has or, “What would be the performance or test loss of this model?” Or, “What will be the new DALL-E?” Or, “What will be the actual GDP growth in five years because of AI?” For these kind of things, how do you actually think about a thing? Do you model, “Oh, what would Paul think about this question?” Or do you just do normal forecasting?
Alex: Yeah, I mean, so somewhat disappointingly, probably, for listeners, I just haven’t made that many forecasts in the last few months because I’ve been really busy trying to do a lot of my new job. I don’t know, AI seems like a big deal. And the best way, it seems, for me to help with that at the moment is help people move into places where they can have an impact on it. And so, I’ve basically been prioritizing that over forecasting. What would I do? My guess is I would do a bunch of things that I did in the videos here. I’d basically make a large guesstimate, split into different worlds, which if you watch the video on it, you’ll know what that means.
Alex: And then what would I do for each of the individual worlds once I’ve decomposed a bunch? I think I’ll probably go with my own take, read some stuff, refresh my, sort of, some memories. But yeah, I’m at the level now… Or the way my understanding worked, is I’ve spent a bunch of time trying to predict what different people would think. And now, I just have some sort of conclusion from that, which is some combination of a weighted average of their judgments and my intuitive responses to them. ⬆
Why Economic Growth Curve Fitting Is Not Sufficient To Forecast AGI
Michaël: So, what I meant is more for… Some of the reports we had, let’s say the impact of economic growth of AI, those other things that-
Alex: Oh, yeah.
Michaël: Would it lead to some singularity in some year? Or when will we get so much of AI? For those kind of things, do you defer sending people? Do you have some disagreements on what people say about those things?
Alex: Yeah. Okay, so yes, there’s stuff like the Roodman paper that came out of Open Philanthropy. This is one where there’s doing a bunch of curve fitting to economic growth.
Michaël: Can you maybe explain the paper for people who are not familiar?
Alex: Oh, that’s what I was trying to do with… There’s a bunch of curve fitting for economic growth. Okay, so yeah, the rough idea is if you look at GDP throughout history really zoomed out, it’s going up, that’s obvious. But it seems to be going up faster, that’s obvious. And the rate at which the gradient is growing also seems to be growing and it actually seems to be what’s called a super exponential. So, it’s growing faster than exponentially… And there’s a bunch of problems with this model, right. To start with, it’s pretty difficult to get estimates of GDP in hunter gatherer areas or pre-industrial revolution. But the range of estimates is a fueled as a magnitude and you still get the rough general shape.
Alex: So anyway, you draw this relatively smooth curve through GDP… throughout history. And the shape of that curve is such that it goes vertical before 2100. And does that mean we’re going to get infinite growth before 2100? Obviously not, but it means something weird’s going to happen, at least according to this model. I think some people find this… Well, this sort of thing could be used to do two different things and you might have to remind me what they are. So, one is, “Make an active prediction,” and one is, “Respond to another reference class argument.”
Alex: I’m pretty unsympathetic to people using these for active predictions. So, the idea here is maybe… Yeah, so maybe someone’s just like, “Okay, so in 2060…” I think it’s the vertical line, “We are going to get something as crazy as infinite economic growth, maybe it’ll be AGI. So, I predict 2060 infinite economic growth, AGI.” I think it’s just not obvious that this is the best reference class. And the thing about reference classes is it’s really easy to use them and it’s really hard to know which ones to use. So, I don’t like it as something as active as that, but then there’s another thing which hopefully, you’re going to remind me of and then I don’t have to remember it for so long.
Michaël: So, you said active prediction and the second one was response to reference class. I think you said the second one, but not… So, why do you need to make active predictions? What do you mean by active predictions?
Alex: Oh, so the active prediction one is the thing I just said, which is like, “I’ve done this curve fit. So now, I think 2060.” I’m not super excited about using models for that.
Michaël: And so, how do you respond to a reference class?
Alex: So, what I’m doing here is… I think there was a class of skepticism about safety or skepticism about AGI, which goes something like this, “In general, you should use reference classes to determine your forecasts.” What this means roughly translated, is you should predict things to carry on roughly how they are. And then people say, “Things carrying on roughly how they are doesn’t look like we get AI takeover and everyone dropping dead,” so you should have a very high burden of proof for the step by step arguments, logical arguments, in order to claim we are going to get something wild like AGI in the next few decades. And I think a really strong response to this line of argument is to say, “What do you mean everything continues as normal means we don’t get anything weird?” “Everything continues as normal,” means we should look at curves and different things and expect them to carry on smoothly.
Alex: And if you look at curves and a bunch of different things and expect them to carry on smoothly, you get really weird behavior pretty quickly. And so, that’s the sense in which I think they’re really useful. And there are other versions like this, so you might think, “Hey, humans have been around for a while,” we’ll probably carry on being around for a while. Maybe it’s really weird for a sort of civilization to just disappear and you can… If you go through geological time, you can go… we had single cell life and we had multicellular life, and we had mammalian life and we had the dinosaurs disappeared or evolved into birds. I’m not really sure what the state-of-the-art is there. But there have been big transitions in the past and if someone’s like, “We should expect no big transitions,” you might turn around and say, “But there have been some big transitions.” So, the idea is it’s not a positive case, but it responds to the argument that says, “You should have an unreasonably high burden of proof, because so far everything’s looked pretty normal.”
Michaël: So, you’re saying that so far, things are not been normal and that we’ve had some sharp transitions before and there’s going to be more weird stuff, but not a… weird singularity in 2050 or 2060?
Alex: I mean, there might be, I don’t know. But I think that curve fitting does not give you enough evidence to just go, “Okay, so now you should be confident there’s this weird thing happening then,” but it does give you enough confidence to go like, “Oh, man, I should actually look at the object level now because my reference class doesn’t say normal stuff don’t really worry about it.” Maybe we can link to some our world in data graph. If you just look at GDP growth throughout history… Yeah, just do the funny graph. Sorry for podcast listeners, this is going to suck for you.
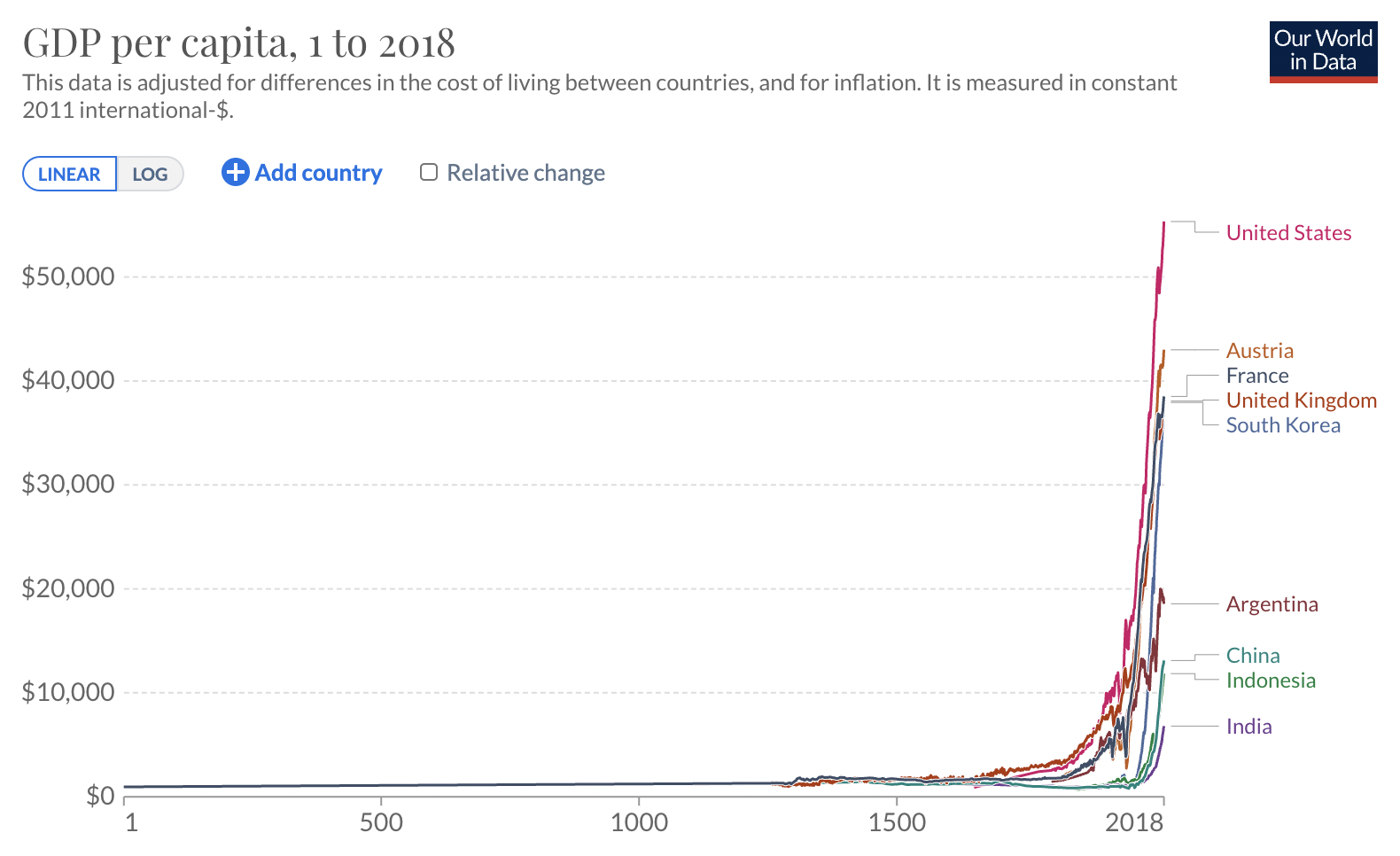
Michaël: So, the only thing I know about those kind of things is this picture on Twitter. When I try do forecasting on GDP before 2047, something like this, I think it was 2045, 2047. And it was some kind of power law.
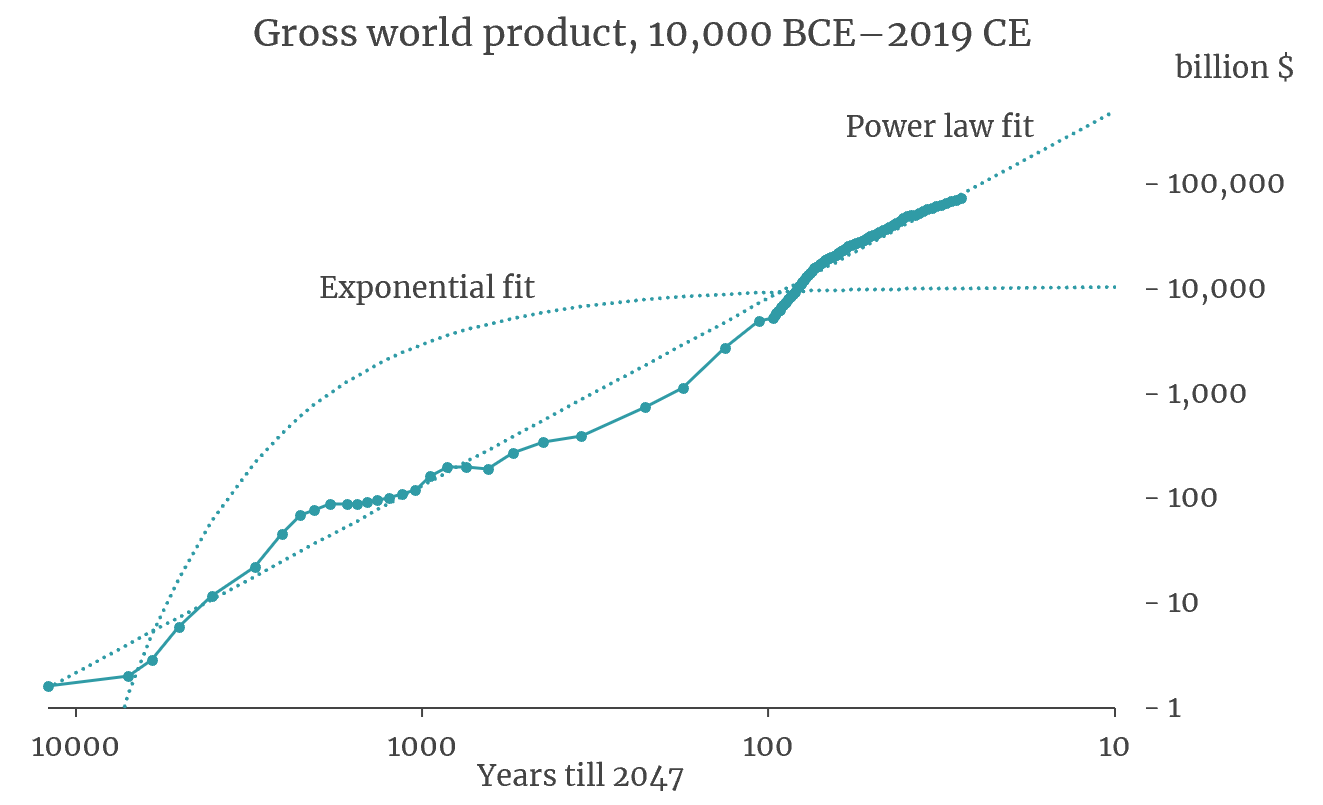
Alex: Yeah.
Michaël: So, if you kind of fit a power law between, I don’t know, 10K years before BC and 2047, you have this weird singularity in 2047.
Alex: I didn’t realize it’s 2047, I thought it was 2060. Anyway, something like that. It’s these kinds of things. And yeah, I guess what I’m saying here is this at least means you have to look at what’s happening in the next few decades and make a judgment call. I don’t think it is enough on its own to say, “Hey, man, everything’s going to get super wild,” but it’s enough to go, “Some things might get super wild, we should look.” And if we then find strong arguments to believe things should get super wild, we don’t get to retreat to, “Oh, but we should make normal predictions most of the time.”
Michaël: So, the burden of proof… Should we actually ask for a high burden of proof if people make weird claims?
Alex: I mean, in general, one should have some high burden of proof if people make weird claims. But I think if you’re specifically saying a claim that economics is going to go crazy in the next few decades, is a weird claim. I think the sort of curve fitting exercises are enough to say, “No, you don’t get to claim that, it’s weird. You don’t get to claim that, high burden of proof there.”
Michaël: Yeah. I think one kind of weird… So, somewhere where I don’t fully understand Alex Lawsen’s model, is you say something like, “The years for weekly version of AGI…” or the other question, I think it was the other question about AGI is something 2040-ish or 2050. And you also say that you don’t expect to have this singularity in economic GDP growth in 2060 or something. And so for me, people seem to anchor on the Ajeya Cotra’s Biological Anchors report on Transformative AI, I think around 2045 or something. And if you believe this, then the GDP per-capita or something will grow a lot, right, between 2045 and 2060 if you just believe this report or the average on this report. So, yeah, in your model, what happens between transformative AI and AGI?
Alex: Oh, yeah. So, typically, I’m not saying I think that there is not going to be a technological singularity. I’m claiming that curve fitting to economic growth models is not sufficient reason to believe that on its own. You can then look at the development of AGI and predict that happens by 2050 and then you can say, “Wow, economic stuff’s going to go wild after that point.” But then the reason you’re saying that is because of a combination of facts, including actually having a gears level model of what’s happening. So, this is a claim about… The growth models are, in my view, sufficient to say you should look at the next few decades carefully and see what’s going on, but are not sufficient on their own to allow you to confidently predict what will happen.
Michaël: What are other things people could look into to have more confident predictions than this?
Alex: I don’t know, don’t you have a whole podcast about AI or something? I think Holden Karnofsky’s blog, Cold Takes, is a good place to start if you want to think about things that are going to be happening in the next few decades and whether they’re going to be wild or not. His most important century series, it’s a really good introduction. ⬆
Additional Resources
Michaël: I think that’s a great opening for the end of the video, so that people can just look at other things and the whole podcast about AI forecasting. Hopefully, there will be more videos. You can do one more thing about your forecasting videos as well.
Alex: Cool. Yeah, let’s do, “If you want to see me chat about forecasting with terrible production value, you can click over here. And if you want to speak to me about your job, you can click over here. And if you’re listening to this on the podcast, go to youtube.com and search for The Inside View”
Michaël: I think the problem is that you can only do two links at the end of the video and not five, but I’ll find a way to add some-
Alex: No, just do those two.
Michaël: Add some links. Yeah, it was nice talking to you and hopefully, it’ll not be the last one.
Alex: Yeah, thanks for having me.
Michaël: Cool. We did it.