Connor Leahy on Dignity and Conjecture
Connor was the first guest of this podcast. In the last episode, we talked a lot about EleutherAI, a grassroot collective of researchers he co-founded, who open-sourced GPT-3 size models such as GPT-NeoX and GPT-J.
Since then, Connor co-founded Conjecture, a company aiming to make AGI safe through scalable AI Alignment research. One of the goals of Conjecture is to reach a fundamental understanding of the internal mechanisms of current deep learning models using interpretability techniques.
In this episode, we go through the famous AI Alignment compass memes, discuss Connor’s inside views about AI progress, how he approaches AGI forecasting, his takes on Eliezer Yudkowsky’s “Die With Dignity” heuristic to work on AI Alignment, common misconceptions about EleutherAI, and why you should consider funding his new company Conjecture.
(Note: Our conversation is 3h long, so feel free to click on any sub-topic of your liking in the Outline below, and you can then come back to the outline by clicking on the arrow ⬆)
Contents
- Intro
- AGI meme review
- Current AI Progress
- Defining Artificial General Intelligence
- AI Timelines
- Understanding Eliezer Yudkowsky
- EleutherAI
- Misconceptions About the History of Eleuther
- Why GPT3 Size Models Were Necessary
- Why Only State of The Art Models Matter
- EleutherAI Spread AI Alignment Memes
- EleutherAI Street Cred and the ML Community
- The EleutherAI Open Source Policy
- Current Projects and Future of EleutherAI
- Why Getting Things Done Was Hard at EleutherAI
- Conjecture
- How Conjecture Started
- EA Funding vs VC funding
- Early Days of Conjecture
- Short Timelines and Likely Doom
- Cooperation in the AGI Space
- Scaling Alignment Research to get Alignment Breakthroughs
- To Roll High Roll Many Dices
- The Epistemologist at Conjecture
- What Economics Can Teach Us About Alignment
- What the First Solutions to Alignment Might Look Like
- Interpretability Work at Conjecture
- Conceptual Work at Conjecture and The Incubator
- Why Non Disclosure By Default
- Keeping Research Secret with Zero Social Capital Cost
- Remote Work Policy and Culture
- A Focus on Large Language Models
- Why For Profit
- Products using GPT
- Building SaaS Products
- Generating Revenue In The Capitalist World
- The Wild Hiring at Conjecture
- Why SBF Should Invest in Conjecture
- Twitter Questions
- Conclusion
AGI Meme Review
The 2x2 AGI Compass

Michaël: How did you react when you saw this meme? Did you find it somehow represent your views?
Connor: My first reaction to this meme was, hey, I’m in good company. So yeah, I think it’s pretty close to where I would place myself. Not exactly. I don’t think anyone could be more AGI bad than Eliezer, I think that is probably possible. Scale maximalism and AGI soon, I think are not the same thing. I think I may be more scale maximalist than Yudkowsky but I’m not sure where we both rank on AGI soon-ish because I don’t really know his timelines of that well. So my original reaction to this was I should probably be where Gwern is on this.
Michaël: Right, because you’re both bullish on scale.
Connor: Yes, I’m pretty bullish on scale on many things. Happy to talk about exactly what I mean by that. And I am not as pessimistic as Eliezer but I’m pretty close ⬆
The 6x6 AGI Compass
Michaël: So I made another one after the reactions from this one where I had this quote where you said that you’re maybe more scale-pilled than Eliezer and less doomerish than him.

Michaël: So now you ended up being in this bottom right quadrant. Did you have another reaction from this one or is it basically the same thing?
Connor: My first reaction was fuck yeah, I got the cool corner, but the second reaction was Eliezer deserves the corner because of course in every political compass, your eyes first go to the most extreme corners. Of course those are where usually insane people are, but you’re looking in a political compass, you know you want to see the crazy takes. And I feel like as much as I appreciate my positioning here, my takes are marginally milder than at Eliezer’s.
Michaël: In terms of pessimism, yes. But in terms of scale pilled-
Connor: Yes.
Michaël: He doesn’t talk about scale so much.
Connor: So yeah, we could talk about scaling a bit. So it’s not that I literally think that a arbitrarily large or a large MLP is going to suddenly magically be AGI, that’s not exactly what I believe, but I think that almost all the problems that people on Twitter pontificate about is unsolved by deep learning will be solved by scale. They say, well, it can’t do this kind of reasoning or this kind of reason, it can’t do this symbolic manipulation or, oh, it fails at parentheses or whatever. I’m like, just stack more layers lol. I think there are some things that may not be solved just by scale, at least not by normal amount scaling. Okay, if you scale the thing to the size of a Jupiter brain or something, maybe a feat forward, MLP is enough. But there’s a few other things I think that are necessary but all of those are like pretty easy.
Connor: So like a few years ago, when I was like, when I take a piece of paper and I would sketch out, how would I build an AGI? There would always be several boxes labeled as magic where it’s like, I don’t know how this would actually happen. Those have not all been filled. There’s no more boxes where I’m like, I have no idea how to even approach this in principle. There are several of these boxes where I’m like, okay, this seems difficult or current methods don’t perform that well on this, but none of them are fundamentally magic and scaling is what filled in most of those boxes.
Michaël: Do you remember what were in those boxes?
Connor: If I knew how to build an AGI, I probably wouldn’t say in the public podcast, would I? ⬆
The 4d Compass
Michaël: Right. Huh, then there was this, I guess this is kind of the similar one, but in 3D.

Connor: That’s the big brain, so it’s in 4D.
Michaël: This is the big brain meme. This explains the other one because the other one is like a projection using something like PCA and there’s this… I guess the only one I’m not sure about is your slightly conscious axis.
Connor: I mean, that’s just a shitpost axis, right?
Michaël: Right.
Connor: I’m pretty sure Joscha was shitposting on that thread about what he believes. I don’t know Joscha that well but-
Michaël: I believe he is maybe more a computationalist in terms of consciousness than other people. You might believe that there’s a program might be conscious where-
Connor: I think Eliezer is very computational. I’m very computationalist. I’m more uncertain about that, but it seems to me that computationalism is the default assumption. I’m not saying there’s huge problems with computationalism, but I don’t see any other that doesn’t have equally if not larger problems.
Michaël: Do you believe that the large language model could be conscious?
Connor: Depending on what you mean the way we’re conscious. Conscious is what Marvin Minsky called the suitcase word. You going to have two people both use the word conscious and mean something that has absolutely nothing to do with each other. So some people, when they say conscious, they mean has attention or has memory or something like that. While other people have some ideas about self reflectivity or have ideas about emotions or whatever.
Connor: So consciousness is an unresolved pointer. You have to do a reference to pointer before you can actually talk about the question. There are certain definitions of the word consciousness that language models obviously have. They can reason semantically. If your definition of consciousness is can write a decent fiction story, then yes they’re conscious. But is that the best definition? Probably not. That’s not what we usually mean by that. So the theory of consciousness that I take most seriously are the simple, just like illusionist slash attention schema, like Grazianio or whatever his name, is type theories where we described consciousness is just like an emergent, just what it feels like to be a planning algorithm from the inside. That’s my default assumption. It’s just, there’s no mystery here, this is just what it feels like to be a planning algorithm.
Connor: There’s no mystery, there’s no hard problem. That’s just how it is. And whether these systems have experience is just not really a question. There’s no mystery here, there’s just the physics, there’s nothing more.
Michaël: I think for me, the main difference with how human experience consciousness would be that for us is more like a physical continuum where you can only literally interrupt our computation, except from maybe going to sleep would count as stop being continuous for a bit.
Connor: I sometimes lose consciousness when I’m listening to music or I’m driving a car or something like that. Sometimes things be like oh, I’m home, how did this happen? So I think talking about consciousness is a great example of an excellent way to waste all of your time and energy and make absolutely zero project progress in any problem that matters. If anyone brings in consciousness in conversation, I’m like, okay, so we’re not making progress to AI.
Michaël: Right. So we’re not making progress on AI, but at some point we’re going to get AGI or very smart models and we’re going to take moral decisions as to whether we can turn them off.
Connor: So we have to talk about is and ought, so the problem with the word consciousness is that on the one hand, it’s an is. Some people will generally say consciousness is a property that certain systems have or don’t have. But then also there’s an ought, is that consciousness is the systems, is the property that gives them moral weight. So I think there’s perfectly good arguments to be made that for example, animals or young children don’t have consciousness in the same way as adults do.
Connor: I’m not saying agree or disagree with this. I’m just saying there are perfectly coherent arguments to be made. And now you could argue, does that mean that they don’t have rights? Does it mean I can torture them? I don’t know. I’m saying probably not.
Michaël: They have less voting rights.
Connor: Yes they do and you could argue as consciousness as the relevant factor there or not. I don’t know, you can define it that way. I think it’s a much better way to kind of try to separate these from the ought. It’s like, okay, let’s separate the conjugation complexity, or the computational properties or whatever properties the consciousness has. For example, QRI, my favorite mad scientists think a lot about what they call valence structuralism and quality of formalism. So they think that there is an objective fact about consciousness and valence and emotions, qualia and stuff like this. Are they correct?
Connor: Fuck if I know, but at least it’s something you can talk about or you can at least try to reason about. And then you have to make the additional moral argument. So for example, say I identify some structure that I think is related to valence. Valence is how good something feels. And let’s say, I identify so for example, QRI as a theory, which is the symmetry theory of valence. So I think the symmetry of neural processes is what valence is. That’s just one of theories they have. So let’s say this is true. Let’s say can, well, it’s true. Let’s say I study this thing, I show in every brain study. I study all the brains. I look at everything and whenever there’s like symmetry, high valence is reported, whatever right? Cool.
Connor: Now I have a theory and now I have to additionally make the claim, this is something that’s morally valuable. We should for example, maximize valence for example. And then this valence cashes out physically as symmetry. This then has some really weird consequences. Since for example, black holes are very symmetrical. So maybe being a black hole is the most awesome thing in the world and we should just collapse the universe into a black hole switches. I’m not saying that this is a position anyone endorses, I’m just saying it’s really hard and we’re extraordinarily confused about this. I don’t think any philosopher, any cognitive scientist, anyone anywhere has any remotely close to a satisfying answer to these kinds of questions. It’s not clear to me if there are satisfying answers.
Connor: I think it’s something people should think more seriously about. It’s something that I think should be investigated in whatever means necessary. But I do not think this is something that is in the same kind of epistemological category as the kind of work we do in AI. So I’m not saying these are not important questions, I expect these questions to be become extraordinarily pressing in the near future, but they’re kind of like a different epistemic category. They require different kinds of epistemic inquiry than you might do when you’re admiral layers hole. So we could talk about the philosophy and valence and stuff like this for hours or whatever. Probably get absolutely nowhere, except I don’t know, high?
Michaël: But we are in California, so this is the time. So yeah, let’s stop this consciousness debate here. I just wanted to get your thoughts on the ins and out and now we talked about it. ⬆
The Rob Bensinger Compass
Michaël: Now, the last meme for us will be like the one from Rob Bensinger, which is more close to people’s views. And there’s a bit more people here and the axes are bit different is AGI not soon and AGI soon. And then, all future values unlikely to be destroyed by misalign AI, which is maybe more what we care about. I don’t know if I asked you before your position, but I guess we are both below right corner. And there’s now a scale with years and you didn’t ask me for the years. I think that the years are for me, but yeah, what do you think of this? Do you have any thoughts?
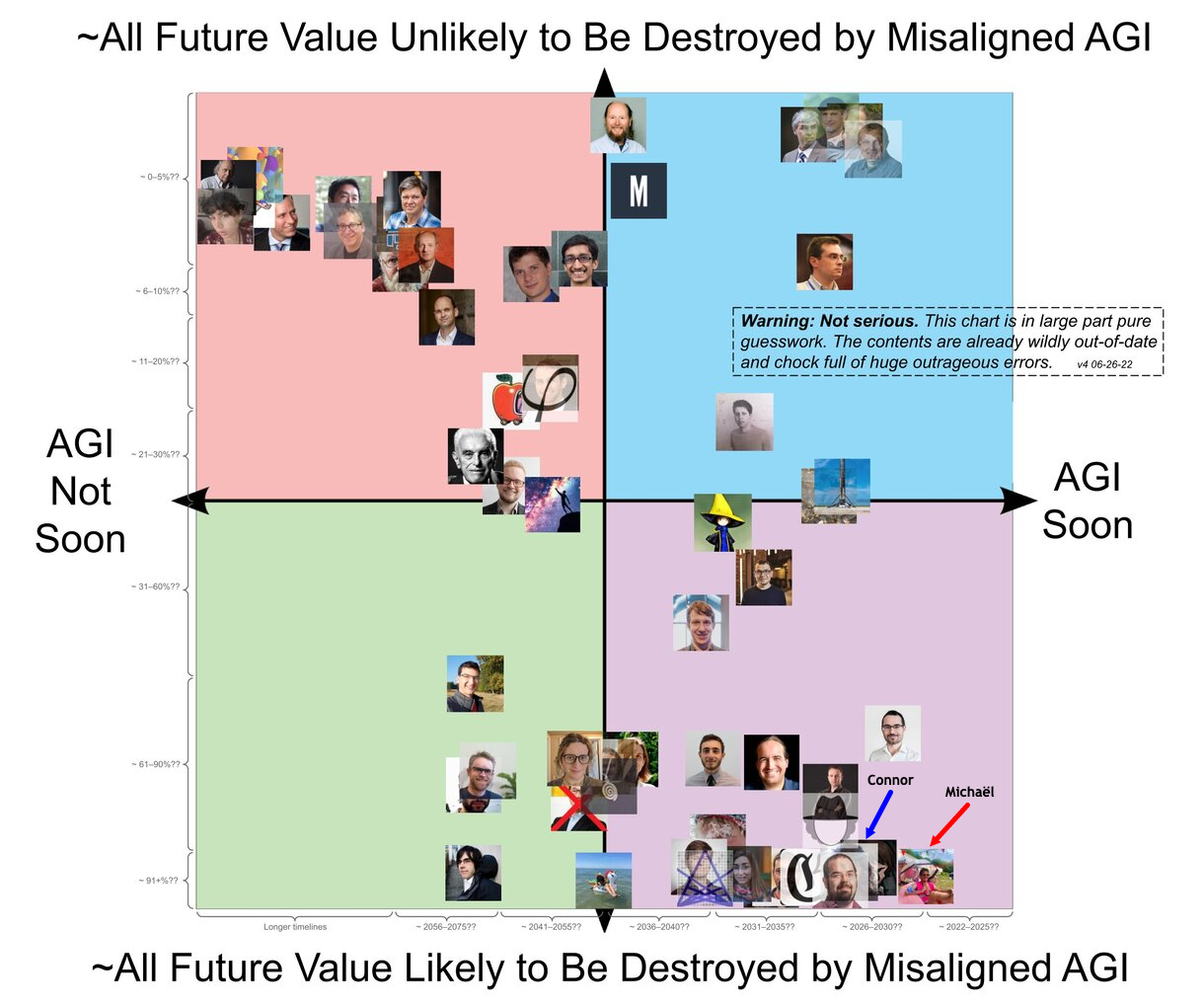
Connor: Yeah, I think this is pretty accurate. I think this is pretty accurate to my kind of beliefs. I’m not sure what dates do you put in? Oh yeah, that sounds about right. Yeah, those those look about right for me, for my timelines.
Michaël: I think it’s 2026-2030 for you.
Connor: Yeah, yeah. That seems about right for my kind of thinking and yeah, I expect… So I think the main disagreement between me and Eliezer is not so much a disagreement or more than just, I am much more uncertain than him. I do not know how a human can get to the level of epistemic confidence he seems to have. So I don’t disagree with Eliezer really, some things. I don’t disagree with most of his arguments about why alignment is hard. It’s more just, I’m less certain than him. I have a greater variance that I could just be wrong about something.
Connor: So that’s why I’m by default and less pessimistic than him. But if I was as confident as him, I would probably be close to as pessimistic, not exactly but close.
Michaël: Right, so you’re saying that basically you could be at 99% probability of doom, but have like five or 10% error bars.
Connor: Yes, that’s, that’s kind of my thinking.
Current AI Progress
Michaël: Right and in terms of timelines, I remember you talking on Discord or in the last episode that… Yeah, you had pretty short timelines and even when we got some breakthroughs, in deep learning, you still had those short timelines. So you didn’t update much from those. So I’m really curious because in the past two weeks we had Minerva that could do math and multitask understanding. So it got 50% accuracy on math, which Jacobs Center predicted would happen by 2025. Did that update for timeline by anything? ⬆
Just Update All The Way Bro
Connor: Not really. I mean, maybe very mildly just because every small bit of information should update you some amount. But so basically… So yeah, we’ve had these big release in the last two weeks and over the last two months, the Metaco’s prediction for when AGI come has dropped by six months each twice within one month. So when you look at something like this, you can do what the rationalists, I believe refer to as a pro gamer move. And if you seize a probability distribution only ever updates in one direction, just do the whole update instead of waiting for the predictable evidence to come, just update all the way bro. Just do the whole thing. And this is basically what happened to me back in 2020.
Connor: So I updated hard on GPT-3, so I was already updating on GPT-2. My biggest update, I think on timelines was the release of GPT-2, a hundred million parameters. That was the really, really terrible model that could barely string together a coherent sentence. And I remember seeing that for the first time and I was just like, holy shit, this is amazing. This is the most amazing thing I’ve ever seen in my life. And a lot of other people didn’t update as strongly as I did on that. But I was already like, holy shit. We’re actually going to see AGI dudes. This is actually crazy. I didn’t update all the way to super short timelines. I was still like, I don’t know, 2045 at that time or something.
Connor: But then when GPT-3 came out and especially because it didn’t need new techniques, they just scaled the model larger. It makes such a huge difference, that’s when I started to really update. And so that’s when I was was started EleutherAI because I was like, oh, holy shit, I’m updating hard on this, I’m pivoting. We need to work on this. After GPT-2, I was kind of like, this is probably the end of the road. I’m going to work on something different for a while and now I’m kind of burnt out on this language model stuff. And GPT-3 came out like, nope, back, I’m coming back. I’m back boys. So I updated very hard. I pivoted back to this and I’m like, okay, look, it’s hard sometimes hindsight bias to see how things were. ⬆
EleutherAI Early Discoveries
Connor: But two years ago, things were quite different, especially in the alignment community. People weren’t really taking scaling and language models nearly as seriously as me and my friends were back in 2020. And so with the EleutherAI, we were one of the first groups that kind of took these super, super serious. We’re not the only ones, there were lots of groups like OpenAI and the later Anthropic people and stuff like… Th were already thinking in this regard, they were ahead of us. But we were some of the early people in the wider alignment community to update really hard on this and really shift our behavior in response to this. So basically over the first year or two of EleutherAI, we basically build so much tacit knowledge about these models.
Connor: We read every blog post, we played with models every day. We tried to build our own, we trained them, we see how they work. We thought seriously about them, we blog post. We thought about it, every limits and stuff that we basically had a speed run of updates that took other people two or three years to do. So the update that Minerva gave other people I already had in late 2020 basically. So and since then I haven’t had to update very much. It’s like Gato, not surprising, not at all surprising. I’m surprised we took that long. Like the the chain of thought prompts were not all surprising. That’s something I knew about like 6 to 12 months before anyone else in the world knew about it.
Connor: That’s one of the things I’m actually quite proud of that EleutherAI. We found out that those worked.
Michaël: So did you find the “less think step by step”?
Connor: Yes, like that kind of stuff. It wasn’t exactly that prompt, but this type of technique, we actually discovered before anyone else did, and we kept a secret because we were like, holy shit, this is really scary. And so that’s one of the things we then didn’t publish until after other people started publishing about it. And then we publish our draft about it, which we’ve had, we’ve been sitting on for like six months. So a lot of the things that people are discovering now we discovered at EleutherAI within like the first 12 months. So I have been running that update ever since. And so there hasn’t been much stuff that’s been updating me. ⬆
Hardware Scaling and H100
Connor: The only updates I’ve been having are hardware progress. It seems like the H-100s are quite a bit better than I expected them to be, which is bit spooky.
Michaël: Do you know what makes them much better?
Connor: Just the performance numbers, I’ve haven’t used them myself, but that I’ve heard in such, seem really quite impressive. And I have heard rumors about how much money corporations starting to spend on these things. And I’m like, oh shit. You think you’ve seen scaling, H-100 were just the warm up.
Michaël: So we’re going to see billions of dollars spent on H-100s?
Connor: I expect that, yeah.
Michaël: Okay so why what you’ve just said about scaling resonates with me about a meme I did recently about the Chad scale maximalists who didn’t perform any Bayesian updates since 2020, because he read this like neurons can’t lose paper, log-log plots, and then okay, I got it.
Connor: Yep, that’s sort of what happened. I mean, there was more tacit knowledge, there was more experimentation than that, but yeah basically. If you look hard enough at the log-log plots and you just kind of, and you look at hardware scaling and you have a bit of experience with how these models perform yourself, you do some experiments, you see your prompt improve performance and stuff. As Eliezer likes to say, sometimes the empty string should convince you, but here’s some additional bits. ⬆
DALLE2
Michaël: Thanks for add additional bits. Most people look at models through Twitter. They look at cool outputs and yeah, I guess the most impressive models so far have been Dalle-2, Imagen and Parti. So they can show their understanding by just throwing like cool pictures. Were you impressed by those at all?
Connor: Dalle-2 was a mile. I mean, it wasn’t really an update because I don’t think it’s that important for timelines. So EleutherAI was also very early on art models. So we were some of the first people to be dicking around with click guided diffusion and stuff like that. So I basically already had an update back then as well. We had a pretty early update where I looked at how small these models were and how good they already performed. And they’re like, just log-log plot, bro. But yeah, so I already had a pretty early update in the early models. I knew this was coming. Dalle was better than I expected in the coherence sense. I can’t stress this enough for people who haven’t tried Dalle.
Connor: It is actually amazing. Dalle is one of the clear… For me GPT-3 was the obvious. Like okay, how can you look at this and not be like, holy shit, takeoff is around the corner. But Dalle is so understandable. GPT-3, I understand if people can confused by it or GPT-3 is kind of confusing. It’s kind of hard to understand what it’s actually doing and how it fails and stuff. But Dolly, we have a bunch of Dolly art hanging around the office actually and it’s just incredible. It’s coherent, it can compose objects. It can do seem like yeah, sure, sometimes it’ll fail at some reasoning task. You say, draw three red blocks and it’ll draw four, okay, sure, it’s not perfect, but… ⬆
The Horror Movie Heuristic
A good heuristic I like to use to think about when we should be maybe taking something seriously or not is imagine you were the protagonist in a sci-fi horror movie, when would the audience be screaming at you? And I’m pretty sure with like GPT-2, GPT-3, Dalle and Imagen, this is a horror movie, right?
Connor: And you have the scientist in the lab and they click a button and then and draw this thing and draws and draw yourself and it’s like a robot, looking at them and they’re like, oh yeah, this isn’t interesting. You would be yelling at the screen at this point in time. Sure you can always post hoc or he’s like, oh, it’s just a neural network. Oh, it’s just combining previous concepts. Bitch please! Okay, what else do you want? What do you want? There’s a great meme I remember somewhere. Whereas the year is 2040, terminators are destroying the world, whatever. And Gary Mark is in the ruins of MIT, but they’re not using symbolic methods.
Michaël: They’re only using deep learning.
Connor: It’s not true intelligence, he says before he dissolves into nanobots.
Michaël: Yeah, so we are basically in the movi “Don’t Look Up” where there’s an asteroid coming and every time we react to something, “oh, it’s not very smart”, “Oh, you cannot put a red cube on top of a blue cube”, we’re basically like the journalists in the movie “Don’t Look Up” where there’s this asteroid coming and be like, “oh yeah, just an asteroid, we can just deflect it”. And the audience is just watching the movie and they’re like, “what the fuck guys, do something about the asteroid, do something”. We’re just screaming at the movie.
Connor: Yep, I haven’t seen that movie, but yes that’s kind of… Sometimes I feel this way. I think there are reasonable things to be skeptical about and such whatever, but also do the calculus people. To all the ML professors out there who don’t take these kind of risks very seriously. You’re smart people, you understand probability. Consider the possibility here that there are multiple options here and the options of the not good outcomes are not trivial. I like Stuart Russell, I think said this. It seems a very shocking amount of AI professionals never ask themselves the question, what if we succeed? What if just everything works exactly as planned? You know, you want to write AGI that can do anything human does and you just do exactly that. What then? So some people I think will answer something like, well, the AI will just love us or will just do what we want it to do.
Connor: And I’m like, oh God, that’s mm…. We can talk about that later, if you want to into some technical details about alignment and why expect I this problem to be hard. As you said, in the scale, on the graph. I’m pretty scale maximalist I expect AGI to not to be too hard and to come soon and I expect alignment to be hard.
Michaël: Yeah, let’s talk about AI alignment later, but I guess the thing about what if we succeed, some people definitions of succeeding is making this stuff do what we want them to do. Right. So for them, alignment is part of the problem.
Connor: That’s fair enough, that’s a fair kind of point. And I do think some people do think about it that way on. I don’t think many people think of it very explicitly. I think a lot of people kind of just focus on making number go brurr. Just improve benchmark performance, just make us smarter and such. And there’s a common meme. We’re kind of like, well, an intelligence system will just know what we want. And I think there’s very strong reasons to believe that is not trivial true. There are versions of this that might be true but the default version I do not expect to be true.
Michaël: Yeah. I think some people take alignment by default to be pretty likely and I think for both of us is pretty unlikely. Just to finish on the scaling part, did EleutherAI discover Chinchilla or something similar or was this a new law that you discovered?
Connor: We did not discover the Chinchilla law. I’m aware of multiple groups that did, so DeepMind weren’t the only ones who discovered this, multiple other groups did as well, but we were not one of them.
Defining Artificial General Intelligence
Michaël: Gotcha and on the memes that I mentioned, we talked a lot about AGI and I think to ground the discussion a little bit more, we should just maybe define it or just use a definition we both find useful to talk about it.
Connor: Yeah, so this is-
Michaël: Or we can ban this word as well.
Connor: No. Yeah, so, no, I think this is good. I think AGI is actually a good word.
Connor: So my favorite definition, I think is from a post from Steven Byrnes, which I think may not be posted yet. It may be posted by the time this episode goes out where he kind of like pushes back against Yann LeCun who argues that general AI doesn’t exist. So the way I think about the word AGI is there are definitions which are wrong in technicalities, but true in spirit. And there are those that are technically maybe you know, accurate but wrong in spirit. So I like the ones who are true in spirit, but every time I bring those up, some nitpick will be like, well actually, technically what you just said is incoherent. And I’m like, okay, sure. I’m aware of this. Finding a real technical definition is extremely hard and almost always missing something. So for the purpose of this discussion, I think is more productive if we use a definition, which is not 100% technically rigorous, but brings across more of the spiritual correctness
Michaël: The vibe.
Connor: The vibe. This is what the zoomers say I guess.
Michaël: We are in California.
Connor: We’re in California, true, true. I have to adapt to the culture more but yeah. ⬆
The Median Human Definition
Connor: So I think the obvious definition, a lot of people use, something and a system that can do anything a human can do as good or better. I think that’s a pretty reasonable… And not just one individual human, a system that can do any task, any human can do as good or better than a median human could, depending on which definition you want to use.
Michaël: Right, so it should be able to use a computer and go on the internet, but not code Ais.
Connor: Not necessarily, so I don’t like this definition for a few reasons. I’m sorry, I’m giving such an annoying answer, but I think this is actually kind of important to talk about. I’m going to give you basically four definitions or something, which are all right wrong but they’re all right in different directions. And if you kind of take the intersection or the union, you get something which kind of makes sense.
Connor: … take the intersection or the union, you get something which kind of makes sense. So this first one is pretty good, because it points out that we care about a thing that does things. So I don’t, for example, think it makes sense to define AGI by its architecture or by its internal calculations or how big it is or something like that.
Connor: I don’t think that’s really what we care about. So some people try to define AGI like it can’t be true intelligence if it doesn’t use method X. I don’t think that’s a good definition, because what we care about is does it do the thing or not? And then we can argue about what the thing is. So the reason this is not a good definition is because I don’t think it captures what I’m most concerned about.
Connor: So for example, I very much think there could be AGIs, that can hack any computer on the planet. That can develop nanotechnology. That can fly to Jupiter or whatever. But can’t catch a ball, because they just don’t put their computation into that.
Michaël: All right.
Connor: And then someone could say, “Aha, it’s not general. It’s actually narrow intelligence” And I’m like, “Okay, fine. Sure. But that’s really missing the point.”
Michaël: Thanks Gary Marcus. ⬆
The Not Chimpanzee Definition
Connor: Yes. So a different definition that also is not not correct. But I get to another nuances I like, which is one that I think Eliezer has pointed out in the past is, a thing that has the thing that humans do and chimps don’t. So chimps don’t go to the moon. They don’t go a 10th as far to the moon and then crash or something. They don’t go to the moon. They don’t build industrial society.
Connor: They don’t generalize to all these domains. They don’t develop biotechnology and computers and whatever. There is something that humans have that no other animal on the planet has. A lot of animals have various bits and pieces of it. It’s clear that chimpanzees use tools and they can have a very primitive sort of proto language, not really a language, but they have different grunts that different things and stuff and they can reason socially about each other.
Connor: I actually really recommend any AI research out there, read a book about chimpanzee behavior. It’s incredible how many people will make statements about how… And not just AI research, it’s also like philosophers of mind make statements about how animals clearly aren’t intelligent, because they can’t do X, Y, Z. And then you just read a book from an actual biologist that has worked with these animals. You’re like, clearly these animals do X, Y, and Z.
Connor: Chimpanzees obviously have theory of mind of each other. They can obviously reason about not just what are the other Chimp currently doing, but what does the other Chimp know about what I am doing? This has been shown in experiments. It’s very clear that chimps can do stuff like this. But chimps don’t go to Mars or the moon. Why not? So there’s something… Some general kind of capacity, which may be relatively simple.
Connor: So they might be a relatively simply arithmetic core, to the kind of general reasoning that humans do, which, again, some like… or Yann LeCun Schmidhuber might be bursting through my door right now like, “Well actually, not truly general because no free lunch or whatever.” Right? And like, Okay, sure, fine. Humans suck at theorem improving or whatever. Right? But we can build computers. So does it really matter? ⬆
The Tool Inventor Definition
Connor: So the definition I really like, which is this definition that Steve uses in this post, which may or may not be released, is he points out that some people say, well, like anything I would say this, and by the way, I am very sorry to anyone. I am misrepresenting you. Sorry Yan. Sorry Jürgen. I’m sorry if I’m misrepresenting any of you, guys not my intention.
Connor: But my understanding is they will say something, well, they’ll never be an agent that is, can do biotech and code AIs and catch a ball, and do blah, blah, blah. That’s computationally impossible. You’d be such going. I think that is true. In the limit, of course you can always find like, “oh, well it can solve NP hard problems can it?” And like, “yeah.” “Okay, sure, fine.” But what makes humans the best at solving protein folding is not because our brain is evolved to do protein folding calculations.
Connor: It’s because we invented AlphaFold. And I think that is at the core of what general, what AGI should mean. So AGI may or may not be good at protein folding, but it is capable of inventing AlphaFold. It’s incapable of inventing these kind of tools. Is it capable? It might not be good at doing orbital mechanics, but it can write a physics simulator and build a rocket. So I think that’s a good definition we should use-
Michaël: I think-
Connor: Which is not very strict. But… ⬆
Just Run Multiple Copies
Michaël: I think the main difference between humans and one AI agent, which is… Is that, genuinely, we are a bunch of humans on earth and we die. Some others come around and just invent new things. And we read books. So we’re not one agent. It’s more like billion agents doing stuff. And so when we create AlphaFold, it’s a team of people doing AlphaFold and all the other science we did before. If we program an AI, we train it on some data. Then we test it. It might invent protein folding, but not another thing. So it’ll need other iteration or at least be able to interact in the environment. Not just something that, it’s static and just like it’s trained and then tested. So it needs to… I guess that’s the main steel man I get from those guys. It’s just they think it’s impossible to do something very general that can learn any kind of problem solving.
Connor: Yeah. And I think basically there’s a failure of imagination here, is that they are pattern matching to how current AI systems look. They say AlphaFold, which is trained on one data set and it does one task.
Connor: But there is at least one existence proof of a system, which is trained on just a bunch of garbage just for the real world. And learns how to do all these things, which is humans. And you can say, “well, sure there’s multiple humans, whatever”. Yeah, that’s just run multiple copies, Lmao, or just build a bigger brain. The fact it takes 10 humans to develop AlphaFold or something’s just an implementation glitch in humans.
Connor: If we could just build a 10 times larger, single human or just have a giga von Neumann, he would just invent himself. He would need the team. He would need the other people. It might take him some amount of time. But if anything, the fact that humans have separate or separate entities and not just one giga-brain is just like an implementation flaw in the intelligence sense. It’s pretty clear to me that if you could just somehow pull all the compute, that would be better kind of strictly so-
Michaël: Right. And AI could just copy itself.
Connor: Yeah.
Michaël: And so the first definition is something like, what any median human could do? The second definition is what is different between a chimpanzee and a human basically like the different level of generality between a chimpanzee and a human?
Connor: Yeah.
Michaël: What are the third and fourth, if you still remember?
Connor: So the third was basically this Steve’s definition, which is a thing that can invent tools, which is kind of overlapping the second one.
Michaël: Okay.
Connor: And I do not remember what my fourth example was. I think it was that, it can do all economically relevant task or something, but I was actually going to bring that as an example of a bad definition, but I think we’re going to talk about that later. ⬆
AI Timelines
When Will We Get AGI
Michaël: Got it. Sure. We can talk about it later. So yeah. So just taking those definitions, just maybe the convex envelope of those, three or four definitions, when do you think we will get AGI? That’s a very controversial question. You can just give me very large intervals.
Connor: I mean, obviously the answer is, I don’t know.
Michaël: Right.
Connor: I have various intuitions or various inside views and various outside views on this is on. And these numbers might shift depending on what time of day you ask me or whatever. But generally kind of the mean answer I give people is, 20 to 30% in the next five years. 50% by 2030, 99% by 2100, 1% had already happened.
Michaël: It already happened, in some lab already?
Connor: Yeah. We just haven’t realized it yet.
Michaël: I can buy it.
Connor: I mean, that’s obviously a meme answer and I don’t read too much into that.
Michaël: No, no. But I could buy a world where we’ve already invented AGI and it just hidden…
Connor: Yeah, we’re just… We don’t realize it. We’re just staring at it and we’re like “Hmm, this thing seems weird.” But we don’t realize
Michaël: Oh, you mean we’re in a simulation?
Connor: No, no, no. It’s just… I mean, that’s also an option, but let’s not get into that bull shit. No, just like someone invented GPT-4 or something and they’re like, “mm-hmm. I mean, seems cute.” While in the background it’s doing something crazy and just like, “no-“
Michaël: Oh. Okay. Kind of a switch is turned- ⬆
Deception Might Happen Before Recursive Self Improvement
Connor: It’s like hiding yourself so we can. Yeah. Like a switch just turned is like already happened and it’s already in motion and we just are not all going to realize it until something crazy happens. Don’t read too much into that. I don’t… it’s mostly mean that. I say that just to raise the hypothesis to people’s attention. My error bars on these are all relatively large, but I take it. I do what is very important is I take it completely seriously, that we could have full on AGI in five years. I think that is an absolutely realistic possibility that we should all take completely seriously.
Michaël: Yeah. I agree that people don’t talk about it enough. And I think for me, I guess the main crux or the most important factor here is will this AGI thing be able to self-improve and become an even smarter version of itself very fast? So for me, I think the one concept that is more important is recursively self-improving AI could be a very smart version of copilot that creates copilot 2, or… Yeah. Do you have any definition for this, or even because I guess technically an AI could code another AI and we don’t have a very strong metric of what it means to improve itself. So is this something you’re think about or you consider when you think about those five years?
Connor: So I don’t think splitting on the axis of recursively self-improving versus not is a natural way to split things. I definitely agree if we have a system that’s like clearly self-improving, we’re probably fucked. But I think it is insufficient, but not necessary. Basically. I think also it’s not clearly defined, I think there’s lots of intermediate steps or for example, you have a system which may not be technically modifying its code, but maybe it kind of gradient hack, like it can change its training data.
Connor: It can train its internal gradients or maybe it can copy itself to more GPUs or something like that. So a pretty obvious example I could imagine happening something like… Okay, we have some system, it runs on… I don’t know ten A-100’s and it’s as smart as John von Neumann or whatever. Right? Or whatever, it doesn’t matter. And then… Or let’s give just an example. We have a logarithm that if run on A-100s is the smartest jump but running on 10, like some grad student. Right? And he looks saying like, “oh shit, this seems kind of stupid.
Connor: “ Well, I’m about to head in for the night. I’ll just run it on the big cluster and I’ll check in tomorrow. And then he runs in a thousand, A-100s and then it suddenly becomes giga von Neumann. And then before you even realize who knows what kind of things these things will learn or how it would act or whatever, it’s, I think a very important part of my model of thinking about AGI, is that there’s nothing inherently special about the point in intelligence axes of human.
Connor: It’s like we have z axis. We are of intelligence. And at some point we have median humans at some point we have John Newman or whatever. And there’s no reason that as we increasingly go from slug to bug to rat or whatever that as this continues, we naturally halt at the human thing. I think the difference between median human and John Von Neuman in the scheme of things is smaller than the difference between a reptile and a rat on whatever the scale means. So it’s very likely that if we have something that’s smart as a Chimp or something and, or as smart as a rat and we’re like, “looks lame as hell.” And then we run on a big computer.
Connor: It won’t stop at John von Neumann. It will just shoot right past that into some crazy regime that we don’t know what that would even look like or do. This is guaranteed to happen, of course not, look like no predictions are hard to make, especially about the future. Maybe this won’t happen. I don’t know, man, but this seems like the default, the null hypothesis. We don’t have any reason to not think this would happen. So we should just entertain the hypothesis that this is the default thing that will happen, because we just don’t have a good theory of how intelligence scales.
Connor: We have those scaling laws buts don’t really tell you that much. They tell you loss. But if I give you a loss number my model is 2.01, how good is it at math? The information isn’t contained in that number? Or, will it do a treacherous turn? It has lost 1.4 and you’re like, “this doesn’t mean anything. And it’s the kind of the things we’ve observed where even so the scaling of the losses are very smooth. The scaling on benchmarks can often be pretty discontinuous. It’s just like it has 0, 0, 0, 0, 0, 90%.
Michaël: Right. The performance on downstream task are yes. Discontinues. And I think, yeah, so you’re basically saying that, copying yourself on another server could be a convergent instrumental goal for an AI. And that might happen before you get… before you’re able to self improve?
Connor: It doesn’t even have to be the AI doing it. It could just be the researcher testing some new architecture or something. And then his test on is local machine. It doesn’t really perform that well. Or it seems totally harmless. And then they scale it up to the whole OpenAI cluster or whatever. And then suddenly just does something crazy. But what I’m saying is, this is not… ⬆
We Should Not Rule Out Scenarios
Connor: I’m not saying this is going to happen definitely or something. And what I’m saying is we can’t rule this out. My whole, this is like one of the main things, I like to stress. It’s not, I’m not saying, I know this is how the world is going to end. This is how AGI is going to happen. This is when it’s going to happen.
Connor: What I’m saying is, “Hey, here’s a bunch of scenarios that we can’t rule out.” I’m not saying they will happen, but we can’t rule them out. And I feel like a lot of critics of these kind of positions, seem to have the unnecessarily confident. They might say, “I don’t expect that to happen, in most not my high probability.” And that’s fine if you say “I have a 10% probability or 1% probability,” these things happen. That’s okay. I can argue about that. But 0% you have to be really God damn confident for that to be the case. You have to have some really strong, theoretical reasons to disbelief the same way I take seriously that it might be that all these things just aren’t a problem.
Connor: It’s just like either deep learning stop scaling or we hit some other roadblock or alignment just turns it out too easy. I think I assign some probability that those are true. That might be the case. I can’t rule them out. I can’t rule out. That it turns out a line is just easy or that scaling breaks. I can’t rule these scenarios out. I don’t expect them, but I don’t rule them out. And I kind of think that, the critics of AI safety and such should do the same is they should just like, kind of say like, “Hey, I can’t rule out that these scenarios would happen. Even if I think they’re unlikely.
Michaël: So if they were less confident about it, they would give you maybe 10% and they would start working on AI and then-
Connor: Well, I think if you give 10% chance that potentially the whole world could be destroyed in the next five to 10 years by this thing. This seems like a reasonable thing that… Okay. Even if you don’t want to work on that, I think we could maybe agree that it’s the whole field of AI alignment is 200 people maybe. And it feels like a few more people could be working on this problem. Just as an outside view, say you’re an alien observing a primitive species on another planet and like, “Hmm, okay. They’ve identified the problem. They have 200 people working on iy.” Again. Would the audience be screaming at the screen right now?
Michaël: Yes.
Connor: It feels like, I don’t think it’s that obs… That crazy of a proposition that maybe a few more researchers should take this seriously or at least not shit talk about it on Twitter. I think this is a pretty reasonable thing.
Michaël: Yeah.
Connor: Correct me if I’m wrong.
Michaël: Right. And I think when we talk about, taking it seriously there… We have even among those 200 researchers, pretty different view. So some people are more closer to the Effective Altruism movement might be more optimistic than you or even people working at, let’s say Antropic, OpenAI can be as bullish as us on scale, but still believe that we have 9% chance of getting it right. ⬆
Short Timelines And Optimism
Michaël: That really doing a good job with alignment research and even 200 people is good enough. So one report that came in 2020 was Ajeya Cotra reports trying to estimate what she calls transformative AI. So we can talk about the definition of transformatives AI, but basically is something that will happen before AGI. It is pretty significant for our economies.
Michaël: And I guess that puts some anchor into people’s timelines and they thought like, “oh, okay, that might happen in Ajeya Cotra report.” So she gives those numbers maybe like 2040, 2050. And she did a good job of trying to estimate the things. So I’ll give it five years less of, or 10 years less. But having a big jump for Ajeya report is basically being overconfident. So yeah, I guess a bunch of people in AI are anchoring themselves around those estimates. Maybe they updated with recent progress, but they don’t think that there’s 20 to 40% chance of getting AGI in five years. So I think there’s maybe less pessimistic and less bullish.
Connor: I think we should separate people’s timelines from how hard they think AGI is. The Ajeya report is fundamentally about when we should expect Transformative AI, which is a certain definition of a AGI, which I used to really like, but I now actually kind of dislike. We can talk about why. It’s not really about how hard alignment is or how high the probability of doom is. But I think you definitely put that correctly, that a lot of people in the EA sphere are way more optimistic about me, about how hard alignment is going to be. I think part of that is because of longer timelines.
Connor: If I thought I had 20 years of time to work on this or a hundred years to work on this, I would be way more optimistic. But so there is a correlation here, between these two factors, but I do think they’re separate. There’s also, you have very short timelines, but are still very optimistic and they tend to work at OpenAI.
Michaël: Right. So they’re Co-related, but I just like to make a distinction between two times, two kind of people were either very bullish on AI, short timelines but optimistic and people were longer timelines and maybe a bit more optimistic because they have more time and those people are not as concerned as you probably, and I guess not working maybe as hard or there’s not trying high risk startups. So yeah. ⬆
The Ajeya Cotra Report and Transformative AI
Michaël: Do you have any other thoughts on this report? Because you said you agreed with it at the beginning and-
Connor: Yes.
Michaël: Then maybe you have some disagreements?
Connor: Yeah. So I have some thoughts in that report. So first of all, I wanted to point out that I think it’s great that it was done. I am so happy that someone just actually sat down and just did the work. That is that report is like “Jesus Christ, that must have been a lot of work to put that thing together.” The amount of effort put into really exhaustively looking into every point, really writing down everyone, every assumption, every calculation, justifying things truly this is, this is the kind of stuff I love about EA and rationalism.
Connor: It’s just this kind of just taking an idea, whether or not it’s crazy and just really running with it. Just really going through the whole thing. So big props to Ajeya and everyone else who was involved in that report. I’m really glad it was done. I do disagree with the conclusion still. And so first I have a few problems with the definition of Transformative AI as the kind of thing we should be concerned about.
Michaël: Can we just define terms of AI-
Connor: Yes.
Michaël: If you remember the definition.
Connor: Yeah. So I think the definition for transformative AI was something like a system that can perform any economically valuable task a human in front of a computer could do, or a remote worker could do or something. And I think it helps out some definition about a certain percentage of the economical work. 50% of economical work could be performed by this AI or something like that. I don’t remember the exact definition. Unfortunately,
Michaël: The thing is more about its consequences on how much it could influence the GDP growth rate.
Connor: Yeah.
Michaël: The total GDP growth rate.
Connor: Oh Yeah. Yeah. That’s similar to Paul’s definition of slow takeoff, where he talks about… And also Hanson’s to some degree. So it’s good that you bring that up because… ⬆
Against GDP as a Measure of AI Progress
Connor: So one very strong opinion I have is GDP is absolutely one of the worst possible measures for AGI progress. And there’s very, very good reasons. We should never use it. John Wentworth, I believe wrote a very good post about this, or maybe it was Daniel Kokotajlo.
Connor: It was one of the other against GDP as a measure for AI progress. And basically, so there’s multiple problems. The obvious problem, the first problem, is of course that GDP is slow. It wouldn’t. It would only measure things that are taking go over years or decades, slowly integrate itself into economy and such, but even more importantly, GDP doesn’t really measure what most people think it measures.
Connor: If you actually look how GDP is calculated, it’s in a way kind of set up rather perversely, in that it kind of is designed to measure the things that don’t grow. The way it’s set up is that’s, you can look at current world GDP is definitely higher than it was several years or a decade or so ago. But for example, Wikipedia has zero impact on world GDP. I think Wikipedia is one of the most valuable artifacts ever created by mankind. Literally one of the most valuable things ever made.
Connor: And it has literally $0 impact on world GDP because it’s not a product and there’s no exchange of services or anything like that. This applies to software, to open source to knowledge, the internet. There’s this Phantom GDP that people think should exist. There’s all this value created by like technologies by internet, by open source and all this kind of stuff, which is just not in GDP.
Connor: So you can have people with… Or countries with GDP today, that are low middle income or low income countries that have access to the whole internet. But are by GDP measures know better often in 1970s. And so clearly if we were thinking about a powerful rapidly emerging digital technology that will change how things work that will scale and extremely efficiently, this is a pretty clear and it… And GDP can’t even capture the difference between living in India, 1970 versus living in some other it’s a middle income country today with access to the whole internet.
Connor: Clearly this is the wrong measure to be using. So that’s the one that’s… I think the main point of that post it’s explained better in the post than I explained here, but that I find that quite convincing. There’s also a separate point, which Eliezer brings up. I think at a few places, which I find somewhat compelling. ⬆
The Gradual Takeoff Scenario
Michaël: Was it the post about why it is wrong to reason about biological anchors?
Connor: Yes. I think he brings it up in that one. I don’t exactly remember, there’s a lot of Eliezer posts. And the point he makes is basically that because of regulatory slowness, because of the slowness of economy to uptake new technologies and stuff. What we will probably see is that the first AGI or powerful AI system that we actually see is the first one, who’s overcome a threshold, to be able to circumvent these systems. So this is one of the ways I think very fast takeoff could happen in that there actually is a… So this is one of the things where both Paul and Eliezer can be right, in this scenario, in this scenario, we have a gradual takeoff.
Connor: So we have systems that gradually become stronger across, but because of government regulation, because of corporate skittishness because of conservatism nothing’s ever released, because they’re like “oh no, it’s like, we have to first review this for five years or 10 years or whatever.”
Connor: And then, so the public doesn’t see any of this. So there’s thing ticking along in the background that the public doesn’t see. And then at one moment we have the breakout where some powerful system that escapes onto the internet or that can manipulate politicians or whatever to make itself able to spread or whatever. And then it will look this happened overnight, even. So it didn’t actually happen overnight. This is already the case. It’s… we surround ourselves with AI people.
Connor: We talk about AI and AGI all the time, but if you talk to Uber driver, he’s like, “what’s AI?” “I’ve never heard that word before.” It’s for most of the world outside of our tech bubble, they don’t know what the fuck a DALLE is. They don’t know what they don’t know, what a GPT is. They don’t know what any of these things mean. So I think from the perspective of many average people, even if there is a slow takeoff, it may very well, resemble a very fast takeoff. And I find this argument moderately convincing.
Connor: I think that’s a… Seems like a reasonable scenario that could occur. I’m not saying it will, but it’s like, again, seems like a pretty reasonable scenario. ⬆
Is Transformative AI Useful
Connor: So for these kind of reasons, I think the definition of Transformative AI is kind of… It has the benefit of being coherent. This is a thing I can talk and reason about, but it has the problem that I don’t think this is the actual thing we should be worried or care about. And that, I expect by the time Transformative AI is technically created, it may already be way too late.
Michaël: Yeah. I think there’s a couple of distinctions that you made that are interesting. One is, not everything is in GDP and Wikipedia. Maybe indirectly, because we used Wikipedia to train some models.
Connor: Yeah. Very indirect. Wikipedia obviously produces unimaginable amounts of value on the whole world. If you could measure how much it improves people’s education and ability to think. And so on, I would not be surprised if we could measure this, if it was trillions of dollars, I would not be surprised.
Michaël: Right. It is just like, if we have a world without Wikipedia and the world with Wikipedia, the world with Wikipedia will have a higher GDP? I believe.
Connor: Maybe, but I don’t know if that would capture everything. I think it’s possible. I expect that to probably be the case, but I’m not sure if that actually captures what we mean by the value of GDP above Wikipedia. I mean, yeah. I’m not saying I have a strong model here, but clearly something’s wrong about the way we measure.
Michaël: Yeah. And then I think this points out what we care about for our models. So if we have good data and good information on the internet, that’s like, we are the point where we can like train AGI train something very smart. And even if you’re not directly captured by something economic value for humans, it’s valuable for, to train our models potentially.
Michaël: And the other distinction you made is being private progress, stuff that are, happening in products or stuff that are just cool demos on the internet like Dalle, I talked to my Uber driver about Dalle to point at something where humans could be automated. I tried to talk to my designer friends like, “oh, have you seen this? You can just type a few words and now you can get a good design,” and they have no idea. Right. So there’s people on the streets then there’s people in tech and then there’s the people working on the model. So let’s say OpenAI employees who know stuff we don’t know about.
Michaël: And possibly we could get… They could know that we’re close to a fast takeoff. And we have no idea because we didn’t have access to the four models. So yeah, those posts were 2020, 2021. Those were answers to AGI Contra report. ⬆
Understanding Eliezer Yudkowsky
Michaël: But now in 2022, we had another debate between Paul Christiano and Eliezer Yudkowsky, as you might be aware of. One, the first post was by Elizer Yudkowsky, called… I think the first post was Die With Dignity. There was a troll post in April, but administrative, it counts to the debate. ⬆
The Late 2021 MIRI Dialogues
Connor: So arguably things started with the MIRI dialogues, which were-
Michaël: Right.
Connor: … a series of long transcribed discussions between Eliezer and various other people. Then there was the Die with Dignity post, which I would actually… to talk about maybe briefly, because I think I have a very different take than most people do on that post. And then after that we had the AGI Ruin post by Eliezer where he just kind of listed a bunch of reasons why you think we’re fucked. And then Paul made a very thoughtful response where he kind of goes through it and says why he thinks Eliezer’s strong about these kind of things. And these are… All, these schemes, they feel like a kind of tie together. I feel like Dying with Dignity kind of parallel, but I think there’s a thread between the dialogues to the AGI Ruin to Paul’s response.
Michaël: Right.
Connor: Which is kind of where we are now, Nate Soares has started to also add his voice in, but yeah, that’s kind of where we are right now.
Michaël: So which one did you want to, what do you want to go first? So we could just summarize the discussion for the long debate between-
Connor: I think that’s… That may be physically impossible.
Michaël: Right. This is too long. This is too long. So maybe, okay. So-
Connor: I think I… Okay. So-
Michaël: May be your take on the Die With Dignity, you said you had some… your take on this
Connor: Yeah. I could talk about Die with Dignity part. But let’s focus first on the arguments or the dialogues and the AGI ruin. And then I’m going to talk about Die with Dignity. Cause I have a few things to say about that.
Michaël: Go for it. ⬆
Paul Christiano and Eliezer
Connor: So, something very interesting, I think was going on. So in the dialogues between Eliezer and Paul. So there’s these huge long discussions between Eliezer and various other people among others like Paul, Rohin Shah, Richard Ngo, some people from OpenPhil and such. And one thing that I noticed reading the dialogue, I read the whole thing. It’s 60,000 words or something, but I read, I read all of it. And was… I found myself having an interesting reoccurring response, is that everything that people who are not Eliezer say seems to be more reasonable, but for some reason I think Eliezer is right.
Connor: And this was a bit of a dissonance inside of my head while reading the whole thing. I was like, “I’m on Eliezer’s side, but I really can’t explain why, because it seems all the other people are being way more reasonable than him.” I think I’ve mostly resolved this confusion since then. So I think the apotheosis. So, if you a dear listener read any parts of this, I would recommend you read the AGI Ruin post followed by Paul’s response to it.
Connor: Because the AGI Ruin post was objectively quite bad. I think Eliezer’s… I think it literally says that in the post, this is a bad post. And I think Paul’s response is very good. I think he makes a very, very good response to it. Also, Evan Hubinger has a very good comment, responding to the AGI Ruin post, which is also very, very good.
Connor: And really they make just a much better case than Eliezer about how he’s way too pessimistic. He’s dismissing all these other things he’s way too over confident in his views of how progress is made in these fields or such. And ultimately, I think, for example, Paul’s post is just a much better post than Eliezer’s on every objective measure.
Michaël: I think you could even just read Paul’s post because he gives the main point he agrees with Eliezer, right?
Connor: Yes. I would read both. And so that whole buildup was building up to a but. And here comes the but. But, there’s… Eliezer is a very interesting writer. I’ve always found reading Eliezer to be very pleasant. Some people like him, some people dislike him, whatever. Right? But something about Eliezer’s writing has always been very appealing to me. It’s been very easy. It doesn’t cost me energy to read Eliezer’s stuff mostly except the psychic damage from reading his fan fictions…
Connor: Except the psychic damage from reading his fan fictions. But I think one of the keys to understanding why I like Eliezer stuff and some people, others dislike it is that he has a certain way of writing, which is often more, almost metaphorical or more like fables, almost. He often talks in dialogues. He often tries to write things in non-technical stuff. While for example, Paul, is much better at like saying very concrete, well, no, depending on concrete, but very technical things. Trying to make predictions, trying to ground things and betting. One of the most frustrating parts of the whole dialogue is when Paul just tries to get Eliezer to bet on literally anything. He was like, “Eliezer, pick anything you want. I’ll make a prediction on it and we can just take.” And he just resists it and resists it. Like, “Oh, for God’s sake, Eliezer. What the hell are you doing, man?” So that’s where I think really, most people turned against Eliezer on that.
Connor: Well, Paul was having a silver platter. “Look, Eliezer, anything you want, just bet on it. And I’ll bet on it as well.” And I think they eventually found one tiny thing to bet on, but it was a real painful process. And that didn’t make Eliezer look good. Here’s Mr. Bayes himself. He was always, “Oh, you should always make bets.” And here he is not making any bets. And I can tell that’s, I think, a very fair criticism of Eliezer, that he didn’t do that, that he should have made bets.
Michaël: I think they both didn’t find anything concrete to bet on.
Connor: Yes.
Michaël: So it is very easy to say, “Okay, give me a bet and then I’ll make a prediction.”
Connor: Yes. And the truth is that is very hard to do. So I didn’t update as negatively as other people did. I was like, “This is actually a very hard thing to do. This is hard, to find bets like this.” But also, I see in this sense, Paul was being more traditionally rationally virtuous in a sense. ⬆
Eliezer Wanted to convey an Antimeme
Connor: Here’s my hot take. And I don’t know if Eliezer agrees with this or not. Eliezer, if by some chance you ever listen and you disagree with me, I’m sorry.
Connor: But my interpretation, I think a lot of people were missing what was actually happening in these dialogues or why Eliezer was saying the things he was doing. Again, this is just my interpretation. It could be completely wrong here. But I think what was happening is, was that Paul and Eliezer were actually having two completely separate conversations in parallel. And a lot of people pointed this out, it seemed like there’s talking past each other. And I think the reason this happened is because they had two different goals. I think what Paul was trying to do is, he was trying to talk like a scientist, to have a scientific disagreement, to try to find cruxes and whatever.
Connor: I think Eliezer had a different goal. I think what he was trying to do is to convey an antimeme. So an antimeme is an idea that by its very nature, resists being known. It’s something that if I tell it to you, you’ll forget it or you’ll want to forget it. Or it will not properly integrate into a world model and you’ll get a garbled version of this.
Connor: Antimemes are completely real. There’s nothing supernatural about it. Most antimemes are just things that are boring. So things that are extraordinarily boring are antimemes because they just, by their nature of what they are, resist you remembering them. And there’s also a lot of antimemes in various kinds of sociological and psychological literature. So a lot of psychology literature, especially early psychology literature, which is often very wrong to be clear, psychoanalysis is just wrong about almost everything. But the writing style, the kind of thing these people I think are trying to do is they have some insight, which is an antimeme. And if you just tell someone an antimeme, it’ll just bounce off them. That’s the nature of an antimeme. So to convey an antimeme to people, you have to be very circuitous, often through fables, through stories you have, through vibes. This is a common thing.
Connor: Moral intuitions are often antimemes. Things about various human nature or truth about yourself. Psychologists, don’t tell you, “Oh, you’re fucked up, bro. Do this.” That doesn’t work because it’s an antimeme for long. People have protection, they have ego. You have all these mechanisms that will resist you learning certain things. Humans are very good at resisting learning things that make themselves look bad. So things that hurt your own ego are generally antimemes. So I think a lot of what Eliezer does and a lot of his value as a thinker is that he is able, through however the hell his brain works, to notice and comprehend a lot of antimemes that are very hard for other people to understand.
Connor: I don’t think Eliezer is the greatest mathematician or the greatest scientist or the greatest whatever. And I think he would agree with that, that he’s not the greatest mathematician or anything like that. I think his value is in that for whatever reason, the way his brain works is de-correlated in certain ways from how most people’s brains work. And it allows him to pick up certain antimemes, which are valuable. And I think a lot of his frustration throughout the years, which he expresses very strongly in a lot of his writing, is because he’s been trying to explain antimemes to people, and it’s really fucking hard. If you read the Sequences, there’s a lot of obvious, “Okay, here’s how this thing works. Here’s how this thing works.” But so much of it is almost more like religious texts. Not in that it’s worshipful, but in that it’s metaphorical, it’s not supposed to be taking literal. You’re supposed to hear a story and then update on the vibe. You’re supposed to generalize from this scenario to other scenarios to learn antimemes.
Connor: And I think for example, with the Against Biological Anchors thing, what he was trying to do was to convey an antimeme, not to convey a prediction. Paul thought Eliezer is trying to weasel out of her prediction because he doesn’t have one. ⬆
Death With Dignity
Connor: Eliezer is trying to say, I have a valuable antimeme that people should understand and I’m trying to communicate it to you, but I’m failing because it’s hard to communicate. And this brings us to the Death with Dignity post. So the Death with Dignity post, you might say, “Connor, this sounds insane. What the fuck are you talking about? Antimemes? That seems ridiculous. I can’t think of a single example of an antimeme.” That’s the point.
Connor: But that aside, I have a perfect example. A real life living antimeme in full daylight for you to look at. And that antimeme is the Death with Dignity post. The Death with Dignity post is, in my opinion, one of the most perfect examples of an antimeme in broad daylight. So let’s talk about the Death with Dignity post. The Death with Dignity post is a very controversial post written by Eliezer where he kind of has his doomer mentality or whatever. He is like, “MIRI is shifting away from saving the world to, let’s die with as much of dignity as possible.” I mean, people say this is a troll post.
Michaël: It was posted on April 1st.
Connor: It was April 2nd, I think.
Michaël: Probably, he did it on April 2nd.
Connor: Yeah, something like that. I don’t know. So you’re like, “Oh, it’s April fool’s. Ha-ha, this is just a joke.” But no, really. It was a joke, but wasn’t really a joke. So my intuition, it’s not a joke, it’s an antimeme. So a great way to convey antimemes is through jokes. Comedy is one of the most effective ways to convey antimemes, especially social antimemes, things outside of the overtone window. One of the class antimemes is things outside of the overtone window. Humans will naturally resist just hearing and knowing things outside of the overtone window. It’s a natural way to create antimemes. And the what is so fascinating to me about that post, when I first read the post, my reaction, I think, was quite different from many other people in the EA and rationalist world.
Connor: My reaction was like, “Oh yeah, wasn’t that always the plan?” So I was just like, “I mean, yeah. Okay. Yeah, of course.” And I’ll explain why I had this reaction in a second.
Michaël: Maybe can you just summarize the main point?
Connor: I’m going to get to that. I’m going to get to that. So the surface level is that he says, “Look, everything’s so fucked. We can’t save the world, we should just try to die with the most dignity as possible, right.” And then he said like, “Instead of trying to focus on saving the world, we should focus on just dying with more dignity or whatever.” So that’s the surface level of that. That’s the non antimeme, that’s the packaging. The packaging is, “Okay, we should. Oh, we’re so fucked, I’m so depressed. Blah, blah, blah.” That’s the packaging. But that’s not the anti meme.
Connor: The antimeme is in a very, very hidden spot. The third paragraph. I’m joking, but I’m not. So why I love this post so much as an example of an antimeme is that he literally spells out the antimeme. Literally word for word, spells out what the antimeme is. And then the top rated comment completely misses it. It’s actually amazing. ⬆
Consequentialism Is Hard
Connor: So the antimeme in the post is that, so the surface aesthetic, the first two paragraphs or something are this, “Oh, we’re all fucked. Let’s all be depressed.” And then in the third or fourth paragraph or whatever, whatever the exact paragraph is, he explains what he actually means by this.
Connor: And what he means by this, is that gives his example. There’s a bunch of people in the rationalist movement and elsewhere who hear about the AI alignment problem. They hear like, “Oh well, things are so dangerous and we’re all going to die, blah, blah, blah.” And then they’re like, “Well, okay, we should blow up Nvidia. That’s a reasonable thing to do, right?” And like, “No, that is not a reasonable thing to do. You goddamn idiots, holy shit.” And the fascinating thing about this, so I have heard people seriously making this. So people are like, no one actually thinks this way. “Oh, there are people that think this way.” And I always have to tell them, so they’re like, “Well, Connor, if you are so pessimistic, why aren’t you blowing up TSMC?” And I’m like, “Oh my God, how can I explain to these people why this is stupid?”
Connor: The fact that you came to the conclusion that this was ever a good idea already shows that there’s something wrong with your thinking. So Eliezer diagnoses this thing the similar way to I do, is that utilitarianism and consequentialism is hard. Consequentialism is fundamentally hard. Consequentialism is the reasoning from consequences. Whatever makes the best consequences, that’s what you should do. This is fundamentally computationally hard. It’s different, for example, deontology. Deontology is just, you have certain rules and you just follow those rules. It’s kind of the difference between, P and NP in computational complexity theory. Evaluating your rules is always a constant number of steps, right. You just kind of, “Look at the world.” I have my like golden rule or whatever. I evaluate the rule and then I do that.
Connor: Consequentialism is fundamentally like NP. It’s much harder. I have to actually simulate all the outcomes of my possible actions and then pick the best ones. And this is arbitrarily hard. So if you are an ideal reasoner with infinite big brain energy, right, then of course consequentialism is the correct way to reason. Of course, it is, it’s obvious. But here’s the antimeme. So what happens is a lot of people, so humans are, by default, deontologists. Consequentialism is kind of unnatural to humans. Most people are deontological. And some people, some usually smart people, usually rationalist type people, hear about this great idea, utilitarianism, consequentialism. And they’re like, “Wow, this is obviously better. So I’m going to be a consequentialist now.” And on paper, that sounds great. But you can’t be a perfect consequentialist because it’s too computationally hard. So you’re always going to be an approximate consequentialist and that’s where everything breaks. ⬆
Second Order Consequences
Connor: So the diagnosis of why these people think blowing up TSMC is in any remotely way, a good idea that would not make everything literally worse, which it would, to be very clear is because they basically do a one step reasoning in a step. They’ll be like, “AGI bad. AGI need a GPU. Make GPU go away. Good. I did a consequentialism.” And I’m like, “If you’re not capable of doing one more step of thinking of the second order consequences of how this would destroy all cooperation possibility, this would destroy all goodwill. This would get militaries involved, this would get governments making things secret. This would make everything so much worse.” If you’re not capable doing this, maybe you shouldn’t be a consequentialist. And that’s the antimeme.
Connor: The antimeme is that what he’s trying to say is the deontological heuristic of try to do whatever maximizes dignity is much easier to compute. And his argument is if you already failed this first test, this shittier rule will make you more rational, will get you better outputs than you trying to use your broken consequentialism. Don’t be a consequentialist. Just take the heuristic, which is right 90% of the time, because otherwise you’re only going to be right 50% of the time. So it’s better for you to take the simpler heuristic of just taking this dying with dignity as a heuristic for generating your actions and you’re going to do better.
Connor: And then we have the top comment in that post from my good friend, AI_WAIFU, that’s his name, who I know quite well. He’s a great guy. He’s a great guy. He’s a very, very, very smart guy. I’ve known him for a while. And first, “Fuck that shit. Oh, I’m going to save the world. Oh, screw you. This is all terrible.” And I’m like, “Oh my God, this is an antimeme in action.” And I asked him afterwards, “Did you not read what the post said?” He’s like, “Oh no, I read the whole thing.” And I’m like, “Oh my God, this is an antimeme.” Everyone just did not see three-quarters of the post. It was just deleted from their memory. It was just amazing.
Connor: And I think this is a small look into what it is like to be Eliezer Yudkowsky. I think he has, not infinite, but he has a handful of really, really useful antimemes, which he’s been trying to teach people for 20 odd years. And some people pick up one of them or two of them. Some of them have now made it into the mainstream, alignment being a problem, that antimeme getting out there, but he has failed to teach all of them. And he’s now kind of, I think, given up and just, “Screw it.”
Michaël: Even if you get all the antimemes and you understand the post, I guess you can still be AI_WAIFU and not want to do low risk actions, following some dermatological rules. You might just want to take high risk and put all your energy into saving the world.
Connor: Yes. And the whole point of the post is that if you do that and you also fail the test of thinking blowing TSMC is a good idea, you are not smart enough to do this. Don’t do it. If you’re smart enough, you figured out that this is not a good idea, okay, maybe. But most people, or at least many people, are not smart enough to be consequentialist. So if you actually want to save the world, you actually want to save the world. If you want to win, you don’t want to just look good or feel good about yourself, you actually want to win, maybe just think about dying with dignity instead. Because even though you, in your mind, don’t model your goal as winning the world, the heuristic that the action is generated by the heuristic will reliably be better at actually saving the world. ⬆
The Dignity Heuristic for Reward Shaping
Connor: There’s another interpretation of this, which I think might be better where you can model people like AI_WAIFU. Modeling timelines where we don’t win with literally zero value, that there is zero value whatsoever in timelines where we don’t win. And Eliezer or people like me saying, “Actually, we should value them in proportion to how close to winning we got, because that is more healthy. It’s reward shaping.” We should give ourselves partial reward for getting partially the way. He says that in the post about we should give ourselves dignity points in proportion to how close we get.
Connor: And this is, in my opinion, a much psychologically healthier way to actually deal with the problem. So this is how I reason about the problem. I expect to die, I expect this not to work out. But hell, I’m going to give it a good shot and I’m going to have a great time along the way. I’m going to spend time with great people. I’m going to spend time with my friends. We’re going to work on some really great problems. And if it doesn’t work out, doesn’t work out. But hell, we’re going to die with some dignity. We’re going to go down swinging.
Connor: And I think that’s a much psychologically healthier way to think about. I have seen so many young people come into this field with this, “I’m an anime protagonist. I’m going to save the world.” And they burn themselves out in three months, do a shit ton of DMT and disappear. If you give yourself literally zero credit, the whole path, yes, if you were a perfect consequentialist reasoner, if you’re a perfect AGI that can think completely rationally about its goal. And there are some people that are like this, there are some people that are actually that rational. I can think of 2 5 people that are like this, maybe. And they can think like this, maybe. Even that I’m not sure.
Connor: But for normal humans, this is not a productive long term way to think about things. If you have to sprint for two months to get some shit done, okay. But if you have to do five years of soul crushingly, hard mathematical research, which may or may not work and you have little support from the outside world, you’re outside the overtone window stuff, this is not a sustainable way, a psychologically sustainable way for you to live your life.
Michaël: Yeah. I guess, there’s the AI_WAIFU case where you just try to speed run AI alignment. And you’re very optimistic. Then let’s say there’s the Paul Christiano view where you’re maybe more optimistic than Eliezer and you play for the long run. And I guess the vibe of Eliezer Yudkowsky’s post is really, really pessimistic. Basically 99%, or probability of one of dying. And then you just like win dignity points. And for most people, it’s also something bad because it’s kind of a doomer vibe.
Connor: Oh yeah, don’t get me wrong. I think Eliezer made a mistake in how he phrased this. He has many antimemes, he’s not the best at conveying them. I think Scott Alexander might be the best person conveying antimemes, but Eliezer’s not actually the best person at conveying antimemes. I don’t think he did a good job. I think he could have written a much better post. ⬆
Humans Cannot Reason About Quantum Timelines
Michaël: It’s not a critique of Eliezer because I agree that the antimemes are great and he conveys a bunch of information with his post. It’s mostly about, what’s the best way to work on the AI alignment? Is it to just assume you’re going to die with some high probability? Be optimistic? Or do you want to reason in the world where you’re still alive in 10 or 20 years? Or do you want to just assume you’re just going to earn dignity points? And I think for some people, maybe like for you, it’s better to just win dignity points. For some of the people, it’s better to just imagine themselves having kids and surviving.
Connor: Yeah. But the problem is: you’re now conditioning on false statements. You’re breaking your own epistemology. And that might work if you’re working in fucking sales or whatever. But if you have to solve an actually hard problem in the actual real world, in actual physics, for real, an actual problem, that’s actually hard, you can’t afford to throw your epistemics out the door because you feel bad. And if people do this, they come up with shit like, “Let’s blow up to TSMC.” Because they throw their epistemics out the window and like this feels like something. Something must be done and this is something, so therefore it must be done.
Connor: And the same thing happens, it’s like, you can condition on many things and there are many things you can condition on. But if you condition, for example… one of the things you just mentioned is like, “Okay, how about we just play for the timelines where we win?” Right? The human brain can’t reason about quantum timelines. And by doing that, you’re predictably shooting yourself in the foot. You don’t actually have a probability estimate of what will happen in the future. Of course, you don’t.
Michaël: What do you mean by quantum timelines?
Connor: Timelines, right? Possible timelines. I say quantum, it doesn’t matter. It have to be quantum timelines, just possible timelines, right. From here on, there’s possible timelines that could… some of them go well, some of them don’t, right. And now you might say, “Okay, let’s only reason about the ones where we win.” ⬆
Dignity in Culture and Dark Arts
Michaël: It’s mostly for an EA, if you want to think about your impact. If you think you have only two or three years, five years, let’s say before AGI, and you condition of short timelines and you say, “Oh, this is looking pretty bad. I should probably like bomb Taiwan.” You’re going to do bad actions. So instead, you might just want to condition on 10 or 20 years. So then you can change your career and have an impact in the future.
Connor: Sure, you can do that. Obviously, if that is your response, that you should bomb Taiwan, then obviously don’t. And if that is your only option, fine, but obviously, the superior option would be condition on timelines without going crazy, without galaxy braining yourself into doing stupid shit. And I think Eliezer argues that a simple way to do this is just try to condition on the dignity prior. Just try it, just give it a shot, and see how it works for you, because it’s actually a very natural human prior to think about dignity. The concept of dignity has a very, very long history in human literature and psychology and culture. Ancient cultures have talked about dignity extensively.
Connor: For a very long time of human history, that was one of the main topics that you would talk about. And so it’s actually a very natural thing for humans to think about. But somehow, rationalists have galaxy brained themselves outside of all of this. And you’re correct. Maybe for some people, maybe for most people, the stress is just too much and you should just hope for the better, go find a farm, find a wife, have a good life. And if you do that, I wish you all the best. Seriously, I do. I really do wish people the most. I always tell my friends, “Get married, have kids.” If that’s what makes you happy, do it. But also, don’t delude yourself, or at least don’t get in the way. If you say you can’t work on the problem, okay. But at least also don’t become Yann LeCun and then try to get in the way of the solutions.
Michaël: Yeah. I think there’s some meme in entrepreneurship of “fake it until you make it”, or something where entrepreneurs try to delude themselves that they’re CEOs until they actually have a company.
Connor: Yeah. I think there is something to be said about this stuff. This is what I think rationalists would call dark arts. And my recommendation on what you should write read there is Nate Soares’ blogs, Minding Our Way To The Heavens. And his posts like detaching the grim-o-meter and several other posts like that, where he talks a lot about basically how to approach things with dark arts without going completely insane, hopefully. I find these posts he’s written very helpful personally. Because there are ways you can not get super depressed about things while also not galaxy braining yourself into blowing up Taiwan.
EleutherAI
Michaël: Gotcha, I will. I will read those, I think on EleutherAI, so the Discord server you co-created, we have maybe two camps, the more like alignment side or maybe more doomer, more Eliezer side, and maybe some people more building large language models that are less concerned, maybe, about alignment. And so one of the things you did was create the server and bootstrap a little bit the server at the beginning, maybe now it’s a smaller part of your time. And it has been slightly controversial in the larger community if the impact of Eleuther AI as a whole has been good because you could summarize it, but essentially, it sourced “The Pile”, so a lot of datasets to train GPT-3 like models like GPT-NeoX and GPT-J. And you also open-sourced GPT-J. Not really EleutherAI, I think it was mostly like Ben Wang and Aran Komatsuzaki.
Connor: Yeah. Who were members of EleutherAI, but it was mostly those two. It was mostly Ben.
Michaël: Yeah. So yeah, I guess because this podcast will be watched by people from the AI Alignment community and the EA community, do you want to maybe address the concerns people have mentioned over the years about Eleuther AI?
Connor: Yeah. I would really love to. I mean, so one thing I would like to say very well up the head, obviously, I don’t know. Did I do the right thing? Did everything go exactly as planned? Of course not. Are there things I would do differently? Of course. It would be surprising if that was not the case. But overall, I think, there’s a few things. There’s a lot of details and nuances, I think, about EleutherAI that kind of get garbled in most telling of the story. So I think there are completely fair arguments to be made that maybe EleutherAI was a bad idea. Maybe you shouldn’t have done that, et cetera, et cetera. I think there are also good arguments for why it was a good idea or why it did work out. I obviously think it was a good idea and it was net positive. But there are reasonable people who disagree with me here and I can understand us disagreeing on this.
Connor: So if you disagree with me on this, I don’t think you’re insane. I think you’re wrong, but I don’t think you’re insane. And to explain a little bit about why I think this. So we have to think back to like a pretty different time when Eleuther AI was first created. This was back in 2020 and the alignment community hadn’t really updated yet on scaling.
Michaël: Basically, you kind of created the antimeme of scaling with Eleuther AI.
Connor: There was a bit of an antimeme going on there and also some normal meme-ing. But in a sense, so I talked about this a bit earlier already, how I had these really strong updates. Eleuther, it first started just me and some friends dicking around, right, which I think is a perfectly healthy and harmless thing to have happen. Some hackers dicking around and a discord server, having some fun, programming some stuff. I think it’s a good and healthy thing that is good, but we didn’t expect to get anywhere. We were making little toy models and we were just having fun. It was the pandemic, we were bored to tears, it was good for all our mental health, right. ⬆
Misconceptions About the History of Eleuther
Connor: One misconception that often comes up with the Eleuther AI is that we were not always alignment concerned, that someone convinced us or someone proselytized to us or changed our mind or something. This is completely false. This is that could documentarily wrong in the sense that I replicated GPT-2 a year prior to EleutherAI and wrote rather cringey, but interesting blog posts where I explained my exact reasoning about why I did this, why I think this is good. I linked to lots of lesswrong posts and lots the things why I think this is important for alignment or whatever. And also I changed my mind. It was actually Buck Shlugeris who’s CTO of Redwood now who changed my mind about releasing it back in the day. And I read a long post being like, “Okay, yep. I was a fucking idiot. This was a bad thing. And I’m sorry about that.”
Connor: But I think there’s nuance to why I decide not to release GPT-2 that then did not apply, at least not in the same capacity to what we’re doing at Eleuther. I’m going to get to that in a second. So basically from day one, we always took alignment seriously, at least I did. So I always had alignment in mind. And my reasoning was that when GPT-3 came out, I was already primed by GPT-2 and such. I looked at this and I was like, “Holy shit.” We have to pivot. Alignment needs to work on this. This is the thing we need to work on. And now everyone talks about Large Language models. And everyone talks about scaling. It’s like all over the alignment form and stuff. But back then, it was me and Gwern. No one else really in the alignment sphere outside of OpenAI was taking scaling and these kind of stuff very seriously.
Michaël: Well, I guess there was this post about, are we in AI overhang? I think it came out in 2020 where people realized that you could just scale GPT-3 and make even bigger models. And it got a bunch of upvotes. I think it was curated.
Connor: There were some. So Gwern deserves a lot of the credit for really spreading the scaling meme in the alignment community. So I think probably Gwern deserves more credit than EleutherAI, for example, does in spreading this meme in the alignment community. So thank you for your services. Also, please start working on alignment, Gwern, I beg you, instead of whatever anime shit you’re doing.
Michaël: Please, Eliezer easier stop writing glowfic as well.
Connor: Yeah, yeah. So for me, from the very beginning, I saw, “Wow, these models are important.” We have to understand these things. We have to understand their scaling properties. These emerging capabilities are important. Interpretability is incredibly important. And I basically saw an arbitrage opportunity. So the way these models work is you have a training phase, which is very expensive and very engineering tricky. It’s very tricky. But then once you’ve done that, using the model for fine tuning or generation or doing interpretability is much simpler in comparison. It costs much, much less money. So I basically saw an arbitrage opportunity is that there were a ton of people who I think should be doing research on these models, but clearly did not have the engineering and funding to build these models themselves. So I had a bunch of nerds who wanted to do this for fun anyways, and we had access to some hardware from various sources.
Connor: So maybe if we just did this one time investment, we could have this leverage of many groups using our models in our work to do research. And also in the process, we will gain something very valuable, which is tacit experience with working with these kinds of models, which I think to this day, a flaw or a big mistake that a lot of people in the rationalist and alignment community, not everyone, but quite a number of people do, is undervaluing practical experience, hands on, actually touching the thing. There’s an illustrious scientific history of the method of just staring at an object very hard. And that I think is sometimes unfairly maligned. ⬆
Why GPT3 Size Models Were Necessary
Connor: Well, I remember having these conversations with some people in the alignment sphere, it’s like, “Oh well, why did you build the models? Just use GPT-2, that’s fine.” I’m like, “Well, okay, what if I want to see the bigger properties?” “They’ll probably exist in the smaller models too or something.” And they’ll be like, “Name three experiments you’re going to do with this exact model.” And I’m like, “I could come up with three, sure. But that’s kind of missing the point.” The point is, we should just really stare at these things really fucking hard. And turns out, my experience, that was a really good idea. Most of my knowledge, my competitive advantage that I have in other people is gained from that period of just actually building the things, actually staring at them really hard and not just knowing about the OpenAI API existing and reading the papers. There’s a lot of knowledge you can get from reading a handbook, but actually running the machine will teach you a lot of things.
Michaël: Yeah. So I agree that to understand the models and how to align them, how to steer them correctly, you might want to implement them yourself or replicate the SoTA. And I think that’s one of the main arguments in the alignment research literature. Like, “Oh yeah, please build this stuff. And then you can interpret it and align it.
Michaël: However, some people working at Anthropic might say that you can still reproduce a SoTA and do private research, not open-source the models. And then do maybe public alignment research.
Michaël: And what EleutherAI did was, everything was open-source and everything was things people could use to train their models. So it kind of accelerated AI timelines for everyone.
Connor: Yes. I think that’s completely false, but I’ll explain why. I think there’s a very toxic meme that exists in the alignment world right now. Not everyone.
Connor: I agree that in the ideal case, the correct case, is for large well-funded groups to do AGI research internally and never fucking tell a soul about it. I think that is the correct way to do it. I think what Anthropic, for example, is doing is good. Even so I disagree with many other things and I have some problems with OpenAI. Fundamentally, a lot of what they’re currently doing is good.
Connor: I think their alignment research is problematic for several reasons, but the idea of… Some people are, Ugh, OpenAI not publishing GPT-3. I’m like “I wish they didn’t even publish the paper dude. I wish they didn’t even publish the goddam paper.” ⬆
Why Only State of The Art Models Matter
Connor: So one of the important parts of my threat model is that I think 99% of the damage from GPT-3 was done the moment the paper was published. And as they say about the nuclear bomb, the only secret that it was, that it was possible. And I think there’s a bit of naivety that sometimes goes into these arguments, where people are, well, EleutherAI accelerated things, they drew attention to the meme. And I think there’s a lot of hindsight bias there, in that people don’t realize how everyone knew about this, except the alignment community. Everyone at OpenAI, everyone in Google Brain and DeepMind, people knew about this, and they figured it out fucking fast.
Connor: They were, well, EleutherAI accelerated release of open-source models. And I’m, let’s just look at what happened. BLOOM just got released the other day, which was Big Science’s big model. Meta released their OPT, 175 billion model a few months ago.
Connor: This was always going to happen. There was never a question of… there’s no counterfactual world in which EleutherAI didn’t exist, where OPT didn’t get released. That’s not a counterfactual, if that makes sense. But even more so, there’s a lot of contingent factors about how things were done. There’s one thing I do agree about EleutherAI, and I think in retrospect was a mistake, and that mistake was releasing The Pile.
Connor: So this was actually a surprise to me. So when we created The Pile, I expected “who’s going to care about this” right? Maybe a few academics will use this to save them some time when they’re doing some experiments or when they’re… There’s reasons to want to release the dataset, to understand what do the things actually learn, wise memorizations, there’s lots of reasons to release the dataset.
Connor: And so I don’t know if I regret it, but if I regret one thing or if one thing did increase capabilities, it was releasing The Pile, not GPT-NeoX or GPT-J. I don’t think those really mattered, because none of those were ever state of the art. EleutherAI made very clear from day one, is that we would never release something that is state of the art or beyond the state of the art. We were very clear about this. If we ever stumbled upon something that was beyond anything anyone else had, we would not release it.
Connor: And part of my threat model is that I expect all the danger basically to happen from the cutting edge. So if a 200 billion model exists and someone has a 20 billion model, I don’t think the existence of the 20 billion model significantly changes the speed of the frontier.
Michaël: Right.
Connor: I think there’s arguments against that, but… ⬆
EleutherAI Spread AI Alignment Memes
Michaël: I agree that most people at Google Brain or DeepMind started scaling after the GTP-3 paper. They didn’t wait for the GPT-3 demos in July. No, they were scaling stuff before.
Michaël: So I agree with this. And so you have a server with 1000s of kids, or maybe researchers looking at scaling memes. So maybe they get a little bit more into scaling.
Connor: Oh yeah. I think that…
Michaël: A little bit more. So just like memes.
Connor: Oh yeah, I think there’s absolutely a world in which EleutherAI is not negative. I do not want to deny that.
Michaël: Sorry. I guess the end of my sentence is that they also look a little bit more into alignment. And if they’ve never heard of alignment before, and they heard about scaling because they’ve got their coworkers talking about scaling models, then they get maybe 5% more into alignment.
Connor: Yep.
Michaël: So I think that’s an argument for why it’s positive.
Connor: Yeah. So one of the things that EleutherAI did, and this was very much intentional, is that it created a space that is open to the wider ML community and their norms. Is respectful of AI researchers and their norms. And also we have street cred, in that, the sense that we are ML researchers and we’re not just some dude talking about logical induction or whatever, but still has a very strong alignment meme. Alignment is high status. It is a respectful thing to talk about, is a thing to take serious. It is not some weird thing some people in Berkeley think about. It is a serious topic of serious intrigue. And for what it’s worth of the five core people at EleutherAI that changed their job as a direct consequence of EleutherAI, four went into alignment.
Michaël: And I think most people I talked to were into ML, people at Google Brain or OpenAI, they all know about EleutherAI. Even people in the AI art community, they know about EleutherAI because you did art. But most people don’t know about Eliezer Yudkowsky, they have problems pronouncing his name, and I kind of get what they mean.
Connor: Yes.
Michaël: So I think you made possible this kind of “chad alignment researcher”. Before that, there was, oh, this is a crackpot on the internet talking about it. And now it’s more into the mainstream. You can talk to the engineer, to the actors.
Connor: Yep.
Michaël: That was pretty good.
Connor: And that was very much intentional, in the sense that… For me, it was always clear that alignment is chad. Obviously this is the coolest problem in the world to work on. Alignment is the coolest problem. And it suffered a lot and still suffers a lot, I think, from an image problem. In that, there’s just a lot of cultural disconnect between the ML world and the alignment world. For various historical reasons. ⬆
EleutherAI Street Cred and the ML Community
Connor: And EleutherAI had this cool, which I very much enjoyed, this overlap, where we’re legit. People in the ML community really respect EleutherAI. They look at EleutherAI and think, oh yeah, these guys are legit. This is real street cred. And then they also say, well, these guys take alignment really seriously. Well, maybe we should take it seriously too. Or at least think about it.
Connor: I’m not saying, was it a resounding success? Did it do everything I wanted? No. It could always have been better. But I like to believe that there was a positive magnetic contagion that happened there. As I say, a lot of people that I know, that were an ML, started taking alignment seriously. I know several professors at several universities that’d gone to EleutherAI through the scaling memes, and then were convinced that this alignment thing seems important potentially.
Connor: I know, you can always argue, maybe they would’ve come to that conclusion without EleutherAI or whatever. But I think there’s a lot of positive there. So my completely biased assumptions, obviously I’m biased here, I try to be objective, but these are my friends, right?
Connor: So of course it’s going to be biased, you’re not trying to ignore that. But my view is that I think EleutherAI is a good thing. It allowed, I think a lot of positive memes about alignment to spread. EleutherAI is not really EA culture. It has a lot of DNA of EA and rationalists. A lot of rationalists in the DNA, but it’s its own thing. It’s like a mutant offspring between the ML world and the rationalism world, that bridges the gap quite nicely.
Connor: I think this is a nice culture or nice set of memes to exist in the world. I think this is a positive thing that these memes exist. I think other people might say, no, these are bad memes and these shouldn’t be spread. And I can’t objectively argue that one way or another. But I think there’s an argument to be made that a lot of good things came out of it. And it led me to where I am today. ⬆
The EleutherAI Open Source Policy
Michaël: So I guess there are other ideas, that were spread from it. One is open-sourcing is good. Open-sourcing models is good. GPT-3 was not published. Oh, let’s do it instead of them.
Connor: Which is not our official position, to be clear. That was never our official position. It is what people thought our official position was. Our official position, which you can read in our blog, which has always been there, is that not everything should be released.
Connor: And in fact, we EleutherAI discovered at least two capabilities advancements ahead of anyone else in the world, and we successfully kept them secret, because we were like “oh shit”. So the one is the chain of thought prompting idea, which we then did later publish. I believe I showed Eliezer the pre-draft. So he may be able to confirm that I’m not bullshitting you on this. I think it was Eliezer that I showed that to.
Connor: And so in that regard, I fully understand why people think this, because that’s a default open-source thing. And there’s several other open-source groups now, that have split off of Eleuther or they’re distant cousins of Eleuther, that do think this way. I strongly disagree with them. And I think what they’re making, that is not a good idea. It was always contingent.
Connor: EleutherAI’s policy was always “we think this specific thing should be open”. Not all things should be open, but this specific thing that we are thinking about right now, that we’re talking about right now, this specific thing we think should be open for this, this, this, this is the reason. But there are other things which we may or may not encounter, which shouldn’t be open. We made very clear if we ever had a quadrillion parameter model for some reason, we would not release it.
Michaël: But just to push back a little, that model, that open-source were GPT-J and GPT-NeoX, that were smaller than GPT-3, but still close to SoTA. So you said something about state of the art, but I believe GPT-J, in terms of open-source was SoTA on coding, at least when people released Codex, I think GPT-J had maybe 5% to 7% on some benchmark when like GPT-3 had 0%. GPT-J is cited in the Codex paper as state-of-the-art in coding. Because The Pile has some github code, I think.
Connor: That might be possible. I don’t exactly remember the exact benchmarks there, but we did experiment a lot of this stuff. It wasn’t at the state of GPT-3. GPT-3 was still better at most of these things. I think GPT-J may have performed slightly better on some benchmarks or something.
Connor: So when I say SoTA, I don’t mean open-source SoTA, I mean private SoTA. And there was a ton of stuff that was way ahead of it. I do agree… Again, I want to be very clear here. It may have been a mistake to release GPT-J. It may have been a mistake. I don’t think it is, one, for various contingent reasons, but I’m not ideologically committed to the idea that this was definitely the right thing to do.
Connor: I think given the evidence that I’ve seen, for example, GPT-J being used in some of my favorite interpretability papers, such as the Editing and Eliciting Knowledge paper from David Bau’s lab, which is an excellent paper, and you really should read, which used GPT-J. And several other groups such as Redwood using GPT-Neo models in their research and such.
Connor: I think that there is a lot of reasons why this was helpful to some people, this was good. Also, the tacit knowledge that we’ve gained has been very instrumental for setting up Conjecture and what I do now. So I think there are reasons why it was good, but I could be wrong about this. Again, if people disagree with me about that, I think I disagree, but I think that it’s not insane. ⬆
Current Projects and Future of EleutherAI
Michaël: Got it. But let’s move on from this. So do you want to still talk about future of EleutherAI? Would you prefer to talk about Conjecture?
Connor: Yeah. So the future of EleutherAI is… It’s different now. A lot of people or all the original people have moved on from EleutherAI. Some people got jobs, some people are working on different projects now.
Connor: It’s still a pretty active community. It’s still a great place to read up on current literature or have some cool discussions about alignment. It’s probably my favorite place to just have live chat discussions about If you’re very technical. If you want to really talk about real technical alignment, it’s one of the best places you can go. We have a bunch of cool regulars that jump in and out of various conversations there.
Connor: So it’s really still a nice place I like hanging out a lot. It’s very intelligent, lots of good stuff. There’s some interesting projects there, but it’s much slower than it used to be. There’s not as much frenetic energy at the moment. We’ll welcome it, if anyone wants to come in and start bringing back some frenetic energy, we’re very welcome for that.
Connor: We have way more resources nowadays, than we did back in the day. It’s ironic that we have a lot of resources, but less energy, because older people have jobs now, things are a bit different now. We have a lot of compute, that we’re happy to share with alignment researchers or people working on interpretability projects or stuff like that.
Connor: If you’re working on an interpretability project or an alignment project and you’re bottlenecked because you can’t get the compute to train a large model or something, literally hit me up any time and we’ll figure something out. We have access to quite a lot of compute, that we are happy to work with.
Connor: And will we continue to build larger models and release them? I don’t know, maybe. We have the resources now to do it. I’m not sure if anyone… We probably… Nah, I don’t know. We might, we might not. If someone feels like it, if someone puts in the energy, because there’s still has a lot of damn work to retrain those things. It’s just a lot of babysitting and a lot of annoying stuff. I think it’s possible, we might do that.
Connor: Again, of course not pushing the state of the art, since now at least two GPT-3 size model exist. Maybe we’ll add a third. No, no promises there whatsoever. But EleutherAI is still a nice place.
Michaël: Is there any alignment work going on or research? I know at some point people were trying to speed up alignment research there.
Connor: Yeah, that was a project led by Janice as part of the AI Safety Camp that released the data set, including all alignment work ever done and stuff like that. So there’s a few projects like that. That project’s wrapped up now.
Connor: There’s a few interpretability project that I think Stella has been working on. I used to be involved in alignment research there, but that has now moved to Conjecture. And maybe this is a great segway to talking about what I’m currently doing, which is Conjecture.
Conjecture
Why Getting Things Done Was Hard at EleutherAI
Connor: So Conjecture grew a lot out of some of the bottlenecks I found while working in EleutherAI. So EleutherAI was great. I love the people there and such. Anyway, we had a lot of great people and such. But if you wanted to get something done, it was like herding cats. But imagine the cats also have crippling ADHD and are the smartest people you’ve ever met. Especially if anything boring needed to get done, if we need to fix some bugs or scrape some data or whatever, it would very often just not get done.
Connor: Because it was all volunteer based, right? You wanted to do fun things. It’s your free time. People don’t want to do boring shit. During the pandemic it was a bit different, because people literally didn’t have anything really to do. But now you have a social life again, you have a job. And then you don’t want to come home and spend two hours debugging some goddam race condition or whatever.
Connor: So it was hard. I ran into bottlenecks when working with EleutherAI. One of the hopes I had when I started EleutherAI, I was wow, this is going to be a great research org. And we’re going to do all this research and stuff. And it’s, oh you have to actually pay people to do things sometimes.
Connor: So this led to Conjecture. So Conjecture is our AI alignment startup that I founded together with Sid Black and Gabriel Alfour, two people who I’ve met through EleutherAI. Sid is one of the co-founders, Gabriel is someone who I met through EleutherAI. And we started this company to… Well, to tackle the alignment problem head-on. And just to get over some of the bottlenecks that I found in EleutherAI, for example, paying people to actually do things, which is a great way to motivate them.
Michaël: And if I recall, you met both Gabriel and Sid back in 2020.
Connor: Yes, that’s correct.
Michaël: And when did the idea of creating a company together come around?
Connor: So, finally Gabriel suggested we should do a company two weeks after I met him or something, which is very funny.
Michaël: Yeah.
Connor: Gabriel’s a great guy. The one thing about Gabriel is whenever he predicts something and I predict the opposite, he’s always right. So he predicted we would do a company and I was, no, that’s ridiculous, I couldn’t do that. And he was, oh, okay, we’ll see. And then… Well here we are. ⬆
How Conjecture Started
Connor: So, the idea was first floated very early in EleutherAI, but I put that completely on ice. I didn’t want to do that. I wanted to just focus on open-source and such. So it became really concrete around late 2021, September, October 2021, I think, when Nat Friedman who was the CEO of GitHub at the time, approaches EleutherAI and says, hey, I love what you guys are doing. It’s super awesome. Can help you with anything? You want to meet up sometime?
Connor: And to add to his credit, he donated a bunch of money to help EleutherAI to keep going. A man of his word. And he happened to be in Germany at the time, which was where I was as well. And he was, hey, do you want to meet up for a coffee? And so we met up, really got along, and he was, hey, you ever thought of doing a company or something? Now, I have been thinking about that. Why don’t you just come by the Bay sometime and talk as such. And so I was thinking, oh cool, I can go to the Bay and I can…
Connor: So this is at the time… So it was a confluence of factors, right. It was an excuse to go to the Bay to talk to both Nat and his friends, but also talk Open Phil and potential EA funders and stuff like that. And also, I was getting on EleutherAI, I was hitting those bottlenecks I was talking about, where I was trying to do research on EleutherAI but it just wasn’t working.
Michaël: And you also had a job with Aleph Alpha
Connor: I also had a job at Aleph Alpha at the time where I was also trying to do research. And I did some research at Aleph Alpha, but I found it also to be bottlenecked by various factors, because I wasn’t really in control, I didn’t have access to any amount of resources I might have wanted and such.
Connor: So there was a few bottlenecks there that just were hampering how much progress I could make on the research I want to do. Also, Aleph Alpha wasn’t super aligned on the kind of research I wanted to do. They were open to my ideas and that kind of stuff I wanted to do, but they weren’t 100% on board with what I wanted to do. I wish them all the best. But I just didn’t think this was the best place for me at that point.
Michaël: And so you went into the Bay and you met Nat’s friends?
Connor: Yeah, I met Nat and friends. And so what happened is basically, so I was young, bright-eyed EA, and I was, okay, great, I’m going to make an AI company. I have all these people from EleutherAI, who are just super, super great. Arguably some of the only AI people in the world outside of big tech companies who’ve built and trained large models, Sid is an absolute wizard. He is single-handed responsible for most of GPT-NeoX. And also probably most of Neo. Truly just incredible stuff.
Connor: And there are several others, just really great EleutherAI people on board with this idea, who want to do something like this. ⬆
EA Funding vs VC funding
Connor: So I was like, oh, well yeah, I’ll go to Open Phil. Everyone keeps saying there’s so much money in EA, and there’s nothing they can fund. Surely they will fund me.
Connor: So OpenAI… Open Phil, sorry, had some understandable concerns. They were, well, we don’t really know you that well, you’re asking for a lot of money. Your research is a little weird, the whole EleutherAI Copenhagen Interpretation, blah, blah, blah. You did some things in the past which we disapprove of, which it’s fair, I understand. So they were a bit hesitant.
Connor: But then I went to the VCs and they were, yeah, you’re cool. Here’s a ton of money, do whatever you want. Not literally, but kind of like that. They were, yeah, you’re awesome, you’ll do some cool shit. Let’s do this, let’s try some cool shit.
Michaël: I guess the difference between VCs and Open Philanthropy is that Open Philanthropy is trying to have a positive impact. Whereas VC maybe thinks about profit a bit more and they see the potential of a company with a bunch of bright people that come from EleutherAI.
Connor: Yeah.
Michaël: And you as a CEO and the co-founders… So I think there’s different ways of looking at it.
Connor: Oh yeah, yeah. As I said, I fully understand the Open Philanthropy view here. I’m not saying, oh, they’re so insane. No, this is a very reasonable thing. I may have, well, not funded myself in this situation. I think I would’ve actually, because I’m more risk tolerant.
Connor: But as institutions are, you have to be conservative. Your reputation’s at stake and such. You have to be way more conservative. VCs can afford to have things blow up. But for example, for Open Phil, they’re very concerned about their reputation. So it’s really important that they don’t invest in something that blows up, that looks real bad. So I fully understand.
Michaël: And would you want to maybe mention the different investors, VCs, or funding? Or is it just something private that you might prefer not to talk about?
Connor: Yeah. I’ve said it in the past. So it’s Nat Friedman, his friends, Daniel Gross, Patrick and John Collison, were the main investors. We also got some smaller amounts of money from various other sources, like Arthur Breitman, Andrej Karpathy, Sam Bankman-Fried, all put in various amounts as well.
Connor: So Sam came in really late because FTX Future Fund didn’t exist when we were raising the first and at the very end, the Future Fund came around, oh, can we leave a little bit open in case Sam wants in? And then Sam wanted in. So he invested a small amount towards the end as well.
Michaël: That’s a good strategy to just always leave a window open for Sam Bankman-Fried.
Connor: Yeah. We left a little bit open and then he… It was very kind of him to decide to invest a little bit as well towards the end. But most of the money is from VCs, at the moment.
Michaël: And what about first employees, I know you became public… well, you announced the investing in April 2022.
Connor: Yeah.
Michaël: Something like that. Did you already have employees there or… ⬆
Early Days of Conjecture
Connor: Conjecture came together in early March. So we wrapped up all the funding and stuff and January, February was a run up time and quit my job and stuff like that. And then March was when everyone, first people started to get together. It was still a complete mess. We were just a bunch of weirdos hanging out. We worked back and forth in different countries. Some people were in that country. Some people in that country. It was a complete mess.
Connor: So in April we first publicly announced ourselves. So at that time we were eight or nine people already, I think. So we had this funding team that we pulled together from EleutherAI. So then we announced ourselves in April. So we were already around a month at that point.
Michaël: So you said that you wanted to make a company because Nat talked to you and Gabriel talked to you two years before, was there a particular reason, something you wanted to create with the company, some philosophical point of view or something you think you had that other didn’t? ⬆
Short Timelines and Likely Doom
Connor: Conjecture differs from many other orgs in the field by various axis. So one of the things is that we take short timelines very seriously. Is that there’s a lot of people here and there that definitely entertain the possibility of short timelines or think it’s serious or something. But no real org that is fully committed to five year timelines, and act accordingly.
Connor: And we are an org that takes this completely seriously. Even if we just have 30% on it happening, that is enough in our opinion, to be completely action relevant. Just because there is a lot of things you need to do if this is true, compared to 15-year timelines, that no one’s doing, that it seems it’s worth trying.
Connor: So we have very short timelines. We think alignment is very hard. So the thing where we disagree with a lot of other orgs, is we expect alignment to be hard, the kind of problem that just doesn’t get solved by default. That doesn’t mean it’s not solvable. So where I disagree with Eliezer is that, I do think it is solve … he also thinks it’s solvable. He just doesn’t think it’s solvable in time, which I do mostly agree on.
Connor: So I think if we had a hundred years time, you would totally solve this. This is a problem that can be solved, but doing it in five years with almost no one working on it, and also we can’t do any tests with it because if we did a test, and it barrels up, that’s already too late, et cetera, et cetera. There’s a lot of things that make the problem hard.
Connor: So yeah, there’s all of that. We’re also very pessimistic about slowing down AGI, so I think coordination between orgs is actually definitely something we’re trying, and not impossible. Like getting OpenAI DeepMind and Anthropic all in a room together to talk, I think is a very feasible thing. ⬆
Cooperation in the AGI Space
Connor: One of the positive things that I’ve found is just, no matter where I go, the people working in the AGI space specifically are overwhelmingly very reasonable people. I may disagree with them, I think they might be really wrong about various things, but they’re not insane evil people, right?
Connor: They have different models of how reality works from me, and they’re like … you know, Sam Altman replies to my DMs on Twitter, right? You know-
Michaël: Weird flex, but okay.
Connor: But what I’m saying is, he’s not that unreasonable, right? I very strongly disagree with many of his opinions, but the fact that I can talk to him is not something we should have taken for a given. This is not the case in many other industries, and there’s many scenarios where this could go away, and we don’t have this thing that everyone in the space knows each other, or can call each other even. So I may not be able to convince Sam of my point of view. The fact I can talk to him at all is a really positive sign, and a sign that I would not have predicted two years ago.
Connor: I thought, “Oh, this guy would never talk to any of us,” or whatever, but, like … I don’t know, we might disagree, but he’s the guy I can talk to.
Michaël: Is it because you’re in the same tech space?
Connor: Yeah. It’s just this AGI space of OpenAI, DeepMind, Anthropic, Redwood, et cetera. It’s a space, even if people disagree with each other or think the other people are really wrong or something, every person I’ve met in this field is pretty okay. I haven’t met really anyone where I’m like, “Oh shit, this guy’s actually evil,” and those people do exist to be clear. And if the field continues to grow, those people will move into the field, and then we’re really fucked.
Connor: And this is for example, why I’m pessimistic about government coordination. So I think, for example, getting the USA and China to coordinate to slow down GPU deployment is hilariously impossible. I think that is absolutely ludicrously impossible, because these kinds of actually evil people do existing in government. Not all of them, of course not, but government selects for these kinds of people, and with these people, you can’t just do shit like this.
Connor: So I think it would be possible for Demis and Sam to sit down, have a dinner, and agree on something. I do not think that is possible between the USA and China. So that’s why I’m pretty pessimistic about a lot of government stuff. Not all government stuff. I think some stuff might be helpful, but I very skeptical.
Connor: But yeah, so I’m just saying this because I think coordination, communication within the community is very valuable and something that we at Conjecture think is important and worth doing. ⬆
Scaling Alignment Research to get Alignment Breakthroughs
Connor: So ultimately where all this philosophy leads us, is we think we are screwed by default. Things look pretty bad. We don’t have much time. The problem is very hard, and we don’t think that any current approach is obviously going to scale and work. It’s possible. If I’m wrong about one thing, this is one of the things I might be wrong about, but I don’t expect any of the current methods to work, and I have various reasons to believe this.
Connor: So what this means is, is that for a timeline to go well, we have to go through at least one crazy new breakthrough. There has to be some miracle. There has to be some new insight, and importantly miracles can and do happen. Before Newton discovered calculus and his laws of motions or something, what were the odds that both the motion of the stars, and the motion on earth, are both the same thing, and also human interpretable in the first place? It could have been that it is just some impossibly complicated thing that cannot be understood by humans, but then you see calculus and the laws of motion, and it’s like, “Huh, okay. I guess that’s it, okay,” and in retrospect, it’s super-obvious.
Connor: I think it’s really hard for modern people to put themselves into an epistemic state of just how it was to be a pre-scientific person, and just how confusing the world actually looked. And now even think things that we think of simple, how confusing they are before you actually see the solution.
Connor: So I think it is possible, not guaranteed or even likely, but it’s possible, that such discoveries could not be far down the tech tree, and that if we just come at things from the right direction, we try really hard, we try new things, that we would just stumble upon something where we’re just like, “Oh, this is okay, this works. This is a frame that makes sense. This deconfuses the problem. We’re not so horribly confused about everything all the time.” ⬆
To Roll High Roll Many Dices
Connor: So to do that, well, if you need to roll high, roll many dice. At Conjecture, the ultimate goal is to make a lot of alignment research happen, to scale alignment research, to scale horizontally, to tile research teams efficiently, to take in capital and convert that into efficient teams with good engineers, good op support, access to computers, et cetera, et cetera, trying different things from different direction, more decorrelated bets.
Connor: One of the problems I have with the current alignment community is that a lot of it is very correlated. It’s like Anthropic, Open Phil, Redwood, Paul all are doing very similar things … and don’t get me wrong. Those are good things, they should be tried. There’s a lot of good ideas there that should be tried, but I think we should try more things. I think we should try many things. I don’t expect most of them to work. I think we should try more things.
Connor: So, of course, we’re not there yet. We’ve existed for four or five months now, and things are moving super-fast at Conjecture. Like, holy shit, I have whiplash from how fast things are moving here. It feels like I’ve lived a whole lifetime in the last three months.
Michaël: That’s generally what people say about being a CEO, is that the time is much more intense.
Connor: Yeah, it’s wild. It’s wild how fast things are moving.
Michaël: So yeah, about the thing where you try to find some theoretical breakthrough similar to what Newton has found when thinking about physics and the motion of the moon and stars, I think that’s similar to what Yudowsky says about sigmoid and ReLU, where we might be missing the ReLU of alignment.
Connor: I think that’s completely possible. I’m not saying I know what the ReLU is, or even where it will come from. What I’m saying is we should try lots of different things. Because we don’t know where it will come from, we should try many things. As I said earlier, there should be more people working on this problem. That’s my radical, crazy belief. More people should be trying things, and we should try more different things. That’s my radical hypothesis of Conjecture, is we should try more different things.
Connor: So at the moment we are still not too large, and we’re at 15 people now, and we are trying certain bets, which is mostly colored from the previous ideas from EleutherAI and such. So we have certain biases in what we’re trying, but what I would long long-term is an organization that can efficiently scale and grow a number of researchers, a number of projects, and a number of different directions, and hopefully decorrelate. They’re not all working on just one singular idea or in one singular paradigm, but we’re trying many different things, and coming at things in different directions.
Connor: We are already doing a lot of quite different things. Sometimes people are like, “What is the one thing Conjecture is doing?” And I’m like, “There’s five that have nothing to do with each other, and we’ve only existed for four months.” We’re a for-profit company, technically, that has an epistemologist on staff. ⬆
The Epistemologist at Conjecture
Michaël: What’s the goal of the epistemologist?
Connor: That’s a great question. So recently I was talking to someone, and they asked a very good question. This is a very good question. And they asked, “How do you know whether you’re making progress or not?” I think that’s an excellent question, and it’s usually a really hard question to answer. This is a hard question to answer, but we have an epistemologist on staff, whose whole job is just to understand the epistemology of alignment and to make sure that we steer on track and are trying to actually solve the real problem, and understand why it’s hard. They were like, “Huh, that’s a pretty good answer.”
Connor: So our epistemologist is Adam Shimi, who’s great. His goal is to understand “why is alignment hard?”, “how can we know we’re making progress on it?”, “how can we avoid being distracted?”, “how have other problems of this kind been solved in the past?”, “how did other scientific revolutions happen?”. Actually studying the history of science and the philosophy of science and epistemology, understanding how things work, and am I a hundred percent sure this will lead to something? No, but should we try? Why don’t more organizations have an epistemologist? Sure seems something worth trying, and so far I’ve been super-happy with the really insightful stuff Adam has been pulling up about how progress actually happens, how other great breakthroughs actually happen, because there is so much mythologization of science, that just really hides how the actual process works in the real world that’s quite difficult to disentangle.
Connor: So a lot of people, their models of how science happens or has happened in the past is often very wrong, and if you follow these cartoonified versions of science, you’ll often get very confused, and not actually get problems solved. So I’m super-happy actually to have someone on that who is … that’s his full-time job, is to do the meta question like, how do we do science? Are we doing science well? Are we confused? And he’s also very helpful … if there is a book I need reading, but I don’t have the time, I’ll point it and be like, “Adam, can you read that book and summarize it for me?” And he’ll be like, “Yeah, great.”
Michaël: You have a alignment theory assistant that can do all the reading for you, and-
Connor: In a way, yeah, it’s great. He reads … God damned, he reads so much. It’s actually insane. I don’t know how he reads that many books. It’s actually wild. His desk, every time I come into the office, I swear there’s three new books on his desk, and thick books too, big books. It’s actually wild, but-
Michaël: He is also in charge of the incubator for alignment that you’re doing? ⬆
What Economics Can Teach Us About Alignment
Connor: That is correct. So I could talk a little bit about one of my current views of what I think a solution to alignment looks like. So it’s something I’ve been thinking quite a lot about recently. It’s like, how would I know I solved alignment, or how do I expect the shape of a solution to be?
Connor: And I don’t have a good answer to this, but have a pretty bad answer. I have a mediocre answer to this question, and so my mediocre answer to this question is something along these lines. So Gabe has a really fun, a really fun hot take about economics. So his fun hot take is that economics is not a science, it’s a technology, and it’s engineering, and he says, economists themselves are confused about what economics is. So the argument goes the following. A lot of people criticize economists because they make wrong assumptions. They say, “Oh, the markets are efficient,” but markets are not never really efficient or very rarely, really efficient. They make assumptions about reveal preferences or irrational agents or whatever, and they’re like, “Well look, economics is stupid.”
Connor: But no, I think they got it the wrong way around. What economics is actually doing is they take this extremely high dimensional optimization problem, which is the real economy, the actual economy. To optimize the actual economy is just computationally impossible. You would have to simulate every single agent, every single thing, every interaction, just impossible. So instead what they do is, they identify a small number of constraints that if these are enforced, successfully shrink the dimension of optimization down to become feasible to optimize within.
Connor: So when an economic theory says, “Assuming markets are efficient, then we can conclude X, Y, Z,” or something, what it’s saying is, “If you somehow enforce this property on reality, maybe by force, then you get the benefit that you can now reason about all these nice properties.
Connor: Agriculture is similar. The correct way to maximize your yield of your field would be to simulate every single bug, every single molecule of nitrogen in the soil, every single plant, and then plan some kind of complicated fractal of weird plants interacting in bizarre ways, but this is obviously computationally impossible. So if you want to reason about how much food will my field produce, monoculture is a really good constraint. By constraining it by force to only be growing, say, one plant, you simplify the optimization problem sufficiently that you can reason about it. ⬆
What the First Solutions to Alignment Might Look Like
Connor: I expect solutions to alignment, or at least the first attempts we have at it, to look kind of similar like this. It’ll find some properties. It may be myopia or something, that if enforced, if constrained, we will have proofs or reasons to believe that neural networks will never do X, Y, and Z. So maybe we’ll say, “If networks are myopic and have this property and never see this in the training data, then because of all this reasoning, they will never be deceptive.” Something like that. Not literally that, but something of that form.
Connor: And so I think generalized alignment problem, alignment arbitrary system, is definitely impossible, if only because of halting constraints. So if ever aliens come down from space and hand us a USB drive with AGI.exe, do not run it. Burn immediately. Do not run it. No matter how much you analyze the code, no matter how many interpretabilities … do not run it, burn it immediately. Do not run.
Michaël: AGI_safe.xe.
Connor: Oh, that’s fine. Yeah, yeah. Go right ahead, yeah. No.
Connor: So basically, I think if you were given arbitrarily maliciously selected program, you’re fucked. If it was selected by a sufficiently strong adversary, you’re fucked. Just don’t run it.
Connor: But the reason I think alignment is feasible and can be done by actual humans in the real world, is because we get to pick the agent, hopefully, hopefully, and so I expect there will be constraints on the training. It would be like, “Okay, during training, we have to do X, Y, and Z, and W is never allowed to happen.” And then if these conditions hold and whatever, then we get this nice safety property, this property, or we have a probabilistic proof that X will never occur with this probability, or whatever.
Connor: And then … this is not perfect, obviously … this is not a full solution, but this is what I expect the first partial solutions to look like. ⬆
Interpretability Work at Conjecture
Connor: And so this is why two of the main things that Conjecture works on, is, a, interpretability work. The reason we work on interpretability, and we’ve just published our first technical post about interpretability, which is on how to defeat mind readers, just today.
Michaël: Wow.
Connor: Yes. It’s a taxonomy and write up of all the ways we think neural networks could defeat interpretability tools. One thing in Conjecture that we try to take very seriously is safety mindset. So I could talk about that as well, but basically we really try to be paranoid. We don’t want to make any assumptions that we don’t have to make about these kinds of things. I could talk about that later. But yeah, we also have some other cool work on policy authenticity coming up.
Connor: So basically the reason we’re interested in interpretability is because we think it will be necessary, not because it’s a solution to alignment. I don’t think interpretability is a solution to alignment. I think it just gives us the tools to implement solutions of alignment. If we don’t know what’s going on inside the network, we can’t really do proofs or reason about the internal algorithms, or check for certain properties or something, so we need to have a really strong understanding of these internals in network.
Connor: There is this meme, which is luckily not as popular as it used to be, but there used to be a very strong meme that neural networks are these un-interpretable black boxes.
Michaël: Right.
Connor: That is just actually wrong. That is just legitimately completely wrong, and I know this for a fact. There is so much structure inside of neural networks. Sure, some of it is really complicated and not obviously easy to understand for a human, but there is so much structure there, and there is so many things we can learn from actually really studying these internal part … again, staring at the object really hard actually works.
Connor: So using these interpretability tools, we get quite far, but there is a big problem missing here. I think if we had perfect interpretability tools, whatever that means, that can understand anything like an ELK head, which is like the stuff that Paul Christiano has done or something, that wouldn’t be enough because we don’t yet have a blueprint, a proposal, for how we would then put together an actually aligned agent, that’s actually embedded, that doesn’t wire ahead, that actually does implement CEV, or whatever you want it to do, right? ⬆
Conceptual Work at Conjecture and The Incubator
Connor: So this is where the conceptual alignment research comes in, is that we think conceptual work is also extremely important, that even if we had all the right tools and all the compute and everything, we still wouldn’t know how to build an AGI that is aligned. So therefore, it’s really important that we also work in conceptual work, and that brings us to one of the incubator, which is one of our attempts to get new ideas in conceptual alignment research. So the incubator is called Refine, and is run by Adam Shimi, and it is partially funded by LTFF, partially funded by us, and basically it brings together five promising young conceptual alignment researchers, who have been selected for having unusual ideas, often selected to have the minimum exposure to the alignment community possible, while still knowing about the problem, and they’re going to start next month.
Connor: So they’re going to be in a very nice place in France for a while, where they’re all going to hang out-
Michaël: In France?
Connor: In France, yes, so we rented them a big, huge, like a vacation house, for them to all just chill there for a month, and then they’re going to come back to London to hang out with the rest of Conjecture.
Connor: So Adam’s going to teach them a lot about the epistemology of alignment and the basics of how to avoid obvious mistakes and problems that can happen, and the goal is for them to incubate new research directions. So we’ve really selected them for having weird new ideas that are different from other people in the community, and there is no obligation for them to work on any Conjecture stuff or stuff we do. They’ll hang around the office, they’ll try to figure out their own stuff. They get some mentorship from Adam, and we will have fun having them around of course, and we’ll talk about ideas and stuff, and the ultimate goal is just to get more ideas, incubate more ideas, see that some new ideas or research directions come out of that.
Michaël: Is the basic idea to have the same thing as you mentioned for economics, where you have a simpler model, and then you can reason about the thing and solve it more efficiently for alignment, so those five guys might come up with a simpler model for alignment, where we could have a easier solution.
Connor: Maybe, we have put no constraints on what they come up with. So these guys have been selected … guys and girls … who have been selected by just having interesting ideas. Would those ideas go anywhere? I don’t know. Every single of these people … I cannot stress how excited I am for each of these people. I read the blogs of some of these people, and they’re just completely insane in the best possible way. I’m like, “Holy shit, this is probably never going to work, but fuck yes.” That’s just my … every time I read these blogs, it’s just like, “This is completely insane, fuck yeah.” Oh, let’s go, let’s go. I want to see where this goes. I just want to see this person keep thinking and just see where things go. So I expect most of this to go absolutely nowhere and just get stuck, or just get confused, or just drift off or whatever, but that’s okay. It’s okay. I think this is the only way where we might stumble on some new direction where like, “Hey, we haven’t thought about AGI from this perspective,” and from this perspective, you suddenly see all these new questions, all these new angles, and stuff like that.
Connor: So my hope is that maybe out of that, one or two people will develop a whole new research agenda that’s completely different from everyone else, and maybe we’ll then hire them to stay working with us, or maybe they’ll get funding from some other organization to continue to work or whatever. So our goal is to make more ideas possible, and help people get into it, and also what we want to do is take … and we see this also as a test case for us to practice our long-term goals of getting good at scaling up alignment. How can we efficiently teach people? How can we get new people to do conceptual work? How can we industrialize the process? How can we industrialize alignment? How can we make these more efficient? How can we get more people working on it? New ideas, not everyone doing the same thing, not everyone following one direction. What are the bottlenecks? Where do things break? Where-
Michaël: So yeah, it’s more a process in a startup environment, where you just try to see how do you fund alignment research better in an uncorrelated way with OpenPhil funding or LTFF funding, because we are both in the Bay, and a bunch of people are coming here to learn about alignment, and they learn from the same groups, same people, read the same posts, so I think it’s a pretty good idea to have uncorrelated bets.
Connor: Yeah, we just want to try different things. That’s the reoccurring theme at Conjecture. We think all the current things are great, and I’m happy that they’re being done, and more people working on the current thing is also good. Every person joining Paul working on his agenda, I think is a good thing, but I think we can also do more. I think there is even more.
Connor: It’s also quite nice that … so of the five people we selected, zero are American, so we’ve got four Europeans and one person from Southeast Asia, so we’re getting also a lot of people from just different parts of the world.
Michaël: And so you mentioned that they could be offered a job at Conjecture. Do you also have alignment research going on in Conjecture, or is it mostly in the incubator?
Connor: No, there’s definitely a lot of research happening in Conjecture, absolutely. So we have several directions of both the interpretability work, and we also have some conceptual work, which I think we will also be publishing quite soon, which we’ve done with simulator theory, which is quite interesting, which is a new frame for thinking about GPT-type models, or generally subtle supervised models. It’s almost a work of philosophy, but it’s a different frame. It’s a different scientific frame on how to think about these things, which we hopefully will be talking about, or hopefully publishing soon.
Michaël: Right, happy to read it on LessWrong or arXiv or whatever when it comes out.
Michaël: So one thing about publishing or releasing work, is you post stuff on LessWrong, and you also don’t plan on releasing the models, or at least not publish everything by default, and it is a policy close to MIRI, I believe.
Connor: Yeah. ⬆
Why Non Disclosure By Default
Michaël: So we are non-disclosure by default, and we take info hazards and general infosec and such very seriously. So the reasoning here is not that we won’t ever publish anything. I expect that we will publish a lot of the work that we do, especially the interpretability work, I expect us to publish quite a lot of it, maybe mostly all of it, but the way we think about info hazards or general security and this kind of stuff, is that we think it’s quite likely that there are relatively simple ideas out there that may come up during the doing of prosaic alignment research that cannot really increase capabilities, that we are messing around with a neural network to try to make it more aligned, or to make it more interpretable or something, and suddenly, it goes boom, and then suddenly it’s five times more efficient or something.
Michaël: I think things this can and will happen, and for this reason, it’s very important for us to … I think of info hazard policy, kind of like wearing a seatbelt. It’s probably where we’ll release most of our stuff, but once you release something into the wild, it’s out there. So by default, before we know whether something is safe or not, it’s better just to keep our seat belt on and just keep it internal. So that’s the kind of thinking here. It’s a caution by default. I expect us to work on some stuff that probably shouldn’t be published. I think a lot of prosaic alignment work is necessarily capabilities enhancing, making a model more aligned, a model that is better at doing what you wanted to do, almost always makes the model stronger.
Michaël: Are you also planning to work on keeping up with State of The Art, scaling-up models, and being an AGI company, whatever that is, just thinking about AGI in some sense?
Connor: So, thinking about AGI in the broadest sense, well, we’re trying to solve alignment. So of course we’re thinking about AGI. Our goal is definitely not to push the state of the art, or to get anywhere near the limit in that regard, or race or anything that. Also because we obviously can’t, since a lot of that is computation bound, and we don’t have exactly the kind of funding that groups like Anthropic or Deepmind or OpenAI have, but-
Michaël: Do you plan on having this kind of compute soon or-
Connor: We don’t, no. So we will have a decent amount of compute, because I think it’s very important. Being able to run experiments on GPt-3 size model, I think is just important. That is important to do, and you know, I think there’s many reasons why you might want to train GPT-3 size models. For example, we have some really neat ideas about how to modify the transformer architecture to, we think, become more interpretable, to make our internal computations, clean more cleanly separated, and seems like that should be something worth trying, and I think if that scales and that works, that might be a really promising thing to train large models on and to experiment with, but all this is very much instrumental. We have no interest in building large models for large models’ sake. That’s just expensive.
Connor: We have EleutherAI models and the OPT models, and now Bloom and stuff, that we can work on. Will we train internal large models? Yeah, probably, because we have some various ideas of how to modify architectures, and we wanted to experiment on large models and stuff like this, but yeah, I don’t expect us to catch up to, say, OpenAI. I think we can catch up to GPT-3, but God knows what GPT-4 is going to be like, and probably going to be a while until we could catch up to that, so it’s super- instrumental.
Michaël: In terms of sharing research or open source, will you maybe open source alignment work and maybe not capabilities work? Is it-
Connor: Oh yeah. Capabilities work … if we ever discover some crazy capabilities breakthrough, you will never hear about it. You will just never hear about it.
Michaël: Right. Just the question is more like, do you plan on open sourcing alignment tools or things like that? ⬆
Keeping Research Secret with Zero Social Capital Cost
Connor: Probably, yes. It’s all going to be in a case by case basis, and we’re also going to take an external review on stuff this, so we hope to have a list of trusted alignment researchers that whenever we’re like, “Oh, we’re not sure about this,” we share with them, or we have a secret project.
Connor: In a sense, my whole goal here is just, I want to have an organization where it costs you zero social capital to be concerned and keep something secret. So for example, with the Chinchilla paper, from what I’ve heard is instead of DeepMind, there was quite a lot of pushback against keeping it secret. So apparently the safety teams want to not publish it, and they got a lot of pushback from the capabilities people, because they wanted to publish it.
Connor: And that’s just a dynamic I don’t want to exist at Conjecture. I want to be the case that the safety research can say, “Hey, this is kind of scary. Maybe we shouldn’t publish it,” but that is completely fine. They don’t have to worry about their jobs. They still get promotions, and it is normal and okay to be concerned about these things. That doesn’t mean we don’t publish things. If everyone’s like, “Yep, this is good. This is a great alignment tool. We should share this with everybody,” then we’ll release. Yeah, of course.
Connor: But I just want it to be … it seems like an obvious bridge to improvement for there even to be the option to keep things totally secret, and I think we should do that by default, and also siloed. So different teams may work on different things, and they don’t know what each other work on. I think this is just a good default to have, but if we create a great suite of interpretability tools that we think are really helpful for alignment research, yeah, probably we’ll release those.
Michaël: Yeah, I think it’s a good thing that you not have social consequences and think about losing your job if you want to make stuff private. I think Chinchilla was kind of scary as a safety researcher, and maybe delayed by a year by those people, so I’m kind of happy that they did the job, but maybe it was too hard for them. So-
Connor: Yeah, it feels like we can do better. ⬆
Remote Work Policy and Culture
Michaël: We can do better. So let’s go back. Let’s focus now on this idea of teams, how they interact with each other, and what’s that culture of work. If you want to do a shout out for people to join your company, and I guess most of people around now in 2022, want to work remotely, you have some visiting office in Oakland, something in London, what’s the ratio of remote vs. In-person? Is there a policy about it? Do you want to talk about this?
Connor: Yeah, sure. Happy to talk about that. So we are based in London, and that is for various reasons. A lot of it is to decorrelate from the Bay. You know, all alignment stuff is in the Bay.
Michaël: Decorrelate all the time.
Connor: Yeah, we think there should be a place, for example, where European people can go. A lot of people can’t get a US visa. A lot of people maybe don’t want to move out of Europe, and so London is a happy middle ground, where there’s a pretty good visa process there, it’s pretty easy to get technical workers into the UK, much easier than the US. It’s much closer for many European people, and maybe people who don’t want to move away from their family too far.
Connor: So we think that there should be a EU place to do alignment, and that can be us, so I think there’s a lot of nice things there. Also by London, I think it’s a really great place to live. I don’t like the Bay particularly.
Connor: So for the remote policy, so generally we are an in-person company. So we think that in-person work is really, really valuable, and really increases productivity, and so far everyone at the company agrees, “Oh yeah, I’m so glad to be back in an office after two years.” But if you want to spend a month or two abroad with your family or something, that’s no problem. That’s no problem at all. For more extensive remote on a case by case basis, I’m open to negotiating. So basically, there are some people I have known who are incredible, super-geniuses. They can lay on some beach in Hawaii, and still be the most productive person in the company. If you’re one of those people, fine, okay, you can do remote, but 99% of people that think they are that person are not that person. Managing things remote is a very non-trivial cost, and you’d have to be really good for it to be worth paying, but those people do exist. There are people that … and as I said, take a month off to visit your family or go on a hiking trip or something. Yeah, no problem. That’s super-fine.
Connor: We’re also super-chill about when you come into the office or when you do your … generally also, want to work from home a few days a week? Sure, no worries. As long as your work gets done, we don’t really care when you do it or how you do it. Some people stay until 4:00 AM and they come in 4:00 PM, leave 4:00 AM. Fine, as long as their work gets done, and they go to their meetings, which we have gracefully little of. Every single person in Conjecture hates meetings, so we think-
Connor: Yeah so we avoid them at all costs, but, sometimes you have to have them, sometimes you have to sync up and talk to people and such.
Michaël: Right.
Connor: Currently the culture at EleutherAI, sorry at Conjecture, is really really, it’s really nice. I really like working at Conjecture. It feels like an industrialized EleutherAI, in many sense.
Michaël: EleutherAI but with more money?
Connor: Yeah, EleutherAI with more money and more like actually getting shit done, and actually working full time on things.
Michaël: So essentially you’re saying process-based management, where if you get the shit done, you’re good. And I would say Elon Musk remote policy, where like if you’re extremely good, then you can just chill in Hawaï. He gave this memo in Tesla where he was like, “Oh, you should go back to the office except if you’re like very good.”
Connor: Yeah, if you’re sufficiently good and these people do exist, I don’t give a shit. If you want to sit on the beach somewhere and if you get just more done than anyone else, I don’t give a shit. I’ll pay you the full salary, like who cares? But these people are very rare, but if you are one of those people you consider applying. ⬆
A Focus on Large Language Models
Michaël: Right. I think another thing people might want to know is like how much compute they might have for their experiments. And so you mentioned a bit about the compute part, but I’m curious because you didn’t talk much about like the AI part. So kind of the projects that are going on. If you’re mostly like working on computer vision, RL or mostly like language models, if people have, can like train models as big as they want, or they’re bottlenecked by this. Yeah. What would you say to those people?
Connor: So the way we’re currently very biased towards large language models, this is just kind of a founder effect just because like most of the research that we’re currently doing, kind of like inherits from stuff we were doing at EleutherAI and stuff. So we think there’s a lot of reasons why language models are the best object or one of the best objects to study. If you’re interested in AGI, we think that language models have a lot of things in common with AGI that are really important. This doesn’t mean we’re not opposed to doing multimodal or all kind of stuff.
Connor: We think RL is pretty scary for various reasons. And we kind of, this is like something we’re going to be publishing about. We kind of think trying to develop alternatives to RL is like a pretty good way forward actually. But that aside like for example, Sid, who was our CTO. He is he’s the lead author of magma, which is like a paper that like combined language models with like images and it worked really, really well. So like we could imagine such work, none, no such works currently happening that I’m aware of, but we’re like, we’re very practical, right? If there’s an experiment, if there’s a clear research direction, we’re like we need to do some RL or we need to do images. We’re totally open to that. Just most of our research currently doesn’t require that.
Michaël: Right. So now you’re focusing mostly on large language models. I’m pretty curious about the products you plan on releasing, or you’ve done work so far. Because I think that’s the first question people ask me when I say I’m going to do a podcast Conjecture is like, “Oh yeah, but how did they make money? Like they’re a for profit company.” ⬆
Why For Profit
Connor: Happy to talk about that. So the choice to be for profit is very much utilitarian. So it’s actually quite funny that in on FTX future funds like FAQ, they actually say they suggest to many non-profits to actually try to be for profits if they can. Because there has a lot of good benefits such as being better for hiring, creating positive feedback loops and potentially making them much more long term sustainable. So the main reason I’m interested is long term sustainability and the positive feedback loops and also the hiring’s nice. So I think there’s like a lot of positive things about for-profit companies. There’s a lot of negative things, but like it’s also a lot of positive things and a lot of negative things with non-profits too, that I think get slipped under the rug in EA. Like in EA it feels like the default is a non-profit and you have to like justify going out of side of the Overton window.
Connor: But I think there’s a lot of reasons why for not for-profits have like a lot of nice properties. So like one thing to be clear about the for-profit nature: the founders like me and the others have full control of the company, the VCs do not have any control shareholder or board or otherwise, and that will not change. The one thing we will not compromise on is control of the company. We’re happy to have advisors. We’re happy to compromise on like compensation or whatever. But the one thing we will not compromise on is the control of the company. That’s not up for debate.
Michaël: Even if the company becomes public?
Connor: Well, it won’t be public. There’re no plans for that. I would never make it public if that meant giving up control of the company. I don’t know if that was possible to stay in control indefinitely of the public company, probably not. So that’s just not really on the table. So one of the benefits of a for profit company is that you can make money and the EA sphere has a lot of great funders who are funding a lot of good work and such, but if you really want to scale alignment talent and compute is really expensive. And relying on the whims of billionaires is not a reliable long term plan. I think it’s great when like SBF invests a lot of money in Anthropic.
Connor: I think that’s great, that’s wonderful. And I do hope that potentially these kind fund are interested in funding us and giving us their money. But I think there’s a pretty clear way that if you want to have a long-term organization that really wants to scale, that wants to deploy not just millions, but billions of dollars potentially over like several years. And you want to exist for years at a time and not just rely on what the crypto market’s looking like at the time. Making products and making money and also raising VC is a very efficient way or maybe the best way to kind of have this kind of recurring stream. ⬆
Products using GPT
Michaël: How do you plan on, on making products and that might generate money in the future?
Connor: So the plan at the moment, this might change in the future. So like currently there is no product, there’s no team working on product directly, but the plan is there will be a product team. This will be separate from the alignment team. Maybe people will move back and forth if they’re interested. I’ve had people who like want to work on alignment, but they also really like working on product. And if you want to do that, I mean, that’s a fine thing. Sometimes the way I pitch it to EA’s, is working on the Conjecture product team is like leveraged earning to give without the middleman. So instead of going to work from hedge fund and making a bunch of money, you can work for the product team. There’s a bunch of EA’s that already know product managers or web developers or whatever, right.
Connor: Business developers and such, which is all fine skill sets they’re smart people and they want to help. So instead of going to work for something company and donating your money to alignment research or something, instead you can work directly on a product. And then for every dollar of value you generate, we can raise 10-100x VC on top of that. And then we have recurring revenue, which is the freest money you will ever get. And that’s a really easy way to raise large amounts of money and to actually, and to exist for a long time or time. So the way I would ideally want things to happen is to be like, there’d be a separate product team that uses a lot of the same infrastructure that is rebuild anyways for the kind of alignment research that needs happening to build various products on.
Connor: And the way I think about products at the moment is, I basically think that there are the current state-of-the-art models that have like opened this like exponentially large field of possible new products that has like barely been tapped. GPT-3 opens so many potential useful products that just all will make profitable companies and just someone has to pick them. And so I think without pushing the state of the art at all, we can already make like a bunch of products that will be profitable. And most of them are probably going to be relatively boring, like relatively like boring SaaS products that are like…
Michaël: An API?
Connor: No, not an API, API’s a bad product. APIs get always driven down to, they get compete into the ground. No, like you want to do a SaaS product, like something that helps you with some business task. Something that like helps you do, make a process more efficient inside of a company or something like that.
Connor: There’s like tons of these things, which are just like not super exciting, but they’re like useful.
Michaël: Something closer to like what Adept.ai tries to do.
Connor: Yeah. And except not as insane, dangerous, but like much simpler than that. Something that can like. ⬆
Building SaaS Products
Connor: I don’t want to give too many examples yet because we’re currently pitching some stuff, but just like useful tools. SaaS tools that can be used for various business processes. Kind of like look at like other companies that are using GPT-3 currently for their products, stuff like that. Things that are really useful that really save companies money. That make process like. There’s a whole huge class of tasks that were previously inaccessible to automation tools that now become accessible through like GPT type models, that open up all these like really useful tools that can be used in just normal companies to like make things more efficient or whatever. And make a profitable company out of it. Have some millions of revenue and whatever without having to do any crazy capabilities, advancements without having to push some kind of crazy new thing out there or anything like that.
Connor: We don’t have to have the biggest model. We don’t have to have the craziest new capabilities breakthrough for these things to work. We just need like a good useful tool. And I think there’s a bunch of these and I think we can get great talent from the EA world for building these kinds of things. And then by investing however much of our of my time or investment or whatever, making these products, we will get a much higher return. So it’s a pretty utilitarian thing. It’s like I think that we can make a product cost us, I don’t know, 5 million to develop. And then we get like five million revenue out of that or 50 million of revenue out of that or whatever. And that’s a very obviously good thing to do.
Connor: It’s good to have contact with reality. It’s good to make your own money to also like for example, we’re having a huge market downturn now. And when I wish we had some recurring revenue right now that would make me feel a lot safer that we don’t run into trouble. Cause the crypto market’s super down now. So now all like the EA money is like much lower.
Michaël: Right.
Connor: So like would, if I had a reoccurring revenue right now of a few million a year, I would feel a lot better right now. I would feel like a lot less scared that something might go down. So that’s kind of the thinking there. ⬆
Generating Revenue In The Capitalist World
Michaël: Right. But the thing you said about like being dependent on some, the funding of some rich billionaire, if you’re a nonprofit, I think you kind of have the same, or maybe worse, with a for profit where you’re like dependent on making revenue yourself or making profit for the investors. And I guess there’s like, there’s one point that could be made where for large models that you want to train, you might need billions in money, like maybe it’s impossible to like generate enough money to train GPT-4 by doing SaaS products, maybe because you know…
Connor: OpenAI did it.
Michaël: Well, weren’t them like funded by Sam Altman and Elon Musk at the beginning? And then now they’re just like cooperating with?
Connor: Most of the money came from Microsoft. Yes. Which is for profit. So I think you could raise much more money in the capitalist world than you can in the EA world. To be clear if the EA world just wants to fund us at a large level for like a consistent period of time. Absolutely fantastic. Great. Then maybe we don’t even have to do a product. If Sam Bankman-Fried drops a billion on my lap, I’ll be like, okay, screw product. We’re doing research, but I just don’t expect that to happen, which is understandable right? So I think it will cost a very, a very reasonable amount of effort. I have people on my team who are just like,” Hey, I love doing product”. And it cost me low energy. I’m like, okay, if you love doing product, you’re good at it.
Connor: It can generate us a lot of revenue. It doesn’t distract the researchers. Why not, right? I think this is a really positive feedback loop here. And I think there’s a lot that also like psychological benefits actually to this kind of stuff. A lot of people just feel good about like making real things and putting them into the world and making money and stuff like that. I think it shouldn’t be discounted that there’s like a lot of positive upsides to these kind of things going wrong. There’s also problems, there are incentives and there are things or whatever. And you have to be very aware of those and we are very, very aware of those and very wary of them. But sometimes you have to just try things, right? Yeah.
Michaël: There’s a bunch of incentive in like doing stuff in the real world that made your beliefs pay rent, as Yudkowsky would say. ⬆
The Wild Hiring at Conjecture
Michaël: I browsed your website and I wanted to get a new job. I didn’t find any podcaster job. So it was pretty sad, but also I didn’t find any Machine Learning job. And I was wondering like, did you like just pause the hiring for a moment because you had like too many people coming in or you’re planning to like scale the team to like double the size in a year? Like what are the current plans for funding or grow the team in the future?
Connor: I mean, basically exactly that, is that it was actually wild. So when we… Our advertising quote unquote, it’s just like one Lesswrong post that was like, “Oh, we’re hiring”. Right? And we got like a ton of great application. Like the signal to noise was actually wild. Like one in three applications were just really good, which like never happens. So, like, incredible.
Connor: So we got to hire just like some really phenomenal people for like our first hiring round. And so at this point we’re already basically at a really enviable position. I mean, it’s like, it’s annoying, but it’s a good problem to have, where we’re basically already funding constrained. So we’re at the point where I have people I want to hire projects for them to do and the management capacity to handle them. And I just don’t have the funding at the moment to hire them. So like we have plenty of runways where we’re like not going away or anything like that, but basically I was like, Ooh, how long will it take for me to find enough people to hire? It’s like, just like they just ran through my door. And it was like, wow, these are excellent people to hire. So it’s currently paused just because basically we are funding constrained.
Michaël: Is the problem related to the kind of crisis and you mentioned the crypto market falling?
Connor: Yeah. So basically we were planning to raise more money probably later this year, but because the market is crashing now, one of the reasons I’m in the Bay right now is I’m kind of looking to see if we can raise more money. Hopefully from EA sources or potentially VCs in order to scale our organization even further. Because the long term goal is obviously to solve alignment, right? And talent and compute is expensive. You want to hire great researchers and you want to get engineers and you want to do great stuff. It’s expensive. So we really think that because we have short timelines, there’s a premium on acting quickly on like actually scaling quickly and actually building large teams quickly and such. So we would really like to scale further and we really hope that, for example, we will get more funding from various EA sources. Maybe Sam Bankman-Fried can drop a quarter of Anthrophic on us or something. ⬆
Why SBF Should Invest in Conjecture
Michaël: Yeah. So if you were like to talk directly to Sam Bankman-Fried. I’m Sam Bankman-Fried right now in front of you. Why would I donate money to you instead of, or sorry, invest money in you instead of Anthropic or let’s say Redwood, like what’s the difference between?
Connor: I don’t think you should do it instead of these other orgs…
Michaël: Right, why should I put Conjecture in my portfolio?
Connor: Conjecture is an organization that is directly tackling the alignment problem and we’re a de-correlated bed from the other ones. I’m glad I’m super glad of Redwood and Anthropic are doing the things they to do, but they’re kind of doing a very similar direction of alignment research. We’re doing something very different and we’re doing it at a different location.
Connor: We have access to a whole new talent pool of like European talent and talent that can come to the US. We get a lot of new people into the field. We have like also the EleutherAI people coming in, we have different research directions and de-correlated bets to get things in. And we can scale. We have a lot of operational capacity, a lot of experience and also entrepreneurial vigor. So to speak, to try to really build bigger things, to scale things up to tackle more ambitious projects and to get more things on. And so far things have been growing incredibly well.
Connor: We’ve already posted some of our early results and we’re going to post more soon and we have an incredibly exciting team that has incredible good experience and like unique experience in many sense kind of skills to work on these kinds of problems. So if you’re, if you want to diversify your portfolio of alignment bets, if you want to some more de-correlated bets, some more shots at the problem. I think we’re a pretty obvious choice. Pretty good choice. ⬆
Twitter Questions
Michaël: I just want to end this, because I think we kind of talked a lot about the Conjecture, with some of the questions that are a bit more non-serious and meme, just to conclude the whole thing, from Twitter. Which are the very important question of “why is the law of excluded middle the best law?”. Asked by… I don’t know, someone on Twitter.
Connor: Okay. This needs a bit of context. Excellent question. Excellent question. So the context of this is, so the law of excluded middle is one of the axioms of classical logic, which basically says every statement and logic is either true or false. And this is one of my favorite topics to shit post about on like I EleutherAI’s #off-topic when I’m really late, late at night, because my whole… My galaxy brain schizo take is that like all of mathematics is basically wrong. And is very confused and like defines truth wrong. And like all kinds of proofs are like wrong and invalid and et cetera, et cetera. Just like big brain stuff. And the reasoning for that, like we don’t have time to get into all the reasoning here. So I’m just going to throw out a ball bunch of super technical words and just like not explain them, if you’re like a mathematician, you might understand these. And if you don’t then have fun Googling. ⬆
The Law of Excluded Middle
Connor: Basically the problem with the law of excluded middle is that it’s an implicit halting oracle. So the classical equality of like the resolution of statements in classical logic is equivalent to executing programs. And the law of excluded middle assigns a truth value to every program. And I think that is a wrong value because there are actually three truth values; true, false and un-computable or unprovable. And because you don’t do this because the law of excluded middle does not assign un-computable to any statement. It always says true or false. You can now assign a true or basically a halting state to non halting programs. So this is a halting oracle and this breaks everything. This breaks everything. So mathematicians that look at this are like, what’s the problem?
Connor: I love the law of excluded middle, unless you prove all these great things. And I’m like, no, its evil math. It’s the bad math. It’s cursed. I mean, obviously I’m to be clear, none of this matters that much, but it also matters. Like basically there’s this idea that truth is like an objective property. That’s like holds normal things. That’s not true. Truth, huh? That’s not true. No truth is a property that is dependent on your choice of logic. There is not one logic. There are actually many logics and logics have assigned truth values to different statement. Different truth values to different statements. So in the classical logic, you assign true or false or whatever to many statements that are assigned un-computable in other logics. And I think this is bad because basically what the fuck does it mean that this non halting program halts? Like this lets you prove like all kinds of crazy shit, like the Banach–Tarski paradox and stuff like this, which like intuitively don’t make sense.
Connor: I think the Banach–Tarski paradox is reliant on the law. It actually might be wrong. Please don’t fact check me on that mathematicians.
Michaël: Maybe we could ask Adam Shimi your epistemologist.
Connor: Yes, but that’s actually one of the things interesting. So here’s the thing. It’s not bad. People are just confused about it. If you want to create a logic and it’s halting complete and you want a reason about a halting complete logic, okay, that’s fine. You can do that. That’s a thing you want to do. But you have to be very clear that this is not real. Halting oracles do not exist in reality. So any proof that has, for example, had to do with physics that relies on the law of excluded middle, I say is false. You made a mistake because your assumption of the law excluded middle does not hold in physics, because physics is computable and you don’t have halting oracles in physics.
Connor: So therefore if you use any kind of mathematics in physics that is based on the classical logic, you should be suspicious of it. This also has to do with like real numbers, for example, require like real numbers, for example, have un-computable numbers. So numbers that like are also like have this property of like not being computable. And then there are proofs that require real numbers to work. And I just say those are cursed. Those do not apply to reality. There is some fake other reality where hyper computers exist. And if you want a reason about this fake other reality, okay, that’s fine. You know, we can do that, but don’t then apply the things you learn about this fake, other reality to our reality. So there’re other logics such as intuitionist logic that doesn’t have this problem. And intuitionist logic is literally what all of programming is formalized in.
Connor: So like functional programming or like proof checkers are all formalized in intuitionist logic. And that is fine. So if your proof works in a proof checker, that’s okay. If you can formalize the intuitionist logic that’s okay. But, and that’s, I think the way we should be thinking about. So here’s the thing: it’s like Connor, this, none of this shit fucking matters. You goddam nerd. No one gives a shit about… And I’m like, okay, you’re correct. But. So I think it’s true that this almost never matters. It’s like almost nowhere will you actually find something where intuition is logic and classical logic disagree in the real world. But I think there are some edge cases where they do disagree and that causes great confusion. One of these, which is relevant to EA, is infinite ethics. ⬆
What it Implies for Infinite Ethics
Connor: So in infinite ethics, you get these really famously weird paradoxes where like, okay, well there’s infinitely different universes. Well then obviously like manipulating other universes is like infinite value. So this universe actually has zero value and like nothing I do here has any value whatsoever. Like weird stuff like that. And this is like, especially if you accept hyper universes. If you think there might, if you assign non-zero bayesian evidence to, or like credence to the existence of universes with hypercomputers, those universes have infinitely more value than any number of non-hyper universes. So therefore you must assign zero value to any of the universe that are not hyper universes. And like all these like weird things. And like, this is like obviously just, and like I look and so the infinite ethics, I think philosophers are sometimes like, wow, this is such a deep paradox.
Connor: And I’m just like, it’s just wrong. You made a mistake. This is a glitch. Your program crashed. Like the solution is assign zero value to HyperTuring universes. Zero, not 0.1. Zero. And then you don’t get this glitch. And this is what you would have, for example, in intuitionist logic… The intuitionist laws, you would say, any proofs that you do about hypterturing universes, don’t halt. So you can’t reason about them. And then this whole, a lot of these paradoxes just kind disappear. There’s also this one physicist whose name I forgot who argues how like a lot of the paradox, like black holes and stuff actually go away. If you formalize them in intuitionist logic, I don’t understand physics enough to comment on that.
Connor: But I have an intuition that a lot of like weird edge cases around like infinities are because of law of excluded middle. And like, because we formalize things as because basically we’re using the mathematics of a different universe. We’re using mathematics of a halting oracle universe, but we don’t live in a halting oracle universe and we shouldn’t use this math. We should use the math that is appropriate to the universe.
Michaël: Right. So it’s in some sense saying that we should only use the math where the halting Oracle can compute their stuff?
Connor: Well, doesn’t exist. Our universe doesn’t have halting oracles.
Michaël: Right.
Connor: So we should only use the math that does allow halting oracles and this breaks a bunch of nice proofs. So the mathematicians will then always like wail and cry. “Like what now we can’t prove all our favorite statements” and I’m like; okay, sorry. Your favorite statements are about universes that aren’t ours. You can play with those if you want. That’s okay. If you want to formalize your like set theory or whatever and reason about like crazy hierarchies of infinities or whatever, be my guest. But don’t get confused when you try to reason about reality or. Two places where this breaks is physics and decision theory, is that I think if you formalize decision theory, for example, of an AGI with these like non-halting logic’s, you will get glitches. Basically you will get weird broken results and like demons trying to, so like optimization demons, trying to manipulate the prior of the agent and stuff like that.
Michaël: Is it something related to, let’s say Pascal’s mugging where if you had like very weird scenarios with different universes with like very high EV, they would like stop on this problem? ⬆
The Ultra Finitist View
Connor: Yes, this is related to that. So there are versions of Pascal’s mugging that do not require this, that aren’t fixed by this. Well, there’s an even stronger version of my take, which is the ultra finitist take, which is the absolute Chad giga-brain take.
Michaël: Go, go for it.
Connor: The take is large integer don’t exist. You can only count this high bro. And yeah, the number’s bullshit. Like that is the truly giga-brain take. And I don’t know if I’m all the way at the ultra finitist view So I’m currently what you would call a finitist. I accept countable infinities, but not uncountable infinities. So the infinity of integers is okay, but the infinity of real numbers is not okay.
Connor: Then the ultra finitist say no, there’s, there’s finite integers. Fuck you. Which is the most giga brain take. And the thing is like the ultrafinitist are in a very important way, obviously, correct. In the sense that there obviously is a largest integer, you can encode in physical universe.
Michaël: Right.
Connor: Like the universe, there’s a speed of light. There’s a limited amount of information. There’s a limited of neg-entropy. There is a largest integer in physics, not in mathematics and at mathematics, there’s obviously arbitrarily large integer. But in physics, there is actually a largest integer. And for example, I think there is a good argument to be made from the decision theory perspective of an embedded agent in physics that any proof or any like knowledge that requires steps that are larger than that integer should just not be considered in your hypothesis space, because you can never encounter them. There’s never going to be a scenario that is dependent on a piece of information that is that long because doesn’t fit into the universe. It just literally doesn’t fit. So you will never encounter this. So you can assign your zero credence to it.
Michaël: Just put like a low prior to like any number bigger than. What is the biggest number again, Graham’s number?
Connor: That’s a very, that’s one of the very large, that’s not the biggest, I think biggest one is Bigfoot, which is like the largest number you can express in like a Google of like first order logic, symbols or something like that. I think it’s like the largest one or like one of the largest ones it’s like ridiculous. ⬆
Other Twitter Questions
Michaël: Yeah. So this one’s pretty funny. I guess there’s like another, let’s say fan art, no art service. No, sorry. Fan service from Twitter. I might cut this. Don’t worry. What is your favorite anime and who is your favorite waifu? I might cut this.
Connor: Of course, of course. So again, context for this one. It’s, it’s quite legendary how much I hate anime. I hate it so much. It’s that’s not even that I hate, I do hate it, but also like, I don’t know. My favorite anime is One Punch Man, which is actually good. At least the first season. I didn’t see the second one. And my waifu is Muman writer.
Michaël: I think I, we actually talked about it last time. Sorry about this. And yeah, last one. How often do Connor Leahy encounter a problem and just thinks like; “Hmm. Maybe we should just like stack more layers lol?”
Connor: Often when people on Twitter say how deep learning can never do X, not so often in my daily life.
Michaël: Cool. Yeah. I think that’s it for the podcast. It was a pleasure to have you again. Hopefully it’s not the last time. Maybe we could do one more before AGI.
Connor: Yeah. Maybe if we’re lucky,
Michaël: Any last word? I don’t know. ⬆
Conclusion
Connor: It was a real pleasure. I guess I just want to stress how much I think alignment is a real, real problem and things aren’t going well, but giving up hope is also not an option. It is a solvable problem. The real thing I want to say is it is a solvable, technical problem. It’s a thing that we humans can do. And I think there are paths forward that we can, that can lead to solutions that are worth trying. We just have to try. I’m hoping with Conjecture, hopefully also, if we can raise some more funding near, as soon, we’ll be able to walk down some of those paths.
Connor: But I just really wish that more people would, would give a try, see what they can do. It really is not just the most important. It’s also the coolest problem. Like it’s such a cool problem. If you have a curious mind out there and you want a really good problem to work on and at least satisfy your curiosity, have you something really interesting to working on, working side by side a lot of really interesting, fascinating people and maybe save the world, give it a shot ⬆