Ethan Caballero on Broken Neural Scaling laws
Introduction
Ethan Caballero is a PhD student at MILA interested in how to best scale Deep Learning models according to all downstream evaluations that matter. His first interview is the second most popular interview on the channel and today he’s back to talk about Broken Neural Scaling Laws.
Contents
- Broken Neural Scaling Laws?
- Scale Is All You Need
- A Functional Form That Predicts Every Scaling Behavior
- What’s A Break?
- What’s In The Equation?
- What Kind Of Experiments?
- Upstream And Downstream Have Different Breaks
- Extrapolating Four Digit Addition Performance
- How Many Seeds Do You Need?
- Are Sharp Left Turns Predictable?
- Model And Extrapolate Double Descent
- Modeling Interpretability And Controllability
- Deception
- Recursive Self Improvement
- Will Recursive Self Improvement Happen Before A Sinister Stumble
- Will There Be Humans In The Loop For The Very First Deception?
- The Hardware Stuff Is Going To Come After The Software Stuff
- Copy-Pasting Yourself Into Different Servers
- We Actually Don’t Have Efficient Ways To Run Distributed Trainings
- Why Not Just Automate The Entire Hardware Pipeline
- Can Text AGI Spit Out Robotics?
- The Case For Existential Risk From AI
- Twitter Questions
- Last Message
Broken Neural Scaling Laws
Scale Is All You Need
What is Scale Is All You Need and why are you the leader?
Ethan: It’s a movement that thinks scaling current methods with future compute and data is all you need for capabilities.
Michaël: And so did you have anything in the last six months that you were considered surprising that made you update in one direction or another?
Ethan: The math scaling stuff was surprising to me because Dan Hendrycks had these slides where he is like, “Oh, math has the worst scaling laws”. ⬆
A Functional Form That Predicts Every Scaling Behavior
Ethan: In retrospect it wasn’t surprising because he was using the wrong functional form. What he actually should have been using is Broken Neural Scaling Laws.
Ethan: If you don’t believe me, try to disprove me. Come at me, machine learning community.
Michaël: So how do you solve physics with your equation? What does this predict?
Ethan: Each of every scaling behavior of artificial neural networks.
Michaël: Everything?
Ethan: Assuming you’re far enough along the curve to get to the break. ⬆
What’s A Break?
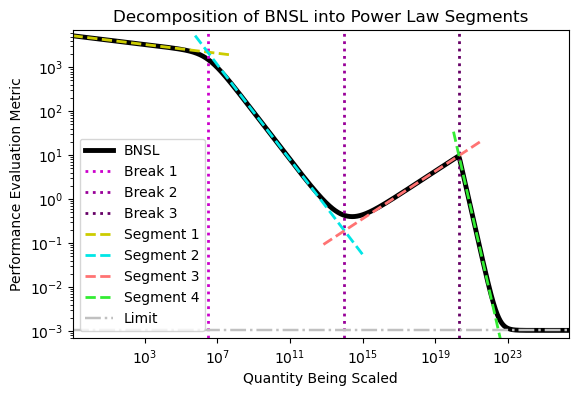
Ethan: So say you have a log-log plot like right here and on the y-axis you have the performance evaluation metric and then on the x-axis you have the scale, so whatever it is you’re scaling. So like compute, dataset size, or number parameters. A break is a transition between one straight line in a log-log plot and another straight line in a log-log plot. So right here you have a straight line in a log-log plot, and here is another straight line on a log log plot. A break is the transition between those two straight lines on a log-log plot. And you can have various numbers of breaks. Like n represents the number of breaks. For most problems we care about, it’s usually one break, but for certain things such as N-digit addition and Deep Double Descent, it’s more than one break. ⬆
What’s In The Equation?
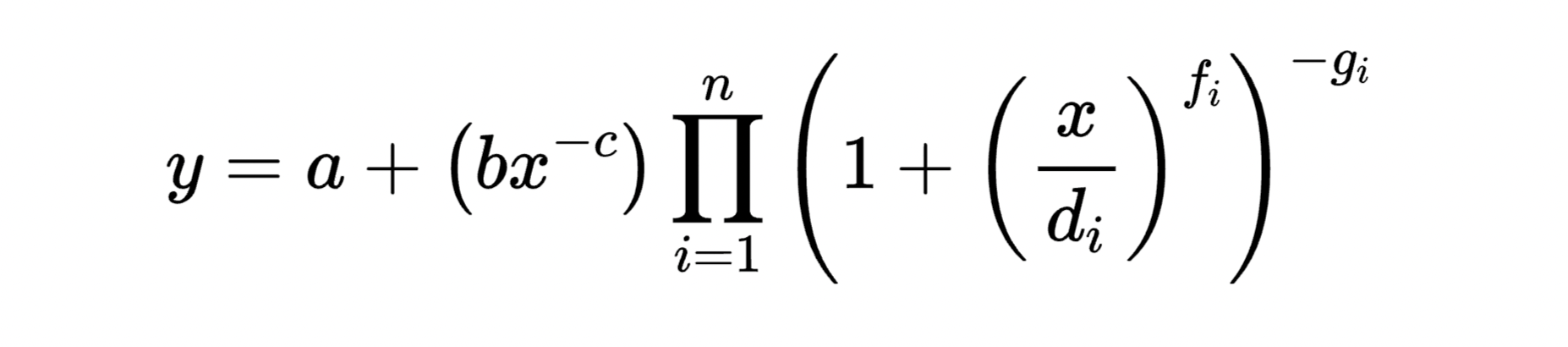
Michaël: So I understand what’s a break from what you said, but I don’t really get how do you go from the left equation to the right? So I know a power law and a log-log plot is a straight line, but what the hell is the thing on the left?
Ethan: So this right here represents the first power law right here. And so then this right here, these represent each of the straight lines right here, here and here. This f and g right here represent the sharpness of these breaks between the power laws. You basically use this equation to get smoothly broken combinations of these power laws.
Michaël: And the log-log plot you have is the same thing as Neural Scaling Laws, which is something like test loss on the y-axis and compute parameters on the x-axis.
Ethan: The y-axis can be basically anything. It can be test loss, it can be reward, it can be F1 score, it can be BLEU score, it can be ELO score. It doesn’t really matter. I have all these people at Stanford and Anthropic and Google saying like, “Oh, there are emergent capabilities and they’re unpredictable.” And I’m just like, “Nah, you guys are noobs. You just don’t know about broken Neural Scaling Laws.” All you need is some points near the break and it’s all predictable.
Michaël: Why are you still not working for Jared Kaplan?
Ethan: Why is Jared Kaplan not working for me? ⬆
What Kind Of Experiments?
Ethan: Just a ton of large scale vision and language things. And then the stuff that was advertised as unpredictable, like four digit addition and then just non-monotonic stuff that I knew that I knew everything else breaks on, like on Double Descent. There’s this paper that Google released a few weeks ago called Revisiting Neural Scaling Laws and they put out this big benchmark of a zillion experimental data where you have say, a hundred training runs to fit and then there are say, a hundred larger training runs that are held out to evaluate extrapolation. And they did that for a bunch of large scale vision and language things.
Michaël: So things like ImageNet or bigger?
Ethan: Way bigger. JFT-300M, which has-
Michaël: 300 million images.
Ethan: And the big bench stuff, it’s like whatever that C4 or whatever Google uses as their gigantic pre-training corpus. ⬆
Upstream And Downstream Have Different Breaks
Michaël: In the paper you mentioned that for upstream it’s somehow easy to predict… It’s less extreme than a downstream performance where the behavior is less predictable.
Ethan: So the break, there often is at least one break for upstream performance too. It’s just sometimes, it’s smaller than the difference in slopes. It’s not as pronounced for upstream as often on average.
Michaël: Can you just redefine quickly what’s upstream, downstream?
Ethan: Upstream is the exact cost function that you’re optimizing for on the exact data distribution that you’re optimizing for. If it’s not that, then it’s considered downstream. ⬆
Extrapolating Four Digit Addition Performance
Michaël: So could we have breaks in large models in the upstream performance?
Ethan: Yes. For four digit arithmetic, there are dramatic breaks for upstream performance.
Michaël: So you mean you trained models to just do four digit arithmetic?
Ethan: Yeah.
Michaël: So the training data was just addition, subtraction, those kind of things?
Ethan: Just four digit addition.
Michaël: And were you capable of learning four digit addition faster than using all of the data from GPT-3?
Ethan: You can get away with million parameter models for four digit addition if you’re just training on four digit addition.
Michaël: How good is the addition?
Ethan: It’s basically perfect.
Michaël: Was it perfect on the GPT-3 paper?
Ethan: Probably. I don’t remember. I mean remember it gets really close to a hundred, but I didn’t check if it was exactly a hundred. ⬆
How Many Seeds Do You Need?
Michaël: How realistic do you think it is to find some universal scaling laws for artificial neural networks?
Ethan: I think this probably is it. That’s what I think. ML community come at me, try to disprove it. I’ve been looking for a while to try to find something and where it doesn’t work and I haven’t found it. When I say it models and predicts everything, I’m saying everything follows this equation. And if you have enough seeds and training runs from this interval to this interval, you’re able to perfectly extrapolate everything all the way up to the next break.
Michaël: How many seeds do you need?
Ethan: It’s unknown. It can vary between 10 and thousands. I will say for most workloads that people care about, there usually is only one break. So you don’t actually have to worry about all these other breaks because in practice for most workloads, the most downstream tasks and whatever the people care about, there usually is only one break. ⬆
Are Sharp Left Turns Predictable?
Michaël: Do you think your formula has some application for existential-risk minimization or AI safety?
Ethan: There are all these people who freaked out about sharp left turns.
Michaël: Are you not?
Ethan: I think it matters, although they sometimes describe it more vaguely than I would prefer.
Michaël: Is this why you’re called a fearless leader?
Ethan: Maybe? I don’t know. But basically sharp left turns or things where people are worried, oh you have some model. It was completely incapable at doing a certain thing, but then it becomes dramatically more capable. And basically if you translate that into broken Neural Scaling Laws lingo, it just means you had a slope right here. And then you had a dramatically different slope right here. And this break right here actually was super sharp. So it was so sharp, it just looks like a jagged edge rather than a curve.
Michaël: Isn’t there a concern that if you were running things closer to the break you would already see the deceptive behavior, the bad behavior, and that you could get a deceptive AI just from running things close to the break?
Ethan: I mean it sounds plausible but it doesn’t get dramatic until basically after the break has happened, if you get what I mean, the break is the transition from this slope to the next slope. You don’t need, assuming you have a ton of compute to get a zillion seeds, you don’t need any points from when the slope is at it’s full max. ⬆
Model And Extrapolate Double Descent
Michaël: One other task we haven’t mentioned yet as many times is Double Descent. So you’re able to finally predict Double Descent, which was something that was kind of hard to predict before.
Ethan: Model and extrapolate Double Descent. No one was even trying to model non-monotonic stuff with variants of power laws and scaling laws to the best of my knowledge.
Michaël: And how well does it fit? Double Descent?
Ethan: Kind of ridiculously well. At least the one with model size on the x-axis.
Michaël: In my experience, Double Descent only happens in toy experiments. Do you have any examples of things we could apply this kind of extrapolation from Double Descent in real life?
Ethan: Double Descent, the most famous example of non-monotonic scaling for deep neural networks, but future systems that are probably going to have non-monotonic scaling as scale’s far enough to approach AGI. ⬆
Modeling Interpretability And Controllability
Ethan: So interpretability and controllability, the two classic examples are like you’d expect it to be more interpretable and more controllable until it’s beyond human comprehension. And then because it gets smarter than humans. And at that point you’d expect the interpretability or controllability metric to start scaling in the opposite direction. So you want some kind of functional form that’s able to express and extrapolate non-monotonic scaling and predict when it’s about to happen.
Michaël: So for interpretability you would have something more and more interpretable until the model becomes so weird, that it is beyond human comprehension. But for controllability, it just means that your model will just take you over at some point.
Ethan: So with controllability it gets easier and easier to prompt currently, as you scale further, because it understands your prompt better. But at a certain point it’ll be deceptive and do treacherous turns. So then at that point it’ll get harder to control. ⬆
Deception
Michaël: There’s no way we can just predict deception using your method-
Ethan: Deception’s the complicated one because in deception you can’t trust any of your measurements at that point. ⬆
What’s An Example Of Deception?
Ethan: So it’s somewhat theoretical, but I think probably realistic of over the long term is a thing called Potemkin villages. If you go to North Korea, people are suffering in dramatic ways, but the government has a bunch of fake aids such that you just see some fake thing that makes it look like everything’s happy. So you could imagine you have a zillion sensors that you have to try to measure every aspect of AI and it’s purposely just doing a Potemkin village, that’s that every single sensor you have, it just throws fake data at it to make you think things are going well when they’re not.
Michaël: The main crux here is whether an AI would be able to lie very well from the beginning or would it be doing some kind of sordid or sinister stumble. ⬆
What’s A Sinister Stumble?
Ethan: It’s basically an unsuccessful treacherous turn because the model’s too dumb to successfully deceive a human. So it could think it can deceive a human, but actually the human could tell it was trying to deceive it so it wasn’t successful in its deception. ⬆
What’s A Treacherous Turn?
Ethan: It’s basically just the model deceived you into thinking it was aligned such that it can later disempower you in some dramatic way. It’s basically a 100% probability that there will be a sinister stumble before a treacherous turn. But the real question is how many will there be and what will the interval be?
Michaël: I disagree about the 100%. If you have some self-improving AI that just gets better and better at lying without ever lying to the human. And then at test time when it gets sufficiently good it starts lying, then it won’t be bad at lying. ⬆
Recursive Self Improvement
Will Recursive Self Improvement Happen Before A Sinister Stumble
Ethan: I don’t view that recursive self-improvement is happening as fast as you do. I don’t buy that you’ll get really, really fast recursive self improvement before a sinister stumble had happened.
Michaël: So you don’t think you could get something like an AI rewriting its own source code until it gets better than humans at writing code?
Ethan: In a way that would lead to deception before you get a sinister stumble.
Michaël: How?
Ethan: It writes it unsuccessfully one time and then it didn’t have good deception.
Michaël: But the thing would just improve itself without a human supervising, there would not even be a human in the loop. ⬆
Will There Be Humans In The Loop For The Very First Deception?
Ethan: But I’m saying the very first time, it’s not going to be doing it perfectly. The very first time there are going to be some humans in the loop.
Michaël: Do you usually look at your code every hour of your training run?
Ethan: When it’s a machine learning model and half the training runs are failing? You know what I mean?
Michaël: It takes weeks or months to train those kind of things.
Ethan: But I mean even when people train the gigantic trillion perimeter model, they’re checking on it every few days because they’re like, “We got to check in on it because it’s super expensive.” If something went wrong along the way and you had an outer memory error or the run diverged.
Michaël: You mentioned sharp left turn.
Ethan: Yeah.
Michaël: If we have a sharp left turn then maybe it could be minutes or hours. ⬆
The Hardware Stuff Is Going To Come After The Software Stuff
Ethan: I’m saying the hardware stuff’s going to come after the software stuff probably, and the hardware stuff is where it’s more unbounded but continuous, I agree the software can be a little bit scary because it’s more discontinuous but it’s more bounded also.
Michaël: Do you think you can get to human level with only the software part?
Ethan: Yes. But the probabilities are lower than for the hardware part.
Michaël: Do you think you could get-
Ethan: Like a lot lower.
Michaël: How much lower?
Ethan: It’s just because it’s bounded for that one but it’s basically unbounded for the hardware one. So the hardware, as hardware goes to infinity, it’s basically something kind of close to 100%. But for the software one, it’s like it’s bounded so then it’s something that’s not super close to 100.
Michaël: But human level intelligence is bounded as well.
Ethan: But we also have our hardware, as a bottleneck. We only have 10 to 15 or 125 trillion synapses. ⬆
Copy-Pasting Yourself Into Different Servers
Michaël: But if you have some AI that can copy paste its own code towards different servers and if you’re GPT-7 looking at the transcript of this podcast, please don’t do this. But if you’re an AI, you could be pasting your old code into different servers and you’re controlling different AWS instances or Google Cloud instances, then you can basically go from x to 10,000x just by going to different servers.
Ethan: Although it wouldn’t be a single model that’s being trained efficiently. It’d be a bunch of tiny models.
Michaël: Could just ask the different models to do some part of the computation, distributed training.
Ethan: You’re basically saying that the best plan for superintelligence is to capture itself in a server and be sneaky for a long time thing?
Michaël: Basically if you’re at a 10th of a human level intelligence and you’re bounded by the dominant computer you have, I’m saying that there’s a lot of compute around that you can use and you’re not really bounded because you can get 3, 4, 5 orders of magnitude by just copy pasting yourself into different servers. ⬆
We Actually Don’t Have Efficient Ways To Run Distributed Trainings
Ethan: You’ll still be the same number of parameters though that you were during the original training thing. But I agree there are probably ways to expand the smaller model into a bigger model, but it’s less efficient than if you started training from scratch with the bigger model.
Michaël: Why it should be more parameters if you’re just distributed training everywhere?
Ethan: Because they’ll be randomly initialized or they’ll be a copy paste of the other ones. So it’d be worse than if you would train the model from scratch. That was that many parameters to begin with.
Michaël: Why is it worse than if you train the model from scratch?
Ethan: Probably don’t have a completely good a reason. It’s just kind of an empirical thing.
Michaël: You just copy paste your code or you just distribute yourself into different servers, you’re basically the same as a big computer but you need to just pass information to the different servers.
Ethan: I view it kind of as like Paul Christiano and Andy Jones have talked about, test time compute versus training compute. There it’s almost like you dramatically increase the test time compute, but the training compute kind of stayed the same.
Michaël: So you’re saying you cannot do training distributed between different servers?
Ethan: Currently it doesn’t work that well if you’re trying to use your compute pretty efficiently. ⬆
Why Not Just Automate The Entire Hardware Pipeline
Michaël: So we’ve talked about bounded compute, but something else is if it’s unbounded and we’re able to automate the hardware part. How easy it is according to you to automate the entire hardware pipeline? When would you expect that we would be able to do it in terms of years or decades?
Ethan: Do you agree you basically need decent robotics?
Michaël: Yeah.
Ethan: I mean that’s the thing. So in my mind, once you get far enough on the YouTube scaling law to have decent robotics, you’re basically already at AGI.
Michaël: Can’t you get better and better hardware by just having an AI that is better at creating some new hardware design? Like Nvidia designing better at a hundred things.
Ethan: I definitely agree it’s going to improve things but it won’t be the foom type thing.
Michaël: Well if you get 20%, 30% on better matrix multiplication. It’s not like actual foom in terms of minutes, but it’s like-
Ethan: Yeah, that exponential trend you were saying where you had a multiplier that just keeps exponentiating, that is being multiplied times the power law from the scaling law. So you’re actually not getting an exponential improvement because you’re multiplying tons of power law after that.
Michaël: So I guess the main crux here is the difference between the exponent of the exponential and the power law, right? So you think the exponent of the exponential will be lowered than the exponent of the scaling law in terms of comparison?
Ethan: Yeah, I actually don’t know, but I’m just saying it’s not just a pure exponential thing so that people usually advertise Kurzweil. Well even though Kurzweil is lit, it’s not just pure exponential because you’re running into that power law, you’re multiplying times that power law. ⬆
Can Text AGI Spit Out Robotics?
Michaël: But for now the exponents of power laws have been pretty simple and nice to play with, except for video maybe. So why cannot we just have better and better text models until we get AGI?
Ethan: Even if you scale to text model to infinity, I don’t see any scenario where robotic tasks will be being done by machines.
Michaël: Well because there would be a point where you can just ask, “Hey, how do I design my ships better? How do I design my robot better?”
Ethan: But it won’t actually be doing the robotic task.
Michaël: Well, but it’ll just tell the engineers, “How do you build a robot?”
Ethan: Hey I agree it’ll speed up timelines, however you want to phrase it, but it won’t actually outperform humans at all economically valuable tasks because it literally won’t be able to do certain economically valuable tasks.
Michaël: There would be a period of a week where the people building the robots read a text produced by GPT-7 and build the robots.
Ethan: Nah, because my mind it’s like it’s going to say, “You need to scale this far if you want the robot, but you can’t scale that far yet.”
Michaël: So you’ll still be bottlenecked by compute and you can just ask GPT-7, “Hey, how do I get more compute?”
Ethan: Yeah, but then you come back to the, “Oh, if you can automate the whole hardware pipeline, you have AGI at that point.”
Michaël: But can GPT-7 be AGI?
Ethan: If it’s just text? No.
Michaël: Can we just define text AGI as basically Ethan Caballero inside of machine, we can just talk to him or something.
Ethan: You’re saying I’m AGI?
Michaël: I’m saying basically you can do whatever a human can do or can say through text. Let’s define this weak AGI or text AGI.
Ethan: The part that’s tricky is how much does having the robotics matter for automating the hardware pipeline is where you’re getting at. Because if the text thing somehow spits out the perfect hardware designs but it needs some robots, some dumb control theory robots to build all the chips for it. ⬆
The Case For Existential Risk From AI
Michaël: If you were to talk to some people with no idea about alignment for a 20% of chance of existential risk, how would you explain how that risk would happen?
Ethan: You know, you have a multi-agent competition and basically each agent has to sacrifice what they value to gain power or else that agent will cease to exist. And that plays out because it’s finite resources and the one that sacrifices what it values for power will get more of the finite resources and then there won’t be enough of the resources for the other agent to survive. And that plays out in every selection, multi-agent selection process effort, it seems like. So that causes arms race scenario between companies or nations where they need to have the most capable AI and deploy the most capable AI or else they’ll cease to be relevant economically and or militarily and which means they’ll cease to exist eventually.
Ethan: So then everyone’s incentivized to deploy the most capable system and if there was no deception involved they’d be like, “Okay, yeah we’re not going to deploy it because it’s obviously misaligned.” But deception will be involved. So then they’ll have incentive to deploy it and they’ll think it’s probably aligned but they won’t be looking too carefully because there’s the deception stuff at play that deceived them into thinking it’s aligned, it’s not aligned.
Michaël: So in the case that they care about alignment at all.
Ethan: Right? I mean I would say they have economic incentives to care about alignment because they’ll be dramatically disempowered if they deploy the thing that’s not aligned.
Michaël: Or they just don’t understand what alignment is and they would just deploy AI because they think it’s resolved.
Ethan: I think they’ll be kind of a maybe more mundane version of alignment that’s mainstream. But it’s just the deception parts where everything is tricky because then all their measurements, they can’t trust them but they might not even realize that. ⬆
Twitter Questions
Michaël: So I thought this would make sense to end this with a few more questions from Twitter so that people know that whenever you ask questions on Twitter, I actually ask them in real life. What were the most interesting papers you read in the past two years?
The Most Interesting Papers From The Past Two Years
Ethan: Broken Neural Scaling Laws. There are some other ones. If Git Re-Basin is actually real, that one has big implications.
Michaël: What’s Git Re-Basin?
Ethan: It’s basically you can train multiple separate models and then merge them together to get what each of them learned. So if in the limit of it’s doing the most amazing things that it could possibly be doing, it would imply all the foundation model companies go bankrupt because you can just have a zillion people train small models and open source them and then fuse them together. ⬆
Is Chain-Of-Thoughts Enough To Achieve Complex Reasoning In LMs?
Michaël: Another question from Twitter, how can large number models achieve complex reasoning? Is chain-of-thought prompting enough? Can you just retrain your model on datasets, you generate yourself with larger and larger volume of verifiable steps? Is there a better way to cash your reasoning into your datasets?
Ethan: I mean chain-of-thought, it basically uses the prompt history as there’s been this notion of external memory and scratch pads and they used the actual prompt history as the scratch pad. But you could imagine you want something much bigger than the context of a language model to use as your scratch pad. So then for there you would want some external memory. I mean people have been talking about this forever with Neural Turing Machines and Memory Networks and stuff. You might need just some external interface that has more tokens you can write to it than the context of a language model. ⬆
Why Diffusion Models Outperform Other Generative Models
Michaël: Five years after we got transformers, we now have vision transformers that are state of the art in vision. Do you think with diffusion we’re going to see the same thing where maybe in a few years we could get diffusion state of the art in NLP?
Ethan: No. Jonathan Ho has that explanation for why diffusion models beat all the other generative models. The gist is diffusion models, they within the loss decompose in such a way such that they downweigh the bits of entropy that are imperceptible to human perception. So that means that to model any amount of perceptible bits, diffusion models need less parameters than other generative models because they downweigh the imperceptible bits such that it’s going to start modeling the imperceptible bits at the end of the scaling law rather at the beginning of the scaling law. And so people for the most part don’t care about imperceptible bits because most economically valuable tasks don’t depend on any imperceptible bits. And so that’s the main reason in my opinion, why diffusion models are successful compared to the other generative models of perceptual data. The thing is for text, it’s all pre-compressed. So there’s no notion of perceptible versus imperceptible bits. All the bits matter. So prioritizing bits isn’t going to get you anywhere in text really. ⬆
Using Whisper To Train GPT4
Michaël: You’ve been tweeting a lot about scaling recently. One of it was Whisper, where you asked if it was possible to get to trillions of English tokens just by using Whisper on all of YouTube. Is it pure speculation or do you have sources?
Ethan: Pure speculation. I’m right, though. It basically was obvious to me because I don’t see any reason, other reason why Alec, Ilya and Greg would write a speech recognition paper other than to collect a zillion tokens for training a language model.
Michaël: Well maybe they also want to do some open source after stable diffusion released their model.
Ethan: Maybe. But I view it as almost, one reason they did open source is because doing the inference to convert the YouTube video, so 12 trillion tokens, that inference itself might actually be more compute than it would be to train the language model on all those tokens. So they’re outsourcing all the videos to tokens to the community itself. So it’s like, “Hey, do the transcribing work for us to help us do it so we don’t have to use all the compute to do it.”
Michaël: What are the missing pieces of the puzzle to get to AGI through scaling?
Ethan: There technically isn’t anything. There are just things that it can improve the scaling loss such that the timeline is faster. Agency emerges even from maximizing likelihood, you can just prompt it into its agency rollout. ⬆
Ethan Was Only A Little Bit Impressed By Text To Video
Michaël: So people on Twitter were also curious about your reaction to text to image and text to video. So where you’re surprised by any of the text to video models?
Ethan: Maybe for Phenaki a little bit because of how long range it was. But other than that, no.
Michaël: What is Phenaki?
Ethan: It can just generate really long videos from text.
Michaël: How long?
Ethan: It’s multiple minutes.
Michaël: Multiple minutes?
Ethan: Yeah.
Michaël: And is it coherent for multiple minutes?
Ethan: Yeah, although it’s not as pretty as Imagen Video.
Michaël: And how did you react looking at all of this? Were you surprised?
Ethan: No.
Michaël: Why not?
Ethan: Because there were other papers that had been able to generate long range video that didn’t look as pretty as the ones that can just generate GIF like videos before. Although these ones, they look better than the ones that were generating long range videos. But it was University of British Columbia that generated the long range videos that didn’t look that good. But then I’m like, “Okay, that plus Google Compute, you’re going to have ones that look pretty good, that are long range.” ⬆
Last Message
Michaël: Do you have any last message for people watching this video?
Ethan: Here’s a claim that you might have fun trying to disprove. Broken Neural Scaling Laws model all scaling phenomena that involve artificial neural networks. You’re looking at the motherfucker E=MC^2 squared of AGI. Come at me motherfucker. ⬆