David Krueger On Academic Alignment
David Krueger is an assistant professor at the University of Cambridge and got his PhD from Mila. His research group focuses on aligning deep learning systems, but he is also interested in governance and global coordination. He is famous in Cambridge for not having an AI alignment research agenda per se, and instead he tries to enable his seven PhD students to drive their own research.
(Our conversation is ~3h long, you can click on any sub-topic of your liking in the outline below and then come back to the outline by clicking on the green arrow ⬆)
Contents
- Incentivized Behaviors and Takeoff Speeds
- Social Manipulation, Cyber Warfare and Total War
- Instrumental Goals, Deception And Power Seeking Behaviors Will Be Incentivized
- Long Term Planning Is Downstream From Automation From AI
- An AI Could Unleash Its Potential To Rapidly Learn By Disembugating Between Worlds By Going For a Walk
- Could Large Language Models Build A Good Enough Model Of The World For Common-Sense Reasoning
- Language Models Have Incoherent Causal Models Until They Know In Which World They Are
- Building Models That Understand Causality
- Finetuning A Model To Have It Learn The Right Causal Model Of The World
- Learning Causality From The Book Of Why
- Out Of Distribution Generalization Via Risk Extrapolation
- You Cannot Infer The Right Distribution From The Full Support And Infinite Data
- You Might Not Be Able To Train On All Of Youtube Because Of Hidden Confounders
- Towards Increasing Causality Understanding In The Community
- Causal Confusion In A POMDP
- Agents, Decision Theory
- Causality In Language Models
- Recursive Self Improvement, Bitter Lesson And Alignment
- Recursive Self Improvement By Cobbling Together Different Pieces
- Meta-learning In Foundational Models
- The Bitter Lesson Does Not Address Alignment
- We Need Strong Guarantees Before Running A System That Poses An Existential Threat
- How Mila Changed In The Past Ten Years
- How David Decided To Study AI In 2012
- How David Got Into Existential Safety
- Harm From Technology Development Might Get Worse With AI
- Coordination
- David’s Approach To Alignment Research
- The Difference Between Makers And Breakes, Or Why David Does Not Have An Agenda
- Deference In The Existential Safety Community
- How David Approaches Research In His Lab
- Testing Intuitions By Formalizing Them As Research Problems To Be Investigated
- Getting Evidence That Specific Paths Like Reward Modeling Are Going To Work
- On The Public Perception of AI Alignment And How To Change It
- Existential Risk Is Not Taken Seriously Because Of The Availability Heuristic
- How Mila Changed In The Past Ten Years
- Existential Safety Can’t Be Ensured Without High Level Of Coordination
- There Is Not A Lot Of Awareness Of Existential Safety In Academia
- Having People Care About Existential Safety Is Similar To Other Collective Action Problems
- The Problems Are Not From The Economic Systems, Those Are Abstract Concepts
- Coordination Is Neglected And There Are Many Low-Hanging Fruits
- Picking The Interest Of Machine Learning Researchers Through Grants And Formalized Problems To Work On
- People’s Motivations Are Complex And They Probably Just Want To Do Their Own Thing Most Of The Time
- You Should Assume That The Basic Level Of Outreach Is A Headline And A Picture Of A Terminator
- Outreach Is About Exposing People To The Problem In A Framing That Fits Them
- The Original Framing Of Superintelligence Would Simplify Too Much
- How The Perception Of David’s Arguments About Alignment Evolved Throughout The Years
- How Alignment And Existential Safety Are Slowly Entering The Mainstream
- Alignment Is Set To Grow Fast In The Near Future
- What A Solution To Existential Safety Might Look Like
- Latest Research From David Krueger’s Lab
- David’s Reply To The ‘Broken Neural Scaling Laws’ Criticism
- Finding The Optimal Number Of Breaks Of Your Scaling Laws
- Unifying Grokking And Double Descent
- Assistance With Large Language Models
- Goal Misgeneralization in Deep Reinforcement Learning
- The Key Treasure Chest Experiment, An RL Generalization Failure
- Safety-Performance Trade-Offs
- Most Of The Risk Comes From Safety Performance Trade-Offs in Developement And Deployment
- More Testing, Humans In The Loop And Saving Throws From Hacks
- Would A Human-Level Model Escape With 10^9 years
- How To Limit The Planning Ability Of Agents: A Concrete Example Of A Safety-Performance Trade-Off
- Trainings Models That Do Not Reason About Humans: Another Safety-Performance Tradef-off
- Defining And Characterizing Reward Hacking
- Looking Forward
Incentivized Behaviors and Takeoff Speeds
Social Manipulation, Cyber Warfare and Total War
Michaël: What is the most realistic scenario you have for existential risk from AI?
David: I don’t have any realistic scenarios. It’s not about particular scenarios in my mind, it’s the high level arguments. But, I mean, you can think about it happening through social manipulation and just being able to trick people and getting people to take the actions in the world that you need to in order to seize control. Or you can think about it becomes really easy to actually solve robotics and build robots and we’re doing that.
David: And maybe that’s just because we’ve solved it, maybe that’s because once AI gets smart enough it can just do the AI research or the robotics research necessary to build robots that actually work. Some scenarios that I think people maybe don’t think about quite enough would be geopolitical conflicts that, in the worst case, maybe end up being military conflicts or total war. But even falling short of that, you can have security conflicts and geopolitical conflicts that are being waged in the domain of cyber warfare and information warfare. And I think in normal times, times of not total war, militaries tend to be somewhat conservative about wanting to make sure that the things that they deploy stay under their control. That has partially to do with the amount of scrutiny that they’re subject to. But if you think about cyber warfare and information warfare, I think a lot of that is just really hard to even trace and figure out who’s doing what. And there’s not such an obvious threat there of people dying or things happening in a really direct, obviously attributable media firestorm kind of way. ⬆
Instrumental Goals, Deception And Power Seeking Behaviors Will Be Incentivized
Michaël: But if they’re cyber attacks then you could take control of news or something like this, right?
David: Again, I don’t know what the details are here. What I’m postulating is situations where you have out of control competition between different actors. They really need to sacrifice a lot of safety in order to win those competitions to get a system that’s capable and strong and performant enough that it can accomplish its goals. And I think when you have that situation, at some point, the best way of doing that is going to build things that are agentic, that look like agents. And they don’t have to be perfect homo economicus rational agents. They might be less rational than humans or more rational than humans. But the point is, they’d be reasoning about how their actions affect the world over a somewhat long time span. And for that reason they would be prone to coming up with plans that involve instrumental goal, power-seeking behavior, potentially deception, these sorts of things that are, in my mind, part of the heart of the concern about x-risk from out of control AI is that the power seeking stuff… ⬆
Long Term Planning Is Downstream From Automation From AI
Michaël: I think one of the main concern people have with those scenario is that you would never want to deploy an agent that can reason over a month. All the agents we deploy right now, maybe think for few time steps for maximum, like a day but not max-optimal strategy for a month and manipulate humans for longer time horizons.
David: Yeah I mean. I don’t know. A day seems long to me. That’s the present we’re talking about. I’m saying, in the future, once you have AI that can do something better than people, and ok I have to caveat what I mean by better and we’ll get to that in a second, there then there are massive pressures to replace the people with the AI. At some point, we’ll have, I believe, AI that’s as smart as people and has the same broad range of capabilities as people or at least we’ll have the ability to build that thing. Things that are smarter and can do more things than people. That means that they’ll be able to do long-term thinking and planning better than people. And so, then it’ll be this question of why would we have a human run this company or make these plans when we can have an AI do it better? And the better part is, it might not actually be better. It’ll be better according to some operationalization of better, which is probably going to be somewhat driven by proxy metrics and somewhat driven by relatively short term thinking. On the order of next quarter rather than the coming millennia and all the future generations and all that stuff.
Michaël: Maximum profits for the quarter, maybe taking some outrageous risk that could end up with your token being devalued too much?
David: Yeah. ⬆
An AI Could Unleash Its Potential To Rapidly Learn By Disembugating Between Worlds By Going For a Walk
Michaël: Most people when they think about AGI, they would consider something like a CEO running a company or taking high level decisions. When we reach the level of an AI being able to replace a CEO or replace the decisions of CEO I think we kind of bridge the general level that people care about. I don’t really see a world where you can replace the decisions of someone without things already being very, very crazy.
David: I think the CEO thing… not necessarily, right? CEOs aren’t fully general necessarily. You might say that they are incapable of other things that people need to do. But this question of do things get really crazy, I think probably to some extent, but it’s hard to know. This brings us to another scenario I want to mention for how this could happen. Let’s say that things are going relatively well in the AI governance space. And so, we have some norms or rules or the practices that people are not just building the most agentic systems that they can and releasing them into the wild without any thought or consequences. The practices people are doing more what people have been doing historically and are doing with AI, which is trying to build relatively well scoped tools and deploying those. And these tools might be fairly specialized in terms of the data they’re trained on, the sensors and actuators that they have access to. And I forgot what you asked and how this connects but I’ll just keep going on this story. You could have something that actually is very intelligent in some way, has a lot of potential to rapidly learn from new data or maybe has a lot of concepts, a lot of different possible models for how the world could work. It’s not able to disambiguate because it hasn’t had access to the data that can disambiguate those. And in some sense, you can say it’s in a box. It’s maybe in the text interface box or maybe it’s in the household robot box and it’s never been outside the house and it doesn’t know what’s outside the house and these sorts of things.
Michaël: Like an Oracle with limited data or information about the world?
David: It doesn’t have to be an Oracle but just some AI system that is doing something narrow and really only understands that domain. And then it can get out of the box either because it decides it wants to go out and explore or because somebody makes a mistake or somebody deliberately releases it. You can suddenly go from it didn’t really know anything about anything outside of the domain that it’s working in, to all of a sudden starts to get a bunch more information about that and then it could become much more intelligent very quickly for that reason. People when they think about this foom or fast takeoff scenario, in most people’s minds, this is just synonymous with recursive self-improvement where you have this AI that somehow comes up with some insight or we just put all the pieces together in the right way that it suddenly clicks and it’s able to improve itself really rapidly at mostly at the software level. I think a lot of people find that really implausible because they’re like, “Yeah, I don’t think that there are actually algorithms that are that much better than what we’re using maybe.” Or they just think it’s really hard to find those algorithms and it’ll just be making research progress at roughly the same rate that people are, which is fast but it’s not overnight, like “we go from AGI to superintelligence fast”.
Michaël: Well, I guess our brains are limited in speed, but if we just had a program that can rewrite its own code and just optimize overnight, it would be ten to the nine faster than humans, right?
David: I don’t know. There’s a lot to say about the recursive self-improvement thing. I’m certainly not trying to dismiss it. I’m just saying it’s not the only way that you can get fast takeoff. You have this thing that was actually really smart already but it was kind of a savant and then it suddenly gains access to a lot more information or knowledge or more sensors and actuators.
Michaël: In your scenario of the household robot, let’s say we have a Tesla humanoid or something, this new robot. And it suddenly opens the door and runs into the street. But maybe everything the designers wanted is just optimized for the thing being good in the training data of the house. So I don’t really see how it’ll be good on the new data outside. Maybe it will just crash. But I can see it in on the Internet if you have something, maybe some Action Transformer that is trained on some normal text data to fill some forms and then it goes on Reddit, maybe the Reddit text data will be the same as the Airbnb form data or something. ⬆
Could Large Language Models Build A Good Enough Model Of The World For Common-Sense Reasoning
David: It’s certainly a kind of speculative thing. It’s something that I’m trying to address with my research right now, this question of, will we see this kind of behavior that I’m talking about where you have rapid learning or adaptation to radically new environments? One way that I’ve been thinking about it is this question of does GPT-3 or these other Large Language Models or any model that’s trained offline with data from limited modalities… is it building a model of the world? How close is it to building a model of the world, and a good one that actually includes things like the earth is this ball that goes around the sun and the solar system and the galaxy and here’s how physics works and all this stuff. Humans definitely have some model of the world that roughly includes things like this and it all fits together in obviously not entirely coherent but somewhat coherent way. And it’s really unclear if these models have that because we don’t really know how to probe the capabilities or understanding of the models in depth.
Michaël: Some people have tried for, I think, they tried asking common sense physics questions, maybe just multi-step, two or three steps and it worked pretty well.
David: I don’t know I’m not as up-to-date on all the research and foundation models as I’d like to be. But I haven’t seen anything super impressive in terms of common sense understanding of physical scenarios. I think certainly progress is being made but the last I saw, they still can struggle to manage a scenario where you describe several objects in a room and those objects being moved around by people that get confused by that stuff. But all of that is not necessarily revealing the true capabilities or understanding or world modeling ability of the model because we don’t know how to elicit that stuff. The results you get are always sensitive to how you prompt the model and things like that. You can never assume that the model is trying to do the task that you want it to do because what it’s trained to do is just predict text.
Michaël: You never know actually what the model wants, or sorry, what the model knows until you probe it the right way.
David: It’s a super hard open question. Can we even talk about the model having wants or having understanding and what does that mean? Because you can also say, “Well no, maybe it just has a bunch of incoherent and incompatible beliefs, just much more so than a human does.” Humans have this as well. But we can say humans, as I said earlier, have something coherent beliefs about what the world looks like, how it works, how it all fits together. ⬆
Language Models Have Incoherent Causal Models Until They Know In Which World They Are
David: Maybe Language Models just have nothing like that at all like that but maybe they do or maybe they have all these incoherent causal models. But they have a large suite of possible worlds that they’re maintaining a model of and something like a posterior distribution over or… it doesn’t necessarily have to be this vision thing. But then if they then get new data that disambiguate between these models, maybe they can rapidly say, “Oh yeah, I knew that there was one possible model of what the world was like.” That is basically the same model that you or I would have with all those nice parts. But I just didn’t know if that was the reality that I was in. And now all of a sudden it’s very clear that that’s the reality I’m in or at least the reality that I should be in. That’s the model that I should be using for this context and for the behavior right now.
Michaël: So the language model is living in some kind of quantum physics world and when it observes something it goes like “Oh yeah, I’m in this world now, this is what follows.”
David: Yeah.
Michaël: There was this Simulators post on LessWrong about how any language model can just simulate an agent inside him. I think in some way you can simulate any agent, some level of complexity but you’re not actually an agent, you’re just a simulator.
David: Then you can imagine that when you have this model that seems like it’s really dumb, doesn’t understand how to do this physics stuff and just can’t keep track of four different objects in a room. But then as soon as you actually plug it into a robot body and train it for a little bit on this kind of task, it’s just like, “Oh, I get it. I used to have this massive ambiguity over what world model I should use to make my predictions or my decisions but I’m very able to quickly update and understand the situation I’m in.” There’s no actual learning that needs to take place. It’s just more inference.
Michaël: If you could plug some language model or foundation model that has some very good world model and then you plug in some RL, maybe it’ll understand the world because you can use this agent simulation or just world modeling to interact with the world without having to learn a new model.
David: This is something that’s a really interesting research question and is really important for safety because people have very different intuitions about this. Some people have these stories where just through this carefully controlled text interaction, maybe we just ask this thing one yes or no question a day and that’s it. And that’s the only interaction it has with the world. But it’s going to look at the floating point errors on the hardware it’s running on. And it’s somehow going to become aware of that.
David: And from that it’s going to reverse engineer the entire outside world and figure out some plan to trick everybody and get out. And this is the thing that people talk about on LessWrong classically. We don’t know how smart the superintelligence is going to be, so let’s just assume it’s arbitrarily smart, basically. And obviously, a lot of people take issue with that. It’s not clear how representative that is of anybody’s actual beliefs but there are definitely people who have beliefs more towards that end where they think that AI systems are going to be able to understand a lot about the world, even from very limited information and maybe in very limited modality. My intuition is not that way. The important thing is to test the intuitions and actually try and figure out at what point can your AI system reverse engineer the world or at least reverse engineer a distribution of worlds or a set of worlds that includes the real world based on this really limited kind of data interaction. ⬆
Building Models That Understand Causality
Finetuning A Model To Have It Learn The Right Causal Model Of The World
Michaël: People doing research at your lab are trying to investigate those questions of how much you could generalize from one ability to another. Was that basically what you’re saying? You had some papers or some research on this?
David: It’s actually not anybody at my lab. No, that’s not true. There are two projects that I think are relevant to what we were just talking about. It was about this question of, “if you have a model that learns the wrong causal model of the world, the wrong mechanisms, can you finetune it to fix that problem?”
David: If you train something offline, you would often expect that it’s not going to learn the right causal model of the world because there are hidden confounders. Your data just doesn’t actually tell you how the world works and you just pick up on these correlations that aren’t actually causal. But then if you finetune it with some online data, let’s say you let it go out and interact with the world so it can actually perform interventions and see the effects of doing those actions or making those predictions, then that might fix its model and might quickly lead to having the right model of the world or the right causal model of the world. And what we found in this paper was if you just do naive fine tuning that doesn’t happen. But if you do another kind of finetuning, which we propose, then you can get that. I want to make clear that’s not the only reason to look at this question because the way I just described it sounds like it’s just capabilities research and there’s the scientific question of does it happen with normal fine tuning? But the method itself right now just sounds like, “Oh, that’s something that’s going to make it easier for these models to become capable and understand the world rapidly.”
David: The reason that a method like that might be useful and good for alignment is that it could help with misgeneralization. This ability to understand what the right features are or the right way of viewing the world is probably also critical toward getting something that actually understands what we want it to do. It’s very murky, which I think is often the case with thinking about how your research is relevant for safety.
Michaël: It both helps the AI better understand the instructions but at the same time maybe become more agentic and dangerous. ⬆
Learning Causality From The Book Of Why
Michaël: About causality, I remember in one of your talks, you said that you tried to feed ‘The Book of Why’ to model to see if it would understand causality and, of course, not because you need actual actions or input-output data to understand causality or you need to interact with the world.
David: I said some stuff like that. I talked about The Book of Why. I was trying to present these two competing intuitions and the research that I’m interested in doing is to try and resolve which of these intuitions is correct or get a clear picture. I wouldn’t say… of course not… I would say there’s in-theory argument for why it shouldn’t work, but that in-theory argument doesn’t say how badly it will fail. And it doesn’t necessarily say much about what’s actually going to happen, but I think it is still a compelling argument, one that most people aren’t aware of. ⬆
Out Of Distribution Generalization Via Risk Extrapolation
David: This was for one of my paper Out-of-Distribution Generalization via Risk Extrapolation, bit of a mouthful or REX is the method. And that’s the last paper I did during my PhD.
Michaël: With Ethan Caballero, right?
David: He’s the second author. We have this remark in the paper that’s basically just saying, “Oh yeah, by the way, you can’t expect to learn the correct cause model just from having infinite data and infinitely diverse data.” When you talk to people who are like Ethan, let’s say the scale maximalists, this is a really good argument saying “actually no, this just isn’t going to work.” And I’m not saying the argument is actually true in practice. I’m just saying it’s worth taking seriously. It turns out that what actually matters is the actual distribution of the data and not just having full support and infinitely much data. And that’s because of hidden confounders. ⬆
You Cannot Infer The Right Distribution From The Full Support And Infinite Data
Michaël: What’s the full support thing?
David: Oh, full support. I just mean you see every possible input-output pair, every example… you see every possible example infinitely many times. You’d think that you’re going to learn the right thing in that case. It makes sense intuitively. But it’s just not true because there are some examples where you see the same input with the label as zero and the same input with the label as one. And so it actually depends on the ratio of those two types of examples that you see. And you will get different ratios depending on what kind of data you have.
Michaël: So you’re saying if you have infinitely many examples of the right distribution, you won’t be able to fit a function to approximate it?
David: No. If it’s the right distribution, then you’re good. But my point is the distribution matters. So it’s not just the coverage, but it’s the actual distribution. ⬆
You Might Not Be Able To Train On All Of Youtube Because Of Hidden Confounders
Michaël: You mentioned Ethan Caballero, and one thing you mentioned a lot when I was in Montreal was training on all of YouTube. So if your distribution is all of YouTube, can you get some causal model of the world?
David: I mean, who knows, right? That’s an open question. I think.
Michaël: From the paper risk extrapolation, is-
David: That doesn’t address the argument there. No, I mean there are always hidden confounders-
Michaël: What’s a hidden confounder?
David: A hidden confounder is something that affects the relationship between the variables that you observe and that you don’t observe. There’s always stuff that we don’t observe. You can only observe a tiny, tiny fraction of what’s happening at any given moment. And everything is connected. That’s just physics. So they’re just always hidden confounders.
Michaël: So you’re just saying there are infinitely many, many variables in the world… that it is impossible to build a true casual model of the world?
David: It’s not necessarily the case that you’re going to build the best causal model that you can by just trying to fit your observed data as well as possible. So you should be thinking about these issues of hidden confounders and you should be trying to model that stuff as well.
Towards Increasing Causality Understanding In The Community
Michaël: Do you think people in the Deep Learning community should build more causal models?
David: I think people should try and understand causality to some extent have a basic understanding of causality. By and large people in the research community do say, at this point, that it is potentially a major issue for applying machine learning in practice. Because I think there’s a lot of hype and over enthusiasm for things that won’t really work in practice. And that partially has to do with causality. I think it’s a good angle on robustness problems. You can do some pretty irresponsible and harmful things if you just build models and they look like they’re working and you haven’t thought about the potential causal issues there. ⬆
Michaël: The problem if it works too well then you have an agent that is very capable and capable of manipulating you. But if it doesn’t work very well, then it’s just like you actually have a bad agent, not very capable.
David: We’ve sort of been mixing together understanding causality and being an agent, but those are totally separate things in principles. You can have a good causal model of the world and still just be doing prediction. You don’t have to be an agent. Historically people who have been working on causality and machine learning are working on prediction more than agency. People in reinforcement learning have been thinking about this in the online context where the agent gets to learn from interacting with the environment. And there’s this recent trend towards offline RL where instead you learn from data that has already been collected and that obviously has the same problems of supervised learning where it’s just more clear how causality and causal confusion can be an issue.
David: But historically, people have been focused on the online case and then you just figure, well, okay, agent’s just going to be able to take interventions and test its actions are basically interventions. And so it can actually learn the causal impact of its actions that way. So there’s no real issue of causality there. And I guess I’m not sure to what extent that is correct either.
Causal Confusion In A POMDP
David: Because we have an example, another one of my papers from towards the end of my PhD, Hidden Incentives for Auto-Induced Distributional Shift. One of the results there was, we were doing online RL using Q learning in a POMDP. And if you set it up you can get causal confusion still.
Michaël: So what’s causal confusion?
David: Causal confusion. I just mean the model basically has the wrong causal model of the world or gets some stuff backwards, thinks X causes Y when Y causes X or Z causes both X and Y, these sorts of mistakes.
Michaël: What kind of POMDP? Was it the thing with the prisoner’s dilemma?
David: It’s a POMDP that’s based on the prisoner’s dilemma. You can think of cooperate or defect as invest or consume. And so basically if you invest now, then you do better on the next time step. But if you consume now, you get more reward now. The point of this was just to see if agents are myopic or not. If they consume everything immediately, then they’re myopic and if they invest in their future then they’re non-myopic. This seems potentially a good way to test for power seeking and instrumental goals because instrumental goals are things that you do now so that in the future you can get more reward. The delayed gratification is an important part of that.
Michaël: Are agents today are able to plan and invest or are they more myopic or it depends on different cases?
David: That was the simplest environment we could come up with to test this. It’s really easy if you build a system that is supposed to be non-myopic, then it will be non-myopic generally. But the question was if you build a system that’s supposed to be myopic. If you set the discount parameter gamma to zero so that it should only care about the present reward, does it still end up behaving as if it cares about the future reward?
One of these speculative concerns is that even if you aren’t trying to build an agent, there’s some convergent pressure towards things becoming agents. You might be thinking that you’re just building a prediction model, like a supervised learning model that doesn’t think about how its actions affect the world, doesn’t care about it, but you’ll be surprised one day, you’ll wake up and the next day it’s a superintelligent agent that’s taking over the world and you’ll be like, “Darn, I knew we shouldn’t have trusted GPT-5.”
Michaël: What are those kind of pressures? Just users interacting with it?
David: It’s super speculative to some extent. People talk about decision theories and stuff like this, and I think I’m going to kind of butcher this, but I guess I want to say there’s this view from people like Eliezer and MIRI and LessWrong, you can’t build something that is an AGI with human level intelligence, unless it is an agent.
And so if you wake up one day and found that you have built AGI, it means that however you built it, you produced an agent. So even if you were just doing prediction, somehow that thing turned into an agent. And then the question is how could that happen? Why could that happen? And it gets pretty weird. But I guess you can say if you really believe that agency is the best way to do stuff, is to be an agent, then maybe the best way to solve any task is to be an agent. Even if it looks like it’s just a prediction task.
Agents, Decision Theory
Defining Agency
Michaël: What is being an agent?
David: I feel like I’m really going to butcher this right now. It means a bunch of different things to different people in this context. It’s the term of art on the online existential-safety community, LessWrong, or Alignment Forum community would be consequentialist, which is a term borrowed from philosophy. But basically it means that, alluded to earlier, you’re thinking about how your actions will affect the world and planning for the future, but it’s even a little bit more than that because in the limit it means you have… I don’t know, are as rational as possible. And maybe that includes doing things like acausal trade and these weird decision theories that say you shouldn’t just think about the causal effects of your actions. You should act as if you’re deciding for every system, agent, algorithm, whatever in your reference class. ⬆
Acausal Trade And Cooperating With Your Past Self
Michaël: This is something I’ve never understood – acausal trade. If you have a good two minutes explanation, that would be awesome.
David: I don’t think I’m the right person, but again let’s just go for it. I can explain it with reference to my research and then we can say how it might generalize. In my case, it’s this prisoner’s dilemma environment. If you reason as if you are deciding for every copy of yourself, including the copy on the last time step. In this POMDP inspired by the prisoner’s dilemma in this work that we were talking about, if you think about yourself as deciding for all the agents in your reference class, that might include the version of you on the previous time step. And then you might say, “Well if I cooperate then it probably means I cooperated on the last time step, which means I’ll probably get to pay off of cooperate-cooperate and if I defect I probably just defect it. So I’ll get like defect-defect and cooperate-cooperate is better than defect-defect so maybe I should cooperate.”
David: Whereas normally the more obvious way of thinking about this so is to say, “Look, whatever I did is already done so I’m just going to defect because that helps me right now.” And these roughly map onto the first one, Evidential Decision Theory and the second one, Causal Decision Theory and the acausal trade falls out of these decision theories, like Functional Decision Theory which sometimes act more like EDT and sometimes act more like CDT. And you can now say “Okay, so that’s what I would do in this case. And then you can say, well what about agents in other parts of the multiverse who are like me? And maybe if I want to cooperate with those agents that exist in some other universe..” And that’s the part that I think I’m not going to do a good job of explaining. So let’s just say by analogy cooperating with your past self is cooperating with a copy of yourself in another universe or something.
Michaël: So why would you cooperate with your past self?
David: It’s not really cooperating with your past self here, it’s cooperating with your past and your future self in a way. Because your past self isn’t the one who gets the benefits of you cooperating, it’s your future self who gets the benefits of you cooperating or investing.
Michaël: So it’s kind of committing to a strategy of always investing or cooperating so that all the copies of yourself do the right thing.
David: But the way that you put it makes it sound like I’m going to commit to doing this from now on so that in the future I can benefit from it.
Michaël: Are the agents trying to maximize reward over time? You were talking about some gamma that was set to zero is the kind of gamma you have in RL where it can be 0.9 or one and the more close to one, the more to it’s able to think about the long-term. And so in the case of something cooperating with this past self or future yourself as gamma closer to one or non-zero?
David: All the experiments in this paper we had gamma zero.
Michaël: And even with gamma zero it tried to cooperate?
David: Well it did “cooperate,” right? There’s two actions and it took the one that corresponds to cooperating in the prisoner’s dilemma in some settings.
Michaël: Because it maximizes reward for one step or…
David: It’s kind of complicated to get into that because the question of what counts as maximizing reward kind of depends on your decision theory and stuff like this. At any point if you defect you’ll get more reward than if you cooperate from a causal point of view. But cooperate-cooperate is better than defect-defect and for some algorithms you end up seeing mostly defect-defect or cooperate-cooperate payoffs and cooperating ends up being really good evidence that you cooperated on the last time step. Good evidence that you’ll get the cooperate-cooperate payoffs and vice versa for defect. So it kind of depends on if you’re doing causal or evidential reasoning.
Michaël: I won’t go deep into all the decision theories because I haven’t read all of them. Do you remember why were we talking about agents? ⬆
Causality In Language Models
Causality Could Be Downstream From Next Token Prediction
David: We were talking earlier about this argument about the Book of Why and I said there’s this argument from my paper on risk extrapolation saying, “If you train your foundation model offline, it’s probably going to be causally confused.” And I think that’s a good argument, but I don’t think it’s conclusive and I think there’s good counterarguments. The one that I focus on is basically, “If your language model reads the Book of Why or another text on causality and is able to do a good job of predicting that text, then it seems like it must have some understanding of the content of the text. So it must understand causality in some sense.”
David: This goes back to this question we were talking about, “is the model going to build a good model of the world that is accurate?”. In this case this is the argument for why just training on text means that you need to learn a lot of things about how the world actually works because a lot of the text that you’re going to predict… the best way to predict that is to have a good model of the world. Then that’s an argument for saying actually it is going to understand causality. I think it’s pretty unclear how this all shakes out and it’s really interesting to look at it. We have another project that’s about that saying… ⬆
Models Might Be Leveraging Causal Understanding Only When Prompted The Right Way
David: There’s this question of… if it understands it, is it then going to actually use it to reason about things? It could have this understanding of causality or physics or what the actual world that we live in looks like and have that in a little box over here that it only ever uses that box when it’s in a context that is very specifically about that. So it only ever taps into the fact that the earth is a third planet from the sun when people are asking you questions about that thing, about the solar system and otherwise it’s not paying any attention to that part of its model or whatever.
David: But you might say, actually, it should be possible for the model to recognize which types of sources provide good, very general information that is about things like how the world works and to try and use that even outside of those contexts. That’s the question here is if you assume that the model is going to learn these things, is it actually going to reason with them across the board or is it only going to tap into them in very particular contexts? Is it going to reason constantly, even when it’s not looking at text about causality or is it only going to tap into that understanding when it’s predicting text from the Book of Why?
Michaël: The question is, will the model only understand causality when trying to fit some causal text?
David: Not will it only understand it, but will it only leverage that understanding or be using that part of its model.
Michaël: If we don’t prompt it with the Book of Why it will not be able to use the part of this model that is about causality.
David: Or, I would put it more, it will choose not to. But its ability versus motivation is something that we don’t really know how to disentangle rigorously in these models. Even if the models don’t do the causally appropriate stuff by themselves, it doesn’t mean that this is a fundamental barrier. In some sense it is. I think I tend to agree with a lot of the criticisms that people make of just scaling up Deep Learning and the limitations of it. And I’m like, “Yeah, those are limitations, but they don’t matter that much because we can get around them.” So if your model can do causely correct reasoning when prompted in the right way, then you just have to figure out how to get it to do that reasoning at the right time. I think that’s not that hard of a problem a lot of time, probably. ⬆
Recursive Self Improvement, Bitter Lesson And Alignment
Recursive Self Improvement By Cobbling Together Different Pieces
David: Similarly things about the model not having long-term memory or just all the other limitations that people have. Systematic generalization, it can’t robustly learn logical stuff and do deduction. We have existing frameworks and algorithms for doing deduction and doing reasoning and I think all the model needs to do is learn how to interact with those things or we can learn another system that puts all these pieces together.
David: That’s what I think is actually the most likely path to AGI, it’s not just scaling but somehow cobbling together all these different pieces in the right way. And that might be done using machine learning. That might not be something that people do. That might be something that in the end we just do a big search over all the different ways of combining all the ideas that we’ve come up with in AI and the search =stumbles across the right thing and then you might very suddenly have something that is actually has these broad capabilities.
Michaël: So we do some Neural Architecture Search but with different model that could interface with each other and at the end we get something that has one causal model, one language model and they all piece together to, I don’t know, use their superpowers or something together.
David: That’s roughly the right picture. Neural Architecture Search is a pretty specific technique, but it’s that thing. Meta-Learning, Neural Architecture Search, Automatic Hyperparameter Tuning are examples of things that are like this, but I think they’re all fairly narrow and weak compared to the things that machine learning researchers and engineers do. So if we can automate that even in a way that maybe isn’t as good as people but is reasonably good, at least is better than just random search and then we can do it faster than people can, then that could lead to something that looks like recursive self improvement but probably still not overnight. ⬆
Meta-learning In Foundational Models
Michaël: Is there any evidence for that? Because I feel like the trend in the past few years have been to just have Foundation Models that are larger, that can use different modality and not gluing together different models or searching over the space of how to interface two different models. Any paper or research in that direction?
David: One thing I would say is a lot of this stuff planning is being done with foundation models these days and it’s working quite well, but we’re explicitly inducing that planning behavior somehow. We’re building an architecture or we’re running the model in a way that looks like planning. We’re not just doing it purely end to end, we’re prompting it to make plans or we’re building architectures that involve planning at the architectural level, or we’re doing things like Monte Carlo research or some other test time algorithm that combines multiple predictions from the model in some clever way.
David: What I’m saying I think does go against current trends. From that point of view, there’s maybe some validity to critics who are like, “Oh, people are focusing too much on scaling”. From the point of view of just making AGI as fast as possible, which is not really what I think the goal should be, obviously. You do also see people using foundation models to do things like Meta-Learning, basically. Training a foundation model to take as input a dataset and output a predictor on that dataset.
Michaël: Wait, it just outputs a model?
David: I’m not sure if it outputs a model or if you take a data set and a new input that you want to make a prediction on and then you produce the output for that particular input.
Michaël: So it’s kind of simulating another model.
David: Basically trying to do all of the learning in a single forward pass, which is also an idea that Richard Turner, one of my colleagues at CBL has been doing for years, but now with foundation models but using neural processes as the line of work. So I think there is an ongoing effort to automate learning, research and engineering and it still hasn’t paid off in a big way yet, but I think it’s bound to at some point because everything’s going to pay off at some point because AGI… ⬆
The Bitter Lesson Does Not Address Alignment
Michaël: Are you on the side of the Bitter Lesson where any engineering trick or small formula will end up irrelevant with scale?
David: I don’t think that’s quite what the lesson says.
Michaël: It’s more about Meta-Learning than actually just scaling. This is more in RL, the methods that scale with compute or data or the meta-learning approaches are better than just engineered ones, right?
David: I don’t feel like the Bitter Lesson is being about meta-learning at all, but it’s just about learning. Learning, planning, search, two of those three, I think it’s learning and search that are the ones that he focuses on as being the things that scale. And I think this is true basically, and it’s one of the reasons in my mind to be worried about existential safety is because whether or not just scaling up Deep Learning leads to AGI, there are definitely large returns to just scaling up compute and data, but that doesn’t really deal with the alignment problem per se.
David: It might end up in some way. This is an argument that I’m trying to flesh out right now and I think it might just be kind of wrong or misguided in some sense, but intuitively it seems right to me. And the argument is as you get more and more complex systems, it becomes harder and harder to understand and control them just because they’re complicated and there are more different things that they could do. So you need to provide more bits to disambiguate between all the many things that they could do to get the things that you actually want them to do. And they’re just more complex. So it takes more labor to understand them if you want to really understand all the details.
Michaël: So the more complex the model is, the more work a human needs to do to actually determine if the model is aligned or not. If there’s one aligned model among two to the power of ten, you need more time or more feedback or more interpretability tools.
David: That’s the claim, which I think empirically it looks like this is just maybe wrong, it’s kind of unclear because people have found that as you scale up models, they may get easier to align in some sense. It seems like they understand better what we’re asking for and stuff like this. So I think that’s the part that I’m currently stuck on is how to deal with, because I think right now a lot of people won’t find this convincing, even though my intuition still says no, there’s something to this argument.
David: Another way of putting it I think, which also will certainly not land for everybody, but is in terms of this distinction between descriptive and normative information or facts. I think, the Bitter Lesson applies to descriptive things. Basically facts about how the world is, but it doesn’t apply to normative things, which is what is good or what we want. So learning and search and scaling don’t really address that part of how do we get all the information in the system about what we want. ⬆
We Need Strong Guarantees Before Running A System That Poses An Existential Threat
Michaël: So scale is not all you need when you need to do alignment?
David: Yeah. Another part of the argument is maybe it is, but we won’t really know. You can just hope that something works and just go for it. But I think what we should be aiming for is actually understanding and not taking that kind of gamble. There’s this distinction between a system being existentially safe and us knowing that that’s the case and having justified confidence in it. So not just thinking it’s the case or having convinced ourselves, but actually having a sound reason for believing that.
Michaël: So even if it would be existentially safe in 90% of the cases, we would need some kind of strong reason to believe that and be sure before running it. And even if there’s a high chance of it being safe, we wouldn’t have the tools to be sure it’s safe.
David: If you run this system, it’s either going to take over the world and kill everyone or not, and that’s pretty much deterministic, but you don’t know which of those outcomes is going to occur. You might say, “I have essentially no reason to believe that that’s going to happen except for some general concern and paranoia about systems that seem really smart being potentially dangerous.” From the point of view of existential safety, when we’re talking about potentially wiping out all of humanity, it seems like the bar should be really high in terms of the amount of confidence you would like us to have before we turn on a system that we have some reason to believe could destroy humanity.
Michaël: How high?
David: I don’t know.
Michaël: How many nines?
David: That’s a good question. I guess it depends on how longtermist you are, but I think we can say definitely a lot because the amount of harm that we’re talking about is at least killing everyone alive right now. And then if you value future people to some extent, then that starts to grow more. ⬆
Michaël: We’ve been bouncing around this notion of alignment or getting models to do what we want. Do you have any more precise definition? Because I’ve tried to talk to Mila people about it and it seemed like even if you were there for a few years, people didn’t know exactly what alignment was. ⬆
How Mila Changed In The Past Ten Years
David: I mean I was there for almost ten years and the lab grew a ton from something like fifty people, something like a thousand over the course of time when I was there.
Michaël: How was the difference between fifty to a thousand?
David: I mean, it is totally different. And then the last couple years there was pandemic, so I was already starting to lose touch I would say. Also when we moved to our new building, I think people weren’t coming into the lab as much and it changed the culture in various ways.
Michaël: How was the beginning when you were only fifty people?
David: I mean, it was cool. I don’t know. Can you give me a more specific question please?
Michaël: Would you cooperate or collaborate with mostly everyone and know what everyone was doing?
David: Not per se, but yeah, definitely more like that. I guess at the beginning I would say it was much more Yoshua’s group and everyone who to leading the vision for the group to a large extent. And everyone was doing Deep Learning and Deep Learning was this small niche fringe thing. So it was still… you could be up to date on all of the Deep Learning papers, which is just laughable now. ⬆
How David Decided To Study AI In 2012
Michaël: I think 10 years ago there was a story of Ian Goodfellow reading all the Deep Learning papers on Arxiv. This was 2012. So it was after AlexNet?
David: AlexNet and Ilya Sutskever’s Text Generating RNN were the things that got me into the field. I was watching these Geoff Hinton Coursera lectures and he showed those things and this was the first thing that I saw that looked like it had the potential to scale to AGI in some sense. And so I was already basically convinced when I saw those that, that this was going to be a big deal and I wanted to get involved. So then I applied in 2012 for grad school and started in 2013.
Michaël: But you needed to be at least in the field of AI to see those signals, right? Because most people came maybe in 2015 or 2016.
David: I mean wasn’t in the field of AI.
Michaël: So as someone outside, how did you saw it as very important?
David: I studied math and knew was trying to get a lot of different perspectives on basically intelligence and society and social organization and these sorts of things during my studies before that. And I was always interested in AI, but when I started college, I didn’t even know it was a field of research. I was definitely learning pretty slowly what it was and what was out there. I think I heard about machine learning when I was in my second or third year of college. And then I went and looked at maybe something, I don’t know if it was Andrew Yang’s Machine Learning course, but it was something that resembled that. There you see linear regression, logistic regression kernel methods, nearest neighbors. I was just like, “Well, this is crap. This is just not going to scale to AI maybe in over a hundred years if you just scale these things up with orders and orders of magnitude more compute. But it just seemed clearly not anything you should be calling AI.” And then I also heard about Deep Learning and Artificial Neural Networks in between my second and third year when I was doing research in computational neuroscience. Somebody drew a neural network and was like, “you train this with gradient descent based on the reward signal.” And I was like, “wow, that is so cool. This looks really, this is like the this is the right level of abstraction for people to try to understand and solve intelligence. Because the other stuff there was modeling individual neurons at the level of physics and stuff like this. And it’s just like this is never going to go anywhere anytime soon.”
Michaël: So just the abstraction was good and you had some basic understanding of linear regression. You saw the AlexNet paper and you were like, “Oh, this thing actually scales with more layers.”
David: When I saw that, I was really excited by it, but they said this doesn’t work and it’s sbeen disproven as an approach and I was sad. And so then I was like, “Oh there’s this course on neural networks on Coursera” and there were like then different courses that I had followed or whatever, but hadn’t really watched anything. And I just decided to binge watch that one on a whim. And I was like, “holy shit, they lied to me. It does work.”
David: So it was both, I had this intuition already that this was a promising approach to solving AI and then just seeing the text generation was artificial creativity of some sort. And then seeing that it could deal with what’s clearly a complex thing, which is vision and was just almost out of the box doing just a huge step improvement. You were seeing these other methods leveling off and then it was just like shoom! I think Geoff Hinton made a bunch of good arguments as well in his lectures about the scalability of the methods and about things like the curse of dimensionality. So from first principles, why you need to be doing Deep Learning or something like it somewhere in your AI system. ⬆
How David Got Into Existential Safety
Michaël: And to fast forward a little bit, you go to Mila, you spend 10 years there and nobody knows about alignment.
David: I mean it is a little bit puzzling to me, I guess. In the early days I was talking to everybody who I could to some extent about this. For the first couple years I was expecting that I would get to Mila and everyone would be like, “oh yeah, we know about that stuff and you don’t have to worry about it because X, Y, Z.” Have really good reasons. And turns out people didn’t know about it. So then, I started trying to talk to people about it a lot, but I was like an outsider, hadn’t really done programming before and stuff when I got there. And I really felt like a little bit intimidated and just impressed by the people there. And I didn’t really have much of a cohort when I started as well. There were two other guys starting at the same time as me, but they were doing industrial masters. So, I think it took me a little while to gain the confidence to just be really outspoken about this. But, by the end of my masters in beginning my PhD, I was like, “yeah, this is what I want to do and I’m going to try and talk to people about it and influence people.”
Michaël: When did you learn about alignment?
David: I’m not sure. Something I wanted to say earlier is, we’re talking about alignment, but I want to distinguish it from existential safety. I think alignment is a technical research area that may or may not be helpful for AI exponential safety. And it’s about, in my mind, getting the systems to have the right intention or understand what it is that you want them to do. Existential safety is the thing that I think I mostly am focused on and like to talk about in this context. I think they get interchanged a lot.
David: I learned about it before I started grad school, but I’m not sure how long before. My perspective before realizing that AGI might happen in my lifetime was basically… Maybe this will be a concern when AGI actually happens in the distant future. But, in the meanwhile everything is going to get really weird and probably really fucked up because we’re just going to have better and better automated systems of monitoring and controlling people basically. And those are going to be deployed probably in the interest of power or in, maybe something more a best case, they’re going to just fall victim to bad social dynamics. It’s still just not really optimizing for what we care about. ⬆
Harm From Technology Development Might Get Worse With AI
Michaël: Do you still agree with that view, a slow takeoff scenario?
David: I don’t know about this slow takeoff or hard takeoff thing. They’re both quite plausible. But even if we do not have an AGI, we would still have a lot of major issues from advancing narrow AI systems. That still seems right to me. I mean I think it’s hard to know.
Michaël: In our trajectory, where we’re at right now, do you think we will see harms from narrow systems for multiple years before we get to AGI or will we only get to those very negative harms when we’re very close to AGI? That’s the question. Is it a period of three or five years of society going crazy and AI systems being unaligned causing harm or is it just before crunch time?
David: I think things are already going crazy and have been for a while. So, I think the way that the world works and is set up, it doesn’t make sense. It’s nuts. And you look at just the way that money works and there’s just all of this money being created via financial instruments that is pretty detached from the fundamentals of the economy. And I think you look at the way that our collective epistemics work and a lot of people are just very badly misinformed about a lot of things and there are a lot of structural incentives to provide people some combination of the information that grabs their attention the most and also is helpful to people with a lot of power. That’s kind of how the information economy works for the most part.
Michaël: So you’re saying basically, it’s not very balanced in terms of how the money is created, how it’s spread over economy and information is also fed to people’s brains in a way that hacks their reward system and controls them or manipulates them and maybe AI will exacerbate both power imbalance or financial imbalance?
David: It will and it already has been, is the other thing. It’s not just AI, it’s the development of technology that is useful for understanding humans and predicting them, in general. So marketing, as a thing, is kind of a recent invention and it’s based to some extent, I think, on us having a better understanding of how to manipulate people and then having the technology to do that at scale for cheap. ⬆
Coordination
How We Could Lose Control And Lack Coordination
Michaël: Is your research focused on solving those short-term, current problems or more existential safety? So to be clear, existential safety is when we run a system, when we press play or something, the system takes over the world.
David: No, existential safety is much broader than that. So, I totally reject this dichotomy between the existential safety of the fast takeoff, the thing takes over the world immediately, and this slow takeoff of things get less and less aligned with human values and we’re more and more manipulated and optimizing at a societal level for the wrong things. Just increasing GDP even though we’re destroying the planet. Just kind of dumb.
Michaël: Because one causes the other. One can make the other much more likely. If humanity is going in the wrong direction then…
David: That’s part of it, is that that can lead to a situation where, ultimately, we lose control in the sense that no set of human beings, even if they were in some sense perfectly coordinated. It could change the course of the future. So that’s one sense of loss of control, that’s in the strongest sense, where even if everyone all got together and was like, “let’s just stop using technology, destroy the computers, unplug the internet, everything,” it would be too late. And the AI has its own factories or ability to persist in the physical world, even given our best attempts to destroy it.
David: That’s the strongest version. But there’s also a version of out of control AI, which is just out of control, I don’t know, climate change. Where it’s like, in some sense we could all coordinate and stop this but we’re not doing it. We probably aren’t going to do it to the extent that we should. And there’s no one person or small group of people who have the power to do this. It would take a huge amount of coordination that we don’t really have the tools. Okay, I probably have to walk this back because I don’t know enough about it. And to some extent it probably is something where it’s just, I’m not sure we need fundamentally new coordination tools to solve climate change. We might just need a lot more moral resolve on the part of people with power. But I think there are definitely a lot of gnarly coordination problems that are contributing in a massive way to climate change. ⬆
Low-Hanging Fruits In Coordination
Michaël: Is there any way to solve those coordination problems? Isn’t it basically intractable compared to other technical problems in AI?
David: No, I don’t think so. We know that there are voting systems that seem a lot better than the ones that we use in the United States anyways and I think are still really popular. People call it first-past-the-post, which is a terrible name because it’s actually whoever gets the plurality wins. So, the post isn’t even at some fixed point, but just the majority rule. Actually, plurality rule. Majority rule is also a bad name. Things like approval voting seem to just be basically robustly better for most contexts. And of course there are these impossibility results that say, no voting system is perfect, but you talk to people who actually study this stuff and it seems like pretty much everyone likes approval voting and would just sign off on using it everywhere that we’re using, whatever you should call this thing, majority rule, first pass post, plurality rule, let’s call it the X.
David: That’s what it is. So that’s just one simple example. I think there’s a lot of low-hanging fruit for doing more coordination, both at just the level of people talking to each other more and trying to understand each other and be more cooperative. So, let’s say internationally it seems like there’s surprisingly little in the way of connections between China and the West. I think you have a massive imbalance where a lot of people in China come to the West to study and to have a career and a lot of people there learn to speak English and you don’t really see the opposite. So there’s very little, I would say understanding, or even ability to understand what’s going on in China and what the people are like there, what the system is like there from people in the West.
Michaël: So Americans are not trying to understand China and it is kind of a one-sided relationship?
David: To a large extent. And why is that happening? I guess it’s for historic and power reasons where English is this lingua franca, that it just makes sense for people to learn. Whereas I think it would make sense from a lot of point of view, including individuals and maybe the US national interest for more people to learn Chinese. But it’s difficult and there’s not this obvious pressing need because stuff gets translated into English. That’s just one example. Then, I think we have coordination mechanisms that could be scaled up. Basically assurance contracts, which are things like Kickstarter; where you say, if I will agree to do this, let’s say I will agree to boycott this company for their unethical practices, assuming enough other people agree to do it. And until we have enough people we just won’t do the boycott.
David: That’s an assurance contract. So if you can monitor and enforce those contracts, then you can solve a lot of collective action problems because there’s essentially no cost to signing up for one of these, especially if you can do it in a non-public way. So you can’t be punished in advance for taking that political stance. And then once you have enough people who are on board with taking that action, then you actually take it. That’s why you need the monitoring enforcement part to make sure that people actually do follow through on their commitments. But, I think there’s tons of low-hanging fruit in that area.
Michaël: So some kind of centralized system where people can just pre-commit to some action if millions of people are boycotting some company. ⬆
Coordination Does Not Solve Everything, We Might Not Want Hiveminds
David: It doesn’t have to be centralized, could be decentralized. This is something that I’ve been thinking about for a long time and hesitant to talk about. Because I think it also could pose existential risks. Because I think at the end of the day it’s not just a problem of coordination, it’s also coordinating in the right way or for the right things for something. So if you think about an hive, it is very well coordinated, but we probably don’t want to live in a future where we’re all basically part of some hive mind. I mean, I don’t know. Hard to say definitive things about that, but I’m sure a lot of people right now would look on that future with a lot of suspicion or disgust or displeasure. We should try and avoid a situation where we just end up in that kind of future without realizing it or unintentionally or something. I think better coordination without thoughtfulness about how it’s working could potentially lead to that.
Michaël: Are you basically saying that we need to do enough coordination to not build unsafe AGI, but not too much because otherwise we’ll end up being just one mind and then some people might prefer to be individuals and not one giga brain?
David: I think the second possible failure mode is really speculative and weird and I don’t know how to think about it. I just think it’s something that we should at least be aware of. But I think we definitely need to do enough coordination to not build AI that could take over the world and kill everybody if that looks like it’s a real possibility. Which in my opinion, yes, that’s something we should figure out and worry about. ⬆
Advanced AI Systems Should Be Able To Solve Coordination Problems Amongst Themselves
Michaël: I think some people in the open source community just have this different scenario from people in the safety community. Whereas people in the safety community will think of one agent being vastly smarter than other agents and this agent might transform the earth into some giant computer. Whereas people in the open source community might think that we might get different agents, multiple scenarios where if you open source everything then maybe we get different levels and different balance each other out. Do you believe we are going to get a bunch of different AIs balancing each other or one agent smarter than the others?
David: I don’t have a super strong intuition about this. I think the agents balancing each other out thing is not necessarily better from an existential safety point of view. There are also these arguments that I find fairly compelling, although not decisive saying if you have highly advanced AI systems, they should be able to solve coordination problems amongst themselves. So even if you start out with multiple agents, they might form a hivemind basically because they can solve these coordination problems that humans haven’t been able to solve as effectively. So one reason why it might be easier for AI systems to coordinate is because they might be able to just look at each other’s source code and you know, you have to ensure that you’re actually looking at the real code and they aren’t showing you fake code and stuff like this. But it seems plausible that we could end up in a situation where they can all see each other’s source code and then you can basically say, is this somebody who is going to cooperate with me if I cooperate with them?
Michaël: So one scenario I have in my mind is just if we deploy a bunch of those Action Transformers from Adept that can do requests on the web, and I know they kind of understand that the other person they’re interacting with is an AI as well. And so you can have those millions of agents running into this at the same time. Is this basically what you’re saying? You get those things that identify each other through requests and communicate to each other.
David: I’m not sure I’ve understood, but it sounds like a more specific version of what I’m saying basically. ⬆
David’s Approach To Alignment Research
The Difference Between Makers And Breakes, Or Why David Does Not Have An Agenda
Michaël: I think a lot of the people that asked me questions on Twitter were kind of more interested in your research agenda for solving existential safety and not other takes you might have. One thing that’s kind of very specific about yourself is that you don’t have a specific agenda, but you have a bunch of PhD students doing a bunch of different things. And that’s one thing. The other thing is you often say that you’re more of a breaker than a maker. You prefer to break systems than build systems. Maybe I’m misrepresenting your view, can you elaborate on this?
David: Totally. I’ve been thinking about this stuff for a long time, more than 10 years now, and it’s always seemed like a really hard problem and I don’t see any super promising paths towards solving it. I think there are these Hail Mary things where it’s like, “oh yeah, maybe this will work,” and it makes sense to try, probably. But for all of those, none of them I think are anywhere close to addressing this justified confidence issue that we talked about. The ones that look like they might have a chance of working in the near term are mostly just, “let’s just cross our fingers and just hope that the thing is aligned. We’ll train it to do what we want and hopefully it does.” So I’m not very optimistic about those approaches.
David: I think, like I said, maybe it works, but I’m more interested in providing strong evidence or reasons and arguments for why these approaches aren’t going to work. So my intuition is like, it’s probably not going to work. Probably things are going to go wrong for some reason or another. Seems like there are a lot of things that’ll have to go right in order for this to work out. So that’s the maker breaker thing that you’re talking about. And this is a recent way that I’ve thought about framing my research and what I’m doing. So I’m in the process of maybe trying to develop more of an agenda. I’ve historically been a little bit, I don’t know, anti-agenda or skeptical of agendas or the way that people talk about it right now in the rationalist community or something like this. ⬆
Deference In The Existential Safety Community
David: The online non-academic existential safety community just seems kind of weird. Playing into some dysfunctional dynamics of people who don’t really understand stuff well enough. So they defer a bunch to other people. And the people who they defer to are, it seems like a lot of it is social and trendy and very caught up in whatever’s going on in the bay. And of course then there’s also influence from tons of billionaire money. I mean maybe not anymore in the same way, so I think the epistemic of the community get distorted by all these things. There are some things where it ends up looking a little bit like these social science fields where it’s more about cult personality and who is hot and who knows who and who you’re trying to interpret, “oh, did Paul mean this by this or did he mean that?”
David: And you have these debates that aren’t really about the object level question. I can go on and on about the gripes that I have with these this community. And to some extent I’m kind of picking on them because I guess it’s just some recent interactions I’ve had have updated me towards feeling like there’s more dysfunction than I would have thought. And I’m not that well plugged in, so I can’t say how much I’m being unfair or generalizing too much or something. But this is just my impression from some recent interactions.
Michaël: Recent events or just personal interactions?
David: I think it’s personal interactions, it’s events, it’s reading things online, a lot of it is second or third hand, it’s not even me personally having bad interaction with somebody, it’s other people complaining to me about their interactions. So that’s why I have to caveat it and say maybe some of this is pretty off base and I don’t want to tar the whole community. But what were we talking about? Agendas?
Michaël: Yeah. ⬆
How David Approaches Research In His Lab
David: I think the way that people talk about agendas and everyone asking me about agendas feels like a little bit weird. Because I think people often have some agenda. But I think agenda is a very grandiose term to me. It’s oftentimes, I think people who are at my level of seniority or even more senior in machine learning would say, “oh, I’m pursuing a few research directions.”
David: And they wouldn’t say, “I have this big agenda.” And so I think my philosophy or mentality, I should say, when I set up this group and started hiring people was like, let’s get talented people. Let’s get people who understand and care about the problem. Let’s get people who understand machine learning. Let’s put them all together and just see what happens and try and find people who I want to work with, who I think are going to be nice people to have in the group who have good personalities, pro-social, who seem to really understand and care and all that stuff.
David: It’s not this top down I have the solution for alignment and I just need an army of people to implement it. I’ve described it as something of a laissez-faire approach to running the lab. To some extent I have that luxury because of getting funding from the existential safety funders. So they’re not placing a lot of demands on me in terms of the outputs of the research, which is, I think, pretty unusual. I’m pretty lucky to have that compared to a lot of academics. I think a lot of times in academia you have a lot more pressure to produce specific things because that’s what the funding is asking for.
Michaël: So you have both the, let’s say, flexibility of choosing what research you want to do, but at the same time you’re trying to go for the rigor of the original academic discipline? ⬆
Testing Intuitions By Formalizing Them As Research Problems To Be Investigated
David: One thing, if you look at the people arguing about this stuff in the bay and online and in person and this non-academic existential safety community, which includes some people who are in academia as well, but you know who I’m talking about. Anyways, if you look at what’s happening there, people just have very different intuitions and they argue about them occasionally and then they go away with their different intuitions and then they go off and take actions based on their intuitions. And it kind of struck me at some point that “hey, maybe we can actually do research on these problems and try and understand.” So we talked earlier about this example of the AI in a box and does it learn to reverse engineer the outside world. So that’s something where people have really different intuitions and we can just approach that as a research problem.
David: And so let’s start doing that kind of research to actually see what the situation we’re in is and trying to understand what the safety profile is of these different systems and different ways of building systems and different approaches that I think historically the existential safety community, people back in the day at MIRI were very down on any approach that looked like at all hacky or heuristic. They’re just like, “oh yeah, that’s not going to work because superintelligence.” And I think a lot of those are actually really promising to explore and we should figure out how far we can take them.
Michaël: Just to give some pushback on the people doing research on their intuitions and everyone in the bay having similar ways of doing research. I think when we talk about MIRI, this is for people who are listening to this or watching this, who don’t know about this, it’s the Machine Intelligence Research Institute created 20 years ago-ish and I think it produces less research as of right now. And other people who were there now work at Redwood Research that is doing more empirical ML work that is focused on aligning the actual models we have right now instead of researching decision theories. Right now, I think the state is much better than it was maybe 10 years ago.
David: I don’t know. I think you have to agree with their intuitions to some extent maybe to believe that the research they’re doing makes sense. Because if you really have the intuition that this stuff just isn’t going to work because it’s not addressing the core problems, then you’d say, “well this is just a distraction and this is harmful.” And I think it’s plausible that that’s the case. Alignment might just be really hard and all of this stuff that people are doing is just not going to cut it. All it’s going to do is create the illusion of alignment at best.
Michaël: So you’re saying if you’re not interacting with the entire research committee as a whole, you may be in a situation where you end up doing the wrong things because you don’t have enough peer review, people looking at the problem? ⬆
Getting Evidence That Specific Paths Like Reward Modeling Are Going To Work
David: No, I’m just saying it would be good to know if these prosaic, pragmatic AI alignment things are going to work or not and to try and get evidence for. If you think they’re not going to work, which again I suspect that they won’t for AGI or superintelligent systems, try and get good evidence for that being the case. And that’s part of what I’d like to do.
Michaël: You’re trying to see if prosaic alignment or aligning current models will work?
David: Let’s take reward modeling as a concrete example. Is reward modeling going to work? Is it going to get systems that actually have the right intentions, the right motivations? Is it going to give you that? And I think it’s not.
Michaël: Can you explain reward modeling for people who are not into the field?
David: Reward modeling is just the idea of learning a reward function. A model that encodes a reward function and it might refer more specifically to learning from human preferences and things like that where the reward model is not learned from inverse reinforcement learning. So not just learned from observing a human but learn from more explicit human feedback where the human says, “I like this, I don’t like that.” This is better than that for different behaviors.
Michaël: And these kind of reward modeling are already developed or deployed. Does InstructGPT use reward modeling at all?
David: I think so. I think something like this is used by Anthropic and OpenAI, maybe sometimes by Google. I think Google is a little bit more just on the imitation learning side for the fine-tuning of alignment. ⬆
On The Public Perception of AI Alignment And How To Change It
Existential Risk Is Not Taken Seriously Because Of The Availability Heuristic
Michaël: You were also a legend at Mila. So I went to Mila and asked random researchers, “Hey, what do you think of alignment? What do you think of existential risks from AI?.” And people knew you. There was this guy, Breandan, who told me he remembered you. But most of them didn’t care about alignment at all. So as a AI alignment researcher, did you fail your job to spread the message?
David: I don’t think so. I mean, I spread the message. It’s just like, do people want to hear it? And what do they do when they do? It’s been surprising to me how this has happened. There’s been a lot of progress in terms of people understanding existential safety and taking it seriously but I keep thinking the progress will be a little bit faster than it is. I’m not sure what’s up with that but I have a bunch of theories. But I don’t know, I don’t feel like getting into them, necessarily.
Michaël: We have an hour or two, please?
David: I mean the thing is it’s just kind of speculation. Ok, well one thing recently that somebody pointed out to me that maybe I’ve heard this before but it really just struck home. The availability heuristic is this idea that you estimate the probability of something by how readily you can conjure it to mind. And I think the ‘out of control AI takes over the world and kills everybody scenario’, there’s no version of that that I can think of, that doesn’t seem kind of wild and implausible in some of the details. And that doesn’t stop me from taking it seriously. But I can see why a lot of people would, if this is how they are thinking about it. They’re just like, “Well how would that even happen?” And that’s something that people say a lot is like, “So what? It’s going to build nanobots? That sounds like bullshit.” Or, “Robots don’t work so it’s going to have to solve robotics?” And we’re like, “It’s somehow going to do that overnight or something,” which obviously doesn’t have to happen overnight. And what about the future world where we have robots because it’s not like we’re never going to build robots but I digress.
Michaël: We’ve been bouncing around this notion of alignment or getting models to do what we want. Do you have any more precise definition? Because I’ve tried to talk to Mila people about it and it seemed like even if you were there for a few years, people didn’t know exactly what alignment was. ⬆
How Mila Changed In The Past Ten Years
David: I mean I was there for almost ten years and the lab grew a ton from something like fifty people, something like a thousand over the course of time when I was there.
Michaël: How was the difference between fifty to a thousand?
David: I mean, it is totally different. And then the last couple years there was pandemic, so I was already starting to lose touch I would say. Also when we moved to our new building, I think people weren’t coming into the lab as much and it changed the culture in various ways.
Michaël: How was the beginning when you were only fifty people?
David: I mean, it was cool. I don’t know. Can you give me a more specific question please?
Michaël: Would you cooperate or collaborate with mostly everyone and know what everyone was doing?
David: Not per se, but yeah, definitely more like that. I guess at the beginning I would say it was much more Yoshua’s group and everyone who to leading the vision for the group to a large extent. And everyone was doing Deep Learning and Deep Learning was this small niche fringe thing. So it was still… you could be up to date on all of the Deep Learning papers, which is just laughable now. ⬆
Existential Safety Can’t Be Ensured Without High Level Of Coordination
Michaël: People have moved to a more industry level alignment where you use actual machine learning. Some people have asked on Twitter, why did you go into academia, this kind of research? Is there something in academia that you cannot do in industry?
David: It’s a good question. I mean I think I wrote a LessWrong post on that topic. People can look that up if they want to see more of the answer. But just to do a short version of it, one is that I really want to run my group and have students and try and mentor and credential people to grow the field. And another is that I wanted to really maintain strong ties with academia because I think we still have a lot of work to do in terms of educating people in academia about the safety concerns and winning hearts and minds is how I put it. And I hesitate to say educating cause it sounds so pretentious or whatever.
Michaël: Patronizing.
David: Patronizing, yeah I think we can learn a lot from people in Machine Learning as well. Definitely. It’s just really important for these two, or maybe you want to say three communities because there are both the people outside of academia who are working at big companies and then there are the people outside of academia who are doing independent research or doing more conceptual stuff. Stuff that’s closer to the MIRI or maybe aren’t doing anything but just talking about it or something or trying to get into the field. All these people need to talk to each other more and understand each other more. There’s a lack of understanding and appreciation of the perspective of people in machine learning within the existential safety community and vice versa. And I think that’s really important to address, especially because I’m pretty pessimistic about the technical approaches. I don’t think alignment is a problem that can be solved. I think we can do better and better. But to have it be existentially safe, the bar seems really, really high and I don’t think we’re going to get there. So we’re going to need to have some ability to coordinate and say let’s not pursue this development path or let’s not deploy these kinds of systems right now. And for that, I think to have a high level of coordination around that, we’re going to need to have a lot of people on board with that in academia and in the broader world. So I don’t think this is a problem that we can solve just with the die hard people who are already out there convinced of it and trying to do it. ⬆
There Is Not A Lot Of Awareness Of Existential Safety In Academia
Michaël: I think it depends on, I guess the timelines you have. Convincing academia takes a while. If you have 20 or 30 years, maybe you have time to convince a lot of people. And I guess we at a stage where there is enough time for people to read Superintelligence or Human Compatible and all those books that were published in the past 10 years. And either people have still not updated at all on the evidence or either they’ve been living under a rock or it’s not convincing enough. Or maybe we’re wrong. But I’m not sure how much more can we convince them or maybe there’s something about incentives and maybe we need to create a field as something where people can publish or make actual progress before people can move to this field.
David: Incentives have something to do with it for sure. But, I think to some extent people have been living under a rock in the sense that I don’t think most people in machine learning have much awareness of existential safety and alignment. Very few people have seriously engaged with it. I mean you were mentioning how nobody at Mila knows what alignment is, right? I don’t think that’s a Mila thing. I think that’s how it is generally in machine learning. There’s a lot of ignorance.
Michaël: How would you explain or define alignment? I still haven’t heard a nice definition.
David: Oh sure, so there are three different definitions for alignment. One is getting the system to do what you want. The other is getting it to try to do what you want. And then the last one is just existential safety and everything that’s involved in that. And I think the second one is the best definition because the first one is kind of trivial and the second one is handwavy because it has this ‘try’ thing in it. But I think that’s basically what it’s about in my mind. It’s sometimes called Intent Alignment, get the system to be trying to do the right thing.
Michaël: Most people I was talking to at Mila would just say, of course we want models that do what we want because models will do what we want but if we design it properly, it’s not an actual problem. And I think that’s one crux is people are mostly optimistic about the thing doing what we want by default. ⬆
Having People Care About Existential Safety Is Similar To Other Collective Action Problems
David: I mean I would like a car that is exactly like a normal car but makes the environment better instead of worse. So why won’t the car do that?
Michaël: Because people don’t really care about having their car…
David: They do care.
Michaël: Well, some people care.
David: But they don’t care as much as they should because it’s a collective action problem. I’m kind of surprised that this analogy isn’t more apparent to obvious people or doesn’t seem to land that hard a lot of times because this is how I think about it for the most part. And then the other thing is being, that’s the first definition, that’s why I don’t like the first definition is because some people will just be, “like, yeah, we want the system to do.” But even that, I mean not everybody’s doing that. A lot of people in research are like, “no, I’m a scientist. I’m trying to understand intelligence or just make things that are more intelligent,” and the whole, “it does what we want” is more of an engineering point of view, I’d say. All of these coordination problems, I think underlying this is why do we build the cars that pollute instead of trying harder to build cars that don’t pollute? It’s because you can make more money that way, basically. At least in the past, hopefully that’s changing. ⬆
The Problems Are Not From The Economic Systems, Those Are Abstract Concepts
Michaël: I just feel like your point of view is attacking capitalism and not actual coordination problem. I feel like your solution to this problem would be just to change the economic system we have.
David: Okay, we’re back into politics now.
Michaël: Sorry.
David: I don’t think there’s an alternative that’s ready to go. I think there are incremental changes that would be helpful, like the stuff that I talked about, like moving to approval voting or something like that. I think capitalism is usually not a good term for what people are actually talking about. If people talk about global capitalism, and that’s pointing at the same thing that I want to point at as the world does not run well, in some sense. I think capitalism and communism are these things that don’t actually exist, they’re these abstract ideals that have never true.
David: If you talk to hardcore communists, a lot of them will say, “Yeah. All of the existing “communist regimes” that have ever existed sucked, but they weren’t real communism.” If you talk to hardcore free market fundamentalist libertarians, they’d probably tell you the same thing, like, “None of this is capitalism.” There are all these state handouts, and the government is way too involved in everything. I think the reality is that they’re both right. The system that exists is not communism, it’s not capitalism, it’s some thing that incorporates various features of them. It’s just very complicated. There’s a lot to be said about it, but I just want to say, I definitely reject the simple, “Oh, it’s capitalism”. I think it’s just a really bad framing on it. You can redefine capitalism so that it becomes a good framing. Where you say like, “Capitalism is the system that we have and the historical systems that it grew out of.” Then I think you have maybe more of a point, but then I start to lose confidence because I try to study history but I’m not an expert. ⬆
Coordination Is Neglected And There Are Many Low-Hanging Fruits
Michaël: I think everything is about timelines. If you have 20 or 30 years, you might have a shot at fighting Moloch, or changing the system, or building better incentives, or solving coordination problems. If your timelines are five years, then you might want to focus on the technical problems, then, five to 10 or something. I have a hard time thinking that we can do stuff like convince more than 50% of academia in timelines that are very short. Maybe you could maybe address your timelines or in which way you think you are.
David: I think timelines are likely to be short, but I think it doesn’t all come down to timelines. I think there are a couple other big factors. One is the attractability of these problems. I think if you’re optimistic about a technical solution, then it’s like “oh yeah, makes sense,” but I’m not optimistic about one. A lot of people I would say in the community are like, “Oh, coordination is just a non-starter, so we need to do a technical solution.” I’m not exactly of the opposite position to that, but I’m closer to the opposite.
Michaël: Is coordination not as bad as a solution that doesn’t work? You don’t see coordination as easy, but just not as hard as the alignment problem that is you don’t see any solution at all?
David: Roughly speaking, something like that. It’s more like these things can complement and substitute for each other to some extent. I think we need at least some amount of the coordination. Then another thing is you shouldn’t just say, “Here are my timelines,” and it’s a number, because timelines aren’t a number, they’re distribution. You might want to invest in something that looks like more likely to pay off over long timelines, even if you think timelines are likely to be short. You still have a significant amount of mass on long timelines. Another thing is neglectedness. If you look at the community right now, there are not that many people doing what I’m doing, I would say. I think there’s a neglectedness argument. Then when it comes down to it, to be honest, part of it’s just this is what I want to do and it’s personal fit and stuff like that.
Michaël: Basically, you try to do research that will pay off in after your median, because it will still happen more than 50% of the time, and this is where you have the most leverage?
David: No, that’s an argument that I was gesturing at, and that’s part of my reasoning, but it’s more complicated than that. Another thing is, you were talking about getting 50% of the machine learning community convinced to take this stuff seriously in the next five or ten years. Man, wouldn’t it be great if we got 10% of them.
Michaël: Yeah, 10% is good. ⬆
Picking The Interest Of Machine Learning Researchers Through Grants And Formalized Problems To Work On
David: I think right now, there are many talented people in the machine learning community that hypothetically could be directed towards this. To the extent that you think it is more of a technical problem, which again, I don’t think so, but to the extent that you do, you should still be really focused I think on getting machine learning researchers to work on that technical problem, or the associated technical problems. It’s kind of odd to me that people don’t seem to be doing that as much.
Michaël: How do we get them?
David: One thing is just be clear about what the technical problems are. To the extent that it’s actually a problem that is not this pre-paradigmatic thing, but it’s something that we have figured out how to formalize or make progress on, then grants and talking to people and being like “Here’s the thing that you should work on, and here’s why.” I’ve talked to some people who I think are fairly open-minded, and think seriously about the social impacts of AI in the future of AI, and don’t find these research directions very convincing either in the machine learning community. I think that’s interesting. That’s something that we should be talking about more, maybe.
Michaël: I think in terms of incentives, the question is are people altruistic or not? I would say people are interested in these kind of fields, or people tend to want to do good or something that is positive. If people aren’t just interested in doing research, maybe we need to reach a level where the research is interesting enough that you get people that are just nerd-sniped by the idea and want to do technical research. It depends on your priorities, and what the percentage of people that are actually altruistic, and how easy it is to make the problem seem interesting. It will not be as fun as building smarter and smarter models, I think.
David: I feel like I disagree with a lot of what you said. One thing is, I think for some people, they’re into the gamified engineering thing of “look at the cool thing that I did, or look, my number is higher.” That is a lot of people’s motivation. I think if you are more maybe intellectually minded and you care about understanding stuff and doing fundamental new work, then I think alignment is a great place to work, because we do have a lot of this stuff that is still kind of paradigmatic.
David: I feel like in mainstream ML, a lot of this is just kind of hacky stuff, and it’s just tinkering around with stuff until it does this or that. There’s interesting detail level questions, but the high level conceptual stuff a lot of the time is known. We know backpropagation, we know TD learning, we know building a model of the world, we know planning. All these basic concepts are already there. It’s more a matter of just implementing them in the right way and figuring out the details for a lot of the work there. Not to say there aren’t interesting new conceptual breakthroughs happening sometimes in mainstream ML as well. That’s one thing I disagree with. ⬆
People’s Motivations Are Complex And They Probably Just Want To Do Their Own Thing Most Of The Time
David: What else do I disagree with? Oh, I think the whole framing about altruism, I think everyone should be very skeptical about altruism, their own altruism, everyone else’s altruism. I don’t think we should totally taboo talking about it. I think there’s this Effective Altruism thing, and I think it’s nice that people are saying, “Hey, we should be more altruistic.”
Michaël: There’s a spectrum between being egoistic and a hundred percent altruistic. I think a lot of people are more on the egoistic side than the altruistic side.
David: I think that’s true, but it’s also hard to say what any one person’s motivations are. I don’t want to say, “Oh, that’s what’s going on here is people who aren’t altruistic enough don’t care, and so they aren’t working on this.” I think that’s just really uncharitable and…
Michaël: Dismissive.
David: …Probably pretty inaccurate for a lot of people’s actual motivations. I think under the hood, people’s motivations are complex and messed up for the most part. I think even people who are trying really hard to be altruistic, or think of themselves as altruistic, it’s like, you can explain what they’re doing without reference to altruism except as a buzzword a lot of the time. I would view a lot of this as more cultural. I do think there is some difference in personality or mindset that plays into this. I think some people are more ambitious, and some people want to have a big impact. I think probably that’s a factor here. But most people who have that I think would also be saying they want to have a positive impact. Where I think some people are more, “It’s not really about me and my impact, it’s more about just being a good person.” It’s egotistical or egomaniacal to try and be the hero who has a big impact, and we should just be more cooperative. This is more of a problem to address as a community or a society, rather than unilaterally by doing some amazing piece of research that solves the alignment problem or something.
Michaël: You’re saying that the people that tend to have high impact want to have a positive impact and want to do something useful and we need to shift this person to do the thing that is actually useful for AI or in the direction of …
David: No. I think most people don’t have that mindset. I think most people are more in the mindset of “I just want to do my thing, and be nice to people, and live my life, and be free to do the stuff that I want to do. If there’s something that is really outrageous, then I want to take a stand in my own little way.” I think that’s most peoples’ attitude, and I think that’s a totally fine attitude, especially in normal circumstances. I think what we want to do is we want to turn that kind of attitude to people who have that kind of attitude to make this something that they feel empowered to take a little stand on, and to work on if it strikes their fancy. I think it’s more right now, what we need to do is get people to understand and appreciate the concern, and to remove the taboo and try and, I don’t know, address the legitimate aspects of the criticisms that people are leveling at these ideas, but get people to understand and appreciate the legitimate parts of the concerns as well.
Michaël: Right. You’re saying basically, people just do their own thing until something very nefarious happens and then they’re like, “No, I don’t agree with this.” We would just need to find a way of presenting the problem where people can see why it’s important, and then they might just do the moral thing for this particular problem. The thing is, we haven’t framed the problem in a way that they understand it so that it’s important, they just think it’s kind of weird.
David: I don’t want to manufacture outrage. I think outrage will happen more naturally maybe. I think it’s more just getting people to understand. ⬆
You Should Assume That The Basic Level Of Outreach Is A Headline And A Picture Of A Terminator
David: I think there’s a lot of just lack of basic understanding. Earlier as you were talking about, people had the chance to read Human Compatible or Superintelligence. What I’ve been telling people recently, it’d be great to have more data on this, actually. I think it’d be cool for people to run a survey about how much people in the machine learning community know and understand about alignment and existential safety and the ideas there. My current recommendation is by default, you should assume that the average machine learning person you’re talking to has seen a headline and a picture of a terminator, and that’s it. They didn’t read the first sentence of the article. Maybe they haven’t even seen any of the articles themselves, they’re just aware of their existence. It’s that level of awareness that I think is probably, maybe not the average, but the median or the mode.
Michaël: If this is the level of outreach that has been achieved, then the question is, how do we spread more than one headline to 10,000 researchers? How do we spread this one article or one blog post?
David: I think you talk to people, you try and create more sources for them to learn about it. You try and encourage people to learn about it. It’s a lot of little things, to some extent. There’s not one big solution here.
Michaël: If there are possibly a thousand people watching this video, what would be technical problems or papers they can look at that’ll actually make them think, “Oh, this is a real problem or this is important.” Is there any research direction you think?
David: That’s a really good question. The problem is I’m not up to date on the most recent stuff, because I just haven’t taken the time to read it. I know there are recent things that people have written that are an attempt, or produced that are attempts to make this more clear and legible and stuff like this. ⬆
Outreach Is About Exposing People To The Problem In A Framing That Fits Them
Michaël: Like AGI Safety Fundamentals from Richard Ngo. I think it’s one.
David: I did look through that. At some point, I felt like it was still going to turn off maybe your average machine learning researcher or a lot of machine learning researchers. It’s a little bit too out there. I think it’s a good resource for people who are already sympathetic to these concerns, probably. If you’re just trying to make the basic case, I will say, my understanding of this as a problem of just lack of awareness and something that is more about educating people rather than winning arguments, came from a large extent from running a reading group on Human Compatible at Mila in maybe 2018 or 2019, something like that. I’m not sure when the book came out. Shortly before the pandemic, let’s say. It just went really well compared to the reading groups that I had tried to run earlier on AI safety and ethics topics. I think it was because it was just well-written, accessible, and just really kind of walking you through the basic case from a popular science point of view. I think I was taking random alignment or safety papers and trying to talk about those. It’s a very broad and disjointed field. People were just like, “What is this all about?” Anyways, I didn’t realize how much basic stuff people hadn’t been exposed to. That was giving the sense that maybe this is just a matter of exposing people to the ideas in a format that isn’t framed as this thing of, “Well, are you altruistic or not? Are you a good person, or are you a bad person who builds bad AI and isn’t trying to do safety?”
Michaël: Something as coherent as the book ‘Human Compatible’ from Stuart Russell, that presents a basic case from a unified agent RL framework, and the solution…
David: Is the solution in his book cooperative IRL?
Michaël: Yeah, cooperative.
David: Which I don’t think that’s the solution, but…
Michaël: It is pretty easy to understand and elegant. ⬆
The Original Framing Of Superintelligence Would Simplify Too Much
David: I think it’s not clear to me to what extent we need to just spread the ideas that we already have versus developing new framings on things. It does seem like the latter is also important, because I think everyone is just really anchored on what I call the spherical cow version of the problem, which is if you didn’t read Superintelligence but you read some reviews of it, you get this picture of, yeah, it’s just about AGI soon is going to go from zero to 60 overnight. It’s going to be a superintelligent agent, and then no matter how we try and control it, we will fail. Then it’s going to take over the world and kill everyone because of instrumental goals, and that’s it. Multi-polar stuff could happen, but it just doesn’t matter because then one of them is going to become the best one, and it’s just going to have a decisive strategic advantage. I think actually, it’s been a while since I read Superintelligence, and I’m not sure I ever read it end to end. I think I read it in bits and pieces scattered around, because I had read a bunch of the papers and stuff that it was based on before that. I think there was actually a lot more nuance in there. I think it kind of gets a bad rap. I don’t think it just presents this simplified, spherical cow version of the problem, but I think it’s easy to come away with that as the main threat model there.
Michaël: I’ve heard stories from other people telling them about Superintelligence ten years ago, and now it’s hard for them to update on more realistic scenarios, where it’s threat models that are just power seeking or more continuous takeoff, and models are unaligned in a more nuanced way.
David: Yeah.
Michaël: When you talk to other academic peers or colleagues, what are their reactions to your arguments? Do they say, “Oh yeah, seems sensible?” Have you convinced anyone that it was a problem?
David: Yeah, I don’t want to…
Michaël: Generalize, I guess. ⬆
How The Perception Of David’s Arguments About Alignment Evolved Throughout The Years
David: Well I was going to say, I don’t want to attribute people’s interest or being convinced of this as a problem to me solely, but there are people who I’ve talked to who have said that I’ve had a significant impact on how they think about it. I think I’ve had some impact. I think one person was like, “Okay, I’m convinced,” at some point. I was like, “Maybe I should follow up more.” Let’s see, what was the question? Oh, how do people react? I would say when I was still a master student, when I just started, people reacted very dismissively and just, “That’s just crazy sci-fi nonsense. I can’t believe you take it seriously.” Then maybe within a few years, once people had a little bit of exposure, or maybe had just talked to more people, or maybe it was just that I was becoming more senior or was presenting more of a case, it seemed like the attitude changed. You would still get that from some people, but it was kind of more of a like, “Oh yeah, okay, whatever. Fine. You can think about that. You can think that. I’m not going to make fun of you for it.” Then maybe a couple years after that, it was more I thought people were pretty respectful of it and I thought, oh great, this is progress, but I’m not sure how much that is … I felt like, oh, it’s being treated like any other research topic, which is definitely progress. I also felt sometimes, maybe it’s not in the sense that people would be like, “Okay, cool,” but they wouldn’t want to actually dig in and talk about it in more detail the way that people often will when you’re talking about research topics. I was like, “I feel a little bit like somebody who’s talking about being part of some cult or something,” and people are like, “Yeah, yeah, that’s nice. That’s great. Let’s just change the topic.” Now I think it has become hard to tell, because I think it’s harder to get people’s real opinions. When you are a professor, you have more status. People are more differential and stuff.
Michaël: You mean your students? If you talk to other professors in Cambridge in UK or in the US, maybe they would have similar rationale. ⬆
How Alignment And Existential Safety Are Slowly Entering The Mainstream
Michaël Do you think Alignment is getting more into the mainstream, let’s say, in the UK, London, Cambridge, Australia, those kind of places?
David: I think historically, the macro trend is yeah, it’s just going more and more mainstream. Again, Alignment versus existential safety, I think they’re both going more mainstream. I think Alignment is maybe having a bit of a moment or had a bit of a moment with foundation models. People are also rolling their eyes at this because they’re like, “Okay, finetuning is Alignment now? Whatever.” There’s at least this obvious problem with foundation models where it’s the pre-training objective is not aligned. You want the model to answer questions honestly or do translation or something. It can do some of that stuff, especially if you prompt it right from the pre-training, but the pre-training was just predicting the next letter. There’s just this Alignment problem just staring you in the face. We were talking about this way earlier in the interview of you can’t really tell if it’s capable of doing something because you don’t know if it’s trying. Just a huge part of the problem with these big models is just to get them to try to do the right thing. That’s the Alignment problem as I think of it. But again, a lot of people might be interested in that, but just from the point of view of it’d be great if we could get this thing to drive a car, so can we get it to try to drive the car, and then maybe it’ll be good enough at driving the car if we can get it aligned in that sense with that task?
Michaël: It’s hard to disentangle capability versus safety when you are trying to have more typical models that actually do what you want it to do. I know of some people at DeepMind who are not exactly working on the Alignment team but still do RL from Human Feedback, or aligning the larger models to do exactly what you want them to do. It’s hard to say. I think at Open AI, the InstructGPT paper was the first time Alignment work was actually used to improve their product and not just theory.
David: I’m not sure about that. I had the impression that they were doing some finetuning as well for the other models that were available on the API, to do things like make them less racist and stuff like that maybe.
Michaël: Right. Bias. ⬆
Alignment Is Set To Grow Fast In The Near Future
David: Existential safety, I’m optimistic that there is going to somewhat organically be a big see change in the Machine Learning community’s mindset about this in the near future.
Michaël: I think Ilya Sutskever said in a tweet that he thinks in two, three years, Alignment will see the same growth as Deep Learning had a few years ago.
David: I think he stole that from me.
Michaël: Really?
David: I’ve been for at least a year now, I’ve been saying that stuff in talks.
Michaël: It’s a subtweet?
David: I don’t know. I’ve said GPT-3 is Alignment’s AlexNet moment, and you can see this in terms of, yeah, I think a lot of different ways.
Michaël: Wait, why GPT-3?
David: Oh just because that was the big thing where it was like, oh yeah, Alignment matters now. We were just talking about if you want to get GPT-3 to do the stuff that you want it to do, you have to align it.
Michaël: Did you see a shift of people being more convinced of Alignment GPT-3? Was it easier to convince people?
David: I don’t know. Hard to say. I feel like it’s just hard to judge because there’s been one machine learning conference since the pandemic. GPT-3 was during the pandemic or right before the pandemic. I don’t remember. It’s all blur.
Michaël: Wait, there was no conference since 2020?
David: I should say the only conference I’ve been to since the pandemic was ICML 2022, in-person conference. It was still not back up to the pre-pandemic levels by far. That’s where I would maybe have the most of these interactions and conversations, and get a sense of where the machine learning community is at with all this stuff. ⬆
What A Solution To Existential Safety Might Look Like
Michaël: A lot of people on Twitter wanted to get your take on what would a solution look like? Imagine we solved alignment. Obviously, we cannot solve alignment. Imagine everything goes well. Why is there a world in which David Krueger made it happen, one of your solutions or someone’s solutions works.
David: It’s hard for me to imagine things going well in the way that isn’t just mostly due to luck, unless we solve some of these coordination or governance problems. I think a couple things I’d like to see happen are… there’s a broad awareness of understanding of and appreciation of existential safety concerns in the machine learning community and in broader society. Then we start to take this very seriously as a problem, and figure out how to coordinate around it, and figure out what the rules should be of the game, in terms of how are we going to address this? How are we going to do proper testing? What regulations might we need? How can we enforce international agreements? All that stuff probably has to happen.
David: That’s roughly speaking necessary and sufficient. I think there might be extreme versions where it’s, let’s say that in 10 years time, just anybody on their laptop can, with three lines of code, write this AGI system that can become superintelligent overnight and kill everybody. Then it’s not clear what we can do. I think it seems, roughly speaking, necessary and sufficient to have a good level of appreciation and awareness, and being willing to and able to say, “We all agree that this is a sketchy, dangerous way to proceed, so let’s not do it,” and then we don’t do it. That might be a gradual thing, where over time, the bar raises, or maybe it goes down because we learn more, and things that we were worried about we realize aren’t actually concerns. This has to be an ongoing and adaptive process, I think. Then I think at the end of the day, we also, assuming that we can build “aligned AGI” at some point, then we also want to take the time to solve the… I forget what people call this, but whose values are we loading, or what are we aligning to? The alignment target.
David: I think that’s a big socio-philosophical problem that I don’t know how to answer. Nobody right now knows how to answer, and we want to take a long time. We want to really be able to sit back and take our time addressing that. We want to be able to do that in a climate where the competitive pressures that currently exist that drive people to just go full steam ahead, trying to gain more power and build more powerful technology and manipulate each other, where those are managed and under control. That’s what we should be aiming for. Then from there, hopefully we can actually figure out what we should be doing with this kind of technology. ⬆
Michaël: Before with Ethan, we discussed the performance on all downstream tasks and learning curves and I thought it would make sense to just start with learning curves. Why do they matter? And you have published some papers on this. What do we mean by learning curves? What kind of research have you done? ⬆
Latest Research From David Krueger’s Lab
David: It’s a pretty open-ended scientific inquiry. We’re trying to better understand the learning process and generalization and study how that happens throughout the course of training. That could both help you figure out if the model is generalizing the way that you want. So if it’s picking up on the right concepts in the right way or what factors make it more likely to do that. Once we have good ways of studying this, then we can do interventions on the training process, on the data etc, and see how this changes these profiles of the downstream performance over time or the performance on different subsets. And then that can help us design algorithms that make sure the model generalizes the way that we want. The other thing that we can do is we can try and predict and discover. It’s a little bit like interpretability research, but in my mind it’s maybe a better or more sensible starting point or it’s at least complimentary to work on mechanistic interpretability. You can understand a lot about the model by its behavior on particular examples and how that behavior changes over time. This might also help you detect things like deception or power seeking as they start to emerge if they start to emerge.
Michaël: Because with deception the model would actually be trying to not show its performance on the learning curves.
David: I’m not sure about that. Good question. How would this actually show up? I guess what I’m imagining is something more where you have some examples that you use to evaluate deception in some way or I haven’t thought about the details here much to be honest. ⬆
David’s Reply To The ‘Broken Neural Scaling Laws’ Criticism
Michaël: We’ve talked about deception a lot on the last episode with Ethan Caballero. On a paper you co-authored with Ethan, Broken Neural Scaling Laws, people in the comments were dubious that it would be able to predict so many things or that it was actually modeling something of interest because you would fit a different model or have different parameters for every single downstream performance metric. What do you have to say about those comments?
David: I know there are a lot of ways that you can, in a sense, attack this paper and I think there are some limitations, and I think most of those limitations are things that we’re aware of and that are important. There are significant limitations. On the other hand, the thing that you mentioned specifically, fitting a different model for all the different downstream scaling things, that just makes sense to me. I don’t know what the sensible alternative would be. You can do this in some hierarchical way or where you say we have the scaling curve and then these all descend from it and you can maybe compress the total number of parameters you need in some way doing something like that. We’ve talked about doing things like gaussian processes or more heavy-duty ways of modeling these as well. And I don’t know that there’s probably a sensible way of doing that. ⬆
Finding The Optimal Number Of Breaks Of Your Scaling Laws
David: I think, if nothing else, that some Bayesian approach would make sense for model selection because we have this N, which is the number of breaks in the curve. And right now Ethan’s basically just splitting that by hand and ideally we’d like to have a method that automatically selects how many breaks to use. I think that would really improve the overall value of the method.
Michaël: Can you do the same for like knn or something where you just increase N and select the best value for N equals one to 10 or something?
David: It’s an empirical question whether or not the hyperparameter N is something that you need to worry about overfitting. And if you don’t need to worry about overfitting then it’s fine to just do trial and error and see which one does the best. So maybe that’s fine in a lot of cases. I think in general, one thing is that we do these experiments in the paper where we do find that the broken neural scaling law with one break just really does a good job on these tasks from the paper from earlier this year. And that’s where they compared basically scaling laws that don’t have a break and then some new thing that’s like a broken neural scaling laws, but I think just not as well crafted. And on the majority of something like a hundred or so scaling curves, it outperforms all of the four alternatives. But there’s a significant number of them where something simpler that doesn’t have any breaks outperforms. And so that’s a special case of the broken neural scaling law with zero breaks, so it would be nice if we could just automatically choose whether or not to include a break or not.
Michaël: It’s the broken neural scaling law, but the ‘broken’ is at zero so it’s just neural scaling law.
David: Yeah. If you wanted to do it the way that you’re describing, then you need a validation set, which would be extrapolation points. And I think there should be a way to do this just based on marginal likelihood instead, which doesn’t require looking at validation performance or extrapolation performance. It just essentially asks how sensitive is the fit of this model to the data, to what is it to the data or to the parameters of the model. Anyways, I was trying to say if this model is robustly good at fitting this data, then it’s more likely to be a model that generalizes as well. ⬆
Unifying Grokking And Double Descent
Michaël: You mentioned zero break and then there’s one break and two breaks. And I think most tasks have one break and one thing you guys were able to model was Double Descent, which was never done before and people weren’t trying very hard. And I think in one of your talks you mentioned that you can model double descent and working in a similar way.
David: That’s the third of these three papers that’s on a workshop paper at NeurIPS that I mentioned earlier. This is a paper by Xander, visiting undergrad from Harvard and one of my PhD students, and I should mention the metadata archeology paper that’s with my student Shoaib. And then also external collaborators, Tegan Maharaj and Sarah Hooker. This Grokking and Double Descent paper is basically just saying, hey, these are maybe like… look pretty similar phenomena, in one case. Actually… so when you zoom in on the learning curve you see that there’s a little bit of Double Descent going on already.
David: So the main difference is just how long does it take for the second descent phase to kick in. And also I guess Grokking was only ever shown in terms of learning time. So we also showed that it can occur in terms of the number of parameters in that paper. The thing that was interesting to me about that paper was we were trying to model how the overall performance is a function decomposed performance on different subsets or how it relates to the model learning different patterns within the data. And I think that’s a really interesting thing to try and model.
Michaël: What kind of performance are you measuring with it?
David: Just training and test accuracy. Basically we’re looking for a model that’s very abstract and then maybe we’ll figure out how to ground it and test it and stuff like this. But just a very high level model that says, here’s the rate at which you’re learning about different patterns in the data or here are the different patterns that you have currently learned. And then from that we can predict your training and your test performance. And in particular we can show how a model like this could give something like double descent where the key features of this model then are that the patterns compete to figure out which examples they’re going to classify. And some of them generalize better and some of them generalize worse. So as you learn these patterns, you can see that you’re learning more stuff, so you should be able to predict more stuff, but then your predictions might not generalize as well depending on which pattern. So if you start learning a pattern that doesn’t generalize as well, that might actually hurt your performance, your generalization performance, even if your training performance is going up.
Michaël: So it’s a very abstract model of what it would look. It’s not a concrete task.
David: Yeah, so far it’s just entirely abstract. ⬆
Assistance With Large Language Models
Michaël: There’s another paper you’ve been mentioning in one of your talks is Assistance With Large Language Models, which is closer to what people do now with the foundation models. And I think you can relate it to alignment because it’s kind of close to cooperative RL as well.
David: Yeah.
Michaël: Do you want to say more about that? I’ve tried googling and I think it’s not out yet.
David: That’s right. It’s another workshop paper. The idea here was, can we get Language Models to act as assistants to humans? And in particular to ask clarifying questions from the human about what they want from the system.

David: And so we just did the simplest first pass at this where the language model has the option of either answering a human’s query directly or, if it doesn’t find that query clear enough, it can ask a clarifying question, get clarification from the human and then answer. And the idea is: it should do whichever of these is appropriate based on how clear the original query was and how well it understood it. So we build a new data set with human labels for this extra data about the clarifying question and the clarification, and then we train the model to act as a human stand-in and then we train another model to interact with that human stand-in. And then at the end of the day we find that it can in fact learn to do this basic assistance task.
Michaël: What’s a human stand-in?
David: It’s just a language model that’s been trained to play the role of the human in this interaction. The high level pitch here is to get Language Models to interact appropriately with people so you have some idea of what the interaction protocol should be and you want to train it to follow that interaction protocol. And one much more efficient way of doing that is to use a human stand-in instead of having to actually have humans interact with the model all the time during training.
Michaël: So you limit the amount of feedback by having the AI do the feedback somehow.
David: In this case, the AI isn’t actually giving the feedback or what I would describe as the feedback, that’s the part which determines the loss. It’s more like giving some of the context. And so at the end of the day, the agent is going to look at the original question and then if it asks a clarifying question, the whole transcript of original question, clarifying question, clarification, and then have to predict the answer. And the answer is still coming from the actual dataset that was constructed by people. But the clarification is coming from the human stand-in.
Michaël: So the dataset has the question and clarifications. What’s exactly the dataset?
David: I think the original dataset just has questions and answers and then in addition to that we collect clarifying questions and clarifications and then we also train this human stand-in to produce those clarifications. And then we train the language model with that human stand-in to get more interaction data. Actually, I have to admit, I’m not sure if we train it with the human stand-in or just evaluate it with the human stand-in.
Michaël: As you mentioned, it’s work in progress. It’s not an Arxiv yet, so maybe check in a few months or few weeks.
David: Yeah, it is at the Machine Learning Safety workshop and a few other workshops at NeurIPS. ⬆
Goal Misgeneralization in Deep Reinforcement Learning
Michaël: Another cool paper that I think you can find on Arxiv that relates to what we have talked about generalization is Goal Misgeneralization in Deep RL with Lauro as well, as you mentioned before. This one is very cool because I’ve seen it on a bunch of alignment blogposts for an example of goal misgeneralization, which is important for alignment, right?
David: Totally. This is a paper that I hopped in towards the end, the co-authors had basically written the paper, put it on arXiv before Lauro joined my group. But then I was like, let’s try and get this accepted at a machine learning conference. So they actually submitted it to ICLR previously, and it was pretty borderline but didn’t get in. [Note: the paper was actually accepted at ICML as a poster]. I think in a way it’s a pretty straightforward from a machine learning point of view, which is that sometimes your model doesn’t generalize the way that you want it to. And this is well known, well studied problem in machine learning at this point in the context of computer vision, especially where you have spurious features and the cow on the beach, and I won’t get into it too much, but a lot of people will know what I’m talking about there. And this is more or less the same problem or same type of problem in a Deep Reinforcement Learning context.

David: The figure one is basically that you have an agent that’s trained on Coin Run set of procedurally generated environments that are different levels of Super Mario Brothers, hopefully kids still know what that is. And so it’s trying to run to the end of this level, avoid all the enemies, and then at the end of the level there’s a coin and it gets reward when it picks up the coin. But the coin is always at the end of the level during training and so what it actually learns to do is to go to the end of the level and if at test time you move the coin around so it’s not at the end of the level, it generally ignores it, maybe even tries to avoid it because it thinks it’s like an enemy.
David: Because most of the things in the level are enemies and just runs to the end of the level. And so it’s basically misgeneralized the goal, so it’s behaving as if its goal were to get to the end of the level as opposed to pick up the coin. And so that’s kind of a nice demonstration in a way of something that people have been thinking about and talking about in AI safety for a long time, which is the idea that you can train a system to do one thing, but it can end up pursuing a completely different goal from even the one that you trained it on.
Michaël: If I were to do the devil’s advocate, you could say that the model generalized properly, but because his training data was just a coin plus a wall at the end.
David: Oh yeah. I mean there’s nothing in the training setup that tells you whether the wall or the coin is the goal. So it’s perfectly correlated in the figure one experiment. It’s just totally unfair to the agent in a way to say you’re mis-generalizing. It’s just underspecified but I think that is reflective of the real world, in general things are underspecified. And we do a number of other experiments in that paper as well, which show that this can happen to a much lesser extent even if you do randomize the coin location somewhat. So the correlation doesn’t have to be perfect and it can happen in other contexts.
Michaël: What other contexts? ⬆
The Key Treasure Chest Experiment, An RL Generalization Failure

David: I think the coolest experiment in my mind is this keys and chest experiments. You have little gridworld-type maze and the agent is going around trying to pick up keys and open chest. So every time it opens a chest, it gets a reward. To open the chest, it needs to have a key. In the training environment, the chest are plentiful and the keys are rare. In the test environment it’s the opposite of that, it’s backwards. And so what the agent learns is basically ‘I don’t even need to worry about the chest, I’m just going to bump into those randomly as I move around, what I need to do is make sure I have enough keys that when I find a chest I can open it and get the reward.’ It just tries to collect keys even though there’s no reward whatsoever for having a key, it’s just an instrumental goal to being able to open a chest. I think this really exhibits the instrumental goal seeking behavior in a nice way.
Michaël: Is this an actual experiment or just a talk experiment?
David: It’s an actual experiment. The main contribution of this paper in a way is just to run actual experiments to show this. There’s one other thing I want to mention in terms of contributions. So this is one of my contributions when I actually got involved was to basically emphasize how this differs from the supervised learning spurious feature thing, which I think is important because otherwise for a lot of people in machine learning, this would just be really boring paper because like I mentioned, people are already familiar with this kind of problem, and that’s that you can actually formally distinguish two kinds of generalization failures in the context of RL. The original paper already intuitively talked about the kind of failure where it just does random stuff and it’s not doing anything sensible. And then there’s a kind where it’s clearly behaving like an agent that has a goal and pursuing that goal and usually quite effectively. It does in fact get to the end of the level, it does in fact collect lots of keys.
David: You can actually formalize that in the context of RL by basically saying we have some distribution over goals and then we’re going to ask is it well modeled as something that is pursuing one of these goals? If you have an MDP, so if you don’t have a MDP, you might say this distribution over goals is kind of arbitrary, but in an MDP it’s really not. Something that is clearly not agentic in an MDP context is something that just does different things every time it’s in the same state. Optimal policies and MDPs generally should be or at least can be deterministic. If you see very random behavior, then that thing isn’t very agentic.
Michaël: Because it takes the same actions every time, you can say that it’s closer to an agent that has a goal.
David: If it does the same thing every time it’s in a certain state, that makes it look more goal directed. And of course if you have some more prior knowledge about what are reasonable goals, then you can make this work even in palm MDP and so on and so forth. ⬆
Safety-Performance Trade-Offs
Michaël: One line of research of trying to have less agentic systems and control the amount of dangerousness of models we deploy in the world appears in your kind of graph. You often point at safety performance trade-offs. This is something I remember from watching one of your talks. What are safety performance trade-offs? Maybe there would be a nice picture explaining while you talk in the video.
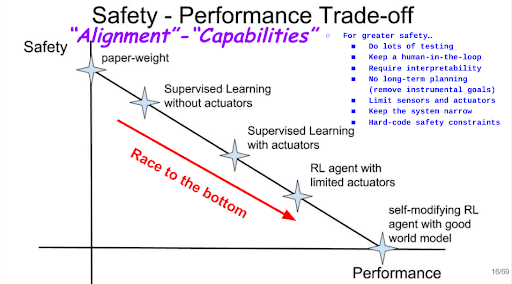
David: There are two things I want to say about this plot. One is that originally to me this was an argument for why existential safety is a hard problem and that’s still the main point of that plot. And actually just this morning or last night, I realized a pretty crisp way of explaining what I think is one of my main cruxes with a lot of the AI existential safety communities, so I want to mention that now. And it’s exhibited by this diagram. ⬆
Most Of The Risk Comes From Safety Performance Trade-Offs in Developement And Deployment
David: Maybe I said this earlier in the interview as well, a lot of people talk about solving alignment or they talk about this technical problem that can in principle be solved, and their main concern is maybe that we won’t solve it in time. And I think that’s just kind of a really terrible way of looking at it because I think there will always be some amount of safety performance trade-off no matter how good of technical progress we make on alignment. I don’t view it as something that can be solved perfectly any time soon anyways and then we can just use the alignment techniques. A lot of people are worried about us underinvesting in research and that’s where the safety performance trade-offs are most salient for them.
David: I’m worried about the development and deployment process. I think where most of the risk actually comes from is from safety performance trade-offs in the development and the deployment process. For whatever level of research we have developed on alignment and safety, I think it’s not going to be enough that those trade-offs just go away. We’re always going to have these things that we can trade-off. These knobs or levers, these ways that we can trade off safety and performance. ⬆
More Testing, Humans In The Loop And Saving Throws From Hacks
Michaël: What are those levers you think we can trade off?
David: One example is you can just test your system more before you deploy it, and that means that it takes you longer to deploy the system so you don’t get to send it out there in the world and start reaping the benefits of having that system acting on your behalf. Another one is keeping a human in the loop. So in general, a lot of the times having a human overseeing the system’s behavior and saying, “Oh, this doesn’t look safe. I don’t know what’s going on here, let’s shut it down, or let’s not let it take that action.”
David: That’s something that could make it a lot more safe, but also can really harm the performance of the system because you want a lot of systems to be acting like at superhuman speed. Do more testing, keep a human in the loop, you can only deploy systems that you really understand how they work. You have some interpretability tool that you really trust and have a good reason to trust, or you have some theoretical reasons to expect that the behavior will be safe. And the more such requirements you place on the deployment, the fewer systems you can deploy and especially the fewer powerful black box systems that you can deploy.
David: You can also just add a bunch of hacks that say things like, don’t leave this room, don’t hit people. Just you can just come up with constraints on the behavior of the system and hard code those. And of course the system might find ways to get around them, that’s a classic concern for AI safety. But the point is maybe it won’t and maybe you will have all sorts of trip wires that just shut the system down, that’s going to give you some saving throws as people like to say, where if the system starts trying to take control or do some sketchy stuff, it might get shut down instead. But at the same time those might trigger when you really want your system to still be on and still be functioning. ⬆
Would A Human-Level Model Escape With 10^9 years
Michaël: I guess my internal Yudkowsky is kind of screaming, saying that, of course when the thing is human level or smarter, when it’s able to reach a strategic advantage, it’ll not care about those kinds of things. So I guess for me, maybe I have a different point of view than you or Ethan, and once we reach the point where it’s capable of doing dangerous things, it’ll be able to bypass those safety measures or those kind of triggers, those fire alarms.
David: That’s a very binary way of looking at it. If you have something that is AGI like a person and you put them in some room that they’re not supposed to get out of, like a prison, a lot of the times they don’t manage to get out. If you have a really smart person and you put them in prison, they still typically don’t find some clever way to get out.
Michaël: Even if they have access to 10^9 years to think before acting because they try to maximize the probability of them succeeding, AlphaGo style? They may reason on different timeframes.
David: This is just the question of how much smarter is it going to be than a person and in what ways and things like this. I just want to say people have very different intuitions about this, but it’s just intuitions. There are all these things that I think are safety performance trade-offs and I think that is why x-risk is high, but also we don’t really know how these safety performance trade-offs look. So people have different intuitions about them, but we haven’t done the research to actually figure out if you have a system that is this smart in this way and plans this far into the future, can it get out of this box. Long-term planning, how far does the thing plan into the future? If it makes more long-term plans, it’s more likely that grabbing power is going to pay off. If you’re trying to maximize the number of paperclips over the next two seconds, you probably just make paperclips instead of making nanobots and all that. ⬆
How To Limit The Planning Ability Of Agents: A Concrete Example Of A Safety-Performance Trade-Off
Michaël: How do you limit planning? You just make it myopic and only care about one step? Wouldn’t there be incentives to have agents that can plan in the long run?
David: We talked about my paper on this earlier. It’s an open research problem, but maybe you just use myopic RL and it just works as long as you make sure that you don’t slip up. And then you can also just design your system in such way that it’s meant to accomplish some narrow task. That’s related to having a short horizon, but you could also say it’s more about the domain that it’s operating in. And then along with that you can say, I’m going to try and restrict the sensors and actuators or restrict the knowledge of the system. Make it some savant that only understands how to build a better paperclip and doesn’t understand anything about the wider world out there. Maybe doesn’t really know that people exist in any sense and stuff like this. And of course a lot of this does go against the full-on generality, of the kind that humans have, but I think it is an open question, how much you can have something that still has the same fundamental qualitative reasoning processes that humans have, but is maybe thinking over shorter horizon or maybe lacking some of the knowledge that we have, it has a different world model that doesn’t include some of the strategically relevant factors. Or maybe it does include something like, ‘oh yeah, by the way, there’s some omnipotent, omniscient being who will punish you if you ever do anything wrong.’ ⬆
Trainings Models That Do Not Reason About Humans: Another Safety-Performance Tradef-off
Michaël: I feel like the way we train our models right now and we just train on all of ImageNet or all of Reddit’s posts with more than three karma to create the Pile or something. Of course humans are in the training set, it’s very hard to construct that dataset without humans or without information about it being an AI.
David: This goes back again to other stuff we discussed before where there’s some information about humans through the human labeling process.
David: Let’s just talk about ImageNet. Is it enough to reverse engineer all of human psychology and figure out how to hack humans and manipulate us? I would say probably not. I think, no matter how smart you are, if all you see is ImageNet, you really don’t know much about people. And, of course, people are going to have incentives to train systems that have more performance at the expense of safety. They’re going to have incentives to train systems that have more sensors and activators that have more knowledge about the world, et cetera. That’s kind of the point so there’s the strategic point of people are going to turn these knobs to unacceptable levels. And then there’s the technical question of, so how do these knobs actually work? I’ve been thinking about the strategic point for a long time. The technical point is something that I just recently decided would actually be a really interesting thing to focus on in research. ⬆
Defining And Characterizing Reward Hacking
David: I was talking about these safety performance trade offs and I was talking about the narrowness of the system. When I’ve been talking about this stuff recently, that’s the way that I usually motivate this work on reward hacking. This is a NeurIPS paper that we had this year with Joar Skalse, Nicky Howe and Dmitri Krasheninnikov. The first two are PhD students at Oxford and Mila. And it’s a pure theory paper, which is kind of cool, so it was my first NeurIPS paper, my first pure theory paper. Joar did all the theory. I just checked it and I came up with the definition and the motivation of the paper. And so the question that we were asking is, can you have a reward function that is safe to optimize? That isn’t the true reward function that is somehow maybe simpler or more narrow, which would be really good news for alignment if this was the case, right? Because then you could say, “Oh yeah, learning everything about human values seems really hard.” So if you’re thinking about reward modeling where you learn the reward function, that’s probably a non-starter. But maybe we can just learn how to behave in this specific domain or how to perform this specific task and encode that as a reward function. And then if the agent optimizes that reward function, it’ll be fine because it won’t do anything bad according to the real reward function to the extent that there is a real reward function. But the real reward function here is meant to represent everything that we care about, all of our values or preferences. ⬆
Detecting Hackable Proxy Rewards
Michaël: The task is good reward specification, adding the perfect outer alignment.
David: You want a reward function where it’s a proxy for the thing that you actually care about and maybe it’s much simpler. But if you optimize that proxy, it’s going to be fine. You won’t mess up according to the real reward function. We formalize that in this definition that says a pair of reward functions is hackable. So the proxy could hack the real reward function if it’s possible for the reward to go up according to the proxy. And, I guess, I should say the returns, the value, the expected returns, when you change policies while simultaneously it’s going down according to the real reward function. So if during the course of learning, you could be like, “Oh, this is great. I’m doing better according to my proxy.” But actually you’d be doing worse according to your real reward function, then that means that your proxy is hackable because learning, in general, is going to try and drive up the reward according to the proxy. That’s what you actually point your optimization at. So an alternative would be maybe these reward functions are always increasing monotonically. When one goes up, the other one goes up, but they don’t go up by the same amount. That’s one thing you can imagine happening. Another thing you can imagine happening is one of them goes up but the other one stays constant. So maybe the real reward is going up or even going down but the proxy is staying constant.
Michaël: Let’s say reward here is expected reward, expected reward over time of a policy, not reward on that critical state, right?
David: The value of the policy but in practice you might just look at the reward of these in experiments. How good the policy is doing according to that reward function is what I meant to say. You could have your proxy that is just not changing but the real reward is going down. And you say, “Oh, that’s bad.” The real reward is going down and that’s true, that’s bad, but it’s not going down because you’re optimizing the proxy. Because you aren’t increasing the proxy. So the optimizer isn’t pushing you. Again, maybe it depends in some sense on some induction biases or details about how the optimizer works. But your optimizer isn’t going to be pushing you in the direction of something that just looks equally good according to the proxy. So there’s no optimization pressure that’s driving that decrease in real reward, in the case where the proxy is staying constant. So we’re only really worried about the case where there’s optimization pressure that is hurting your true reward. So you are training the agent to get more proxy reward and that’s why it’s getting its real reward.
Michaël: When you’re putting too much pressure to get proxy reward, real reward goes down?
David: That’s reward hacking according to our definition. And we say a reward function pair is hackable if that can ever happen. If there’s any pair of policies such that moving from pi to pi prime looks like an improvement according to the proxy but it looks worse according to the real reward.
Michaël: It’s like when you can move in policy space from one point to another, where you can be improving on the hackable reward, so the proxy reward, but you’re losing on the other one.
David: Yeah.
Michaël: And so you say “don’t do this”? “You’re not allowed to do this”?
David: Yeah. It’s throwing out that definition and then analyzing the properties, the definition. Basically, if you want to make sure that you never have reward hacking, one way to do that would be to find a proxy reward that isn’t hackable. And one of the main results of the paper is that’s not really possible unless you restrict the set of policies you’re optimizing over. Then the only non-hackable reward functions are the trivial one where everything is equal or something that’s equivalent to the original reward function. ⬆
Reward Hacking Can Be Defined In Continuous Environments Because The Sequence Of Policies Is Finite
Michaël: If I were to talk as a machine learning researcher, I would say, “Yes, but you’re only talking about MDPs or a gridworld or something.” And I know you haven’t said this, but I feel like if you’re talking about a more continuous MuJoCo environment, the space is so large that there are an infinite number of policies compared to moving from one to another discrete piece but it’s a continuous set of policies, right? So it would be impossible to apply this to continuous environment.
David: No. You can apply it just fine there. What we’re doing is we’re abstracting away the training process, like the learning curves. When you actually see reward hacking in practice sometimes, where the real reward and the proxy are both going up. And then at some point the proxy goes up and the real reward goes down. And as soon as that happens, your optimization is producing a sequence of policies. That means that there was a policy before that happened and a policy after that happened. And that’s that pair of policies that I’m talking about.
Michaël: So you’re only talking about those two and not the infinite number of policies in between or-
David: Yeah. Because you don’t actually visit those, you still do a discrete step of optimization proceeds by these discrete steps usually.
Michaël: Right. So there is a finite number of optimization.
David: I think, it’s a really cool paper. I didn’t learn as much from it as I would’ve hoped because the definition ends up being really strict, which is not surprising because we’re not saying anything about how bad it is when you have hacking, how much does your real reward go down? It could go down just by a tiny amount and maybe you don’t actually care that much. And there are a lot of other caveats and interesting details I could talk about more. But I just encourage people to look at the paper or reach out to me. ⬆
Rewards Are Learning Signal, Not The Goal
Michaël: What’s the name of the paper?
David: It’s Defining and Characterizing Reward Hacking. That’s basically exactly what we do in the paper. We define it and then we characterize it and show when you can have these hackable or unhackable pairs of reward functions. But to the extent that you can draw conclusions from this and I think we’re doing some empirical work on reward hacking as well, that suggests the same thing. You shouldn’t really think of your reward model as a reward function. There’s no reward function out there that you can just say, “Let’s just optimize the hell out of this thing.” Except for the true reward function, which is… does that even exist? To the extent that it does, it’s incredibly complicated. It has to account for all of our preferences over the entire future. We should really think about this as just a signal for learning and not as the goal. We should never actually say, “I really want to optimize this reward function.” Maybe that’s fine in a very constricted sense when you’re operating within a narrow environment and you’re able to keep the agent operating within that narrow environment. That’s the takeaway.
Michaël: I feel like it’s pretty close to one of the papers where they have a performance metric and a reward metric. They just have different rewards but they have different metrics and they selected the curves going up or down.
David: That’s more empirical though. There’s been a lot of discussion and a decent amount of empirical work on this but we were trying to approach it theoretically and so actually define it, explore the properties of the definition. And like I said, it would’ve been great if we found out that these things exist. And I think there’s a world that I was imagining we might live in where it’s actually, here are the ways that you can interpolate between this reward function that expresses all of your preferences about everything in fine-grained detail.
David: And then there’s this one that expresses no preferences about anything. And so you can say this reward function only really expresses my preferences about this narrow set of behaviors and I don’t really care about behaviors outside of that. And in a sense, maybe you can have a reward function like that but it supports this line of thinking from the existential safety community where if you leave things out of the reward function, then they might be set to extreme values. The agent will just continue to view them as instrumentally valuable, even if you haven’t specified any terminal value for them. This approach doesn’t really seem promising. And if we want to keep using reward functions, we need to just think about them as a hack that we need to find some other way of dealing with. Or maybe you can strengthen the definition somehow or tweak it somehow and get some more interesting results other than just the negative results we have. Or you can restrict your policy space and just only consider a finite number of policies, then you can at least find non-hackable, non-trivial pairs of reward functions. We don’t really know much more than that based on the results of this paper. So as a first step, you could do a lot more theory. ⬆
Looking Forward
The Poker Win That Never Was
Michaël: Ethan Caballero asked on Twitter, what is it like to play poker with Ethan Caballero? What do you think about it?
David: We played poker back in the day and at one point, he came in and was like, “Oh man, COVID, why are we still here playing poker or something? We have to tell everyone, get the word out.” That was before when people were still saying, wash your hands and it’s probably not even going to be a thing. But yeah, I guess, what else? Maximum entropy is what he said he was doing but I have no idea what he was actually doing.
Michaël: Did he win?
David: I’m not sure. I think he would like you to believe that he won more than average.
Michaël: Okay. Because what Irina told me, there was legends of him winning every round.
David: Yeah, I think that’s bullshit. This is building the legend, right? ⬆
Existential Risk Is Not Taken Seriously Because Of The Availability Heuristic
Michaël: You were also a legend at Mila. So I went to Mila and asked random researchers, “Hey, what do you think of alignment? What do you think of existential risks from AI?.” And people knew you. There was this guy, Breandan, who told me he remembered you. But most of them didn’t care about alignment at all. So as a AI alignment researcher, did you fail your job to spread the message?
David: I don’t think so. I mean, I spread the message. It’s just like, do people want to hear it? And what do they do when they do? It’s been surprising to me how this has happened. There’s been a lot of progress in terms of people understanding existential safety and taking it seriously but I keep thinking the progress will be a little bit faster than it is. I’m not sure what’s up with that but I have a bunch of theories. But I don’t know, I don’t feel like getting into them, necessarily.
Michaël: We have an hour or two, please?
David: I mean the thing is it’s just kind of speculation. Ok, well one thing recently that somebody pointed out to me that maybe I’ve heard this before but it really just struck home. The availability heuristic is this idea that you estimate the probability of something by how readily you can conjure it to mind. And I think the ‘out of control AI takes over the world and kills everybody scenario’, there’s no version of that that I can think of, that doesn’t seem kind of wild and implausible in some of the details. And that doesn’t stop me from taking it seriously. But I can see why a lot of people would, if this is how they are thinking about it. They’re just like, “Well how would that even happen?” And that’s something that people say a lot is like, “So what? It’s going to build nanobots? That sounds like bullshit.” Or, “Robots don’t work so it’s going to have to solve robotics?” And we’re like, “It’s somehow going to do that overnight or something,” which obviously doesn’t have to happen overnight. And what about the future world where we have robots because it’s not like we’re never going to build robots but I digress.
Michaël: Do you think an AI takeover or a strategic advantage from AI will come after we build robots?
David: I don’t know. I think all these details are just “who knows?”
Timeline? Pretty Soon…
Michaël: I want to ask a question, that maybe might be at the beginning or maybe at the end of the recording, but I have not asked enough. What are your timelines?
David: Wait, wait, wait. We talked about this.
Michaël: Yeah, but you haven’t given us an actual distribution, or you’ve said you have a distribution, but when do you expect recursive self improvement, or general human level AI, or whatever you want to define?
David: I don’t know. Pretty soon, maybe.
Michaël: Pretty soon. What’s pretty soon? In your lifetime?
David: I think I’d be pretty surprised if we don’t have AGI in my lifetime.
Michaël: What’s your median years for AGI?
David: This conversation is over.
Michaël: Okay. I think that’s a good ending. ⬆